 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA unifying tutorial on Approximate Message Passing
May 05, 2021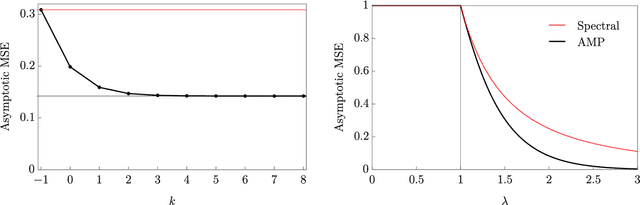
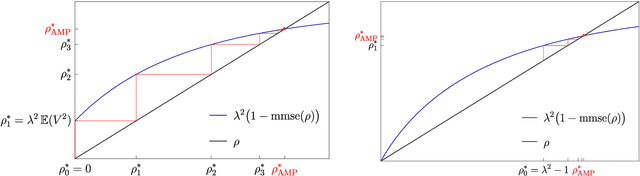
Over the last decade or so, Approximate Message Passing (AMP) algorithms have become extremely popular in various structured high-dimensional statistical problems. The fact that the origins of these techniques can be traced back to notions of belief propagation in the statistical physics literature lends a certain mystique to the area for many statisticians. Our goal in this work is to present the main ideas of AMP from a statistical perspective, to illustrate the power and flexibility of the AMP framework. Along the way, we strengthen and unify many of the results in the existing literature.
USP: an independence test that improves on Pearson's chi-squared and the $G$-test
Jan 26, 2021
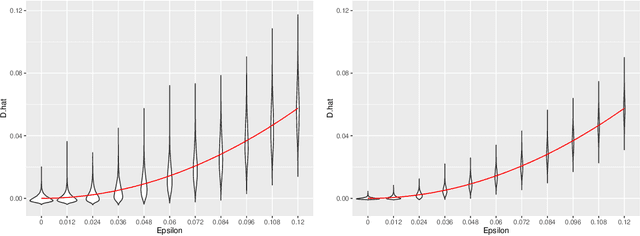

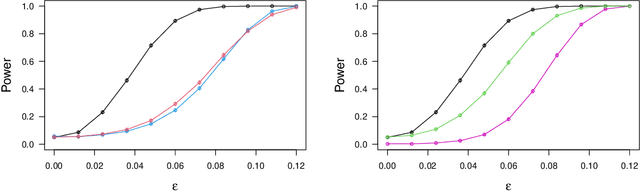
We present the $U$-Statistic Permutation (USP) test of independence in the context of discrete data displayed in a contingency table. Either Pearson's chi-squared test of independence, or the $G$-test, are typically used for this task, but we argue that these tests have serious deficiencies, both in terms of their inability to control the size of the test, and their power properties. By contrast, the USP test is guaranteed to control the size of the test at the nominal level for all sample sizes, has no issues with small (or zero) cell counts, and is able to detect distributions that violate independence in only a minimal way. The test statistic is derived from a $U$-statistic estimator of a natural population measure of dependence, and we prove that this is the unique minimum variance unbiased estimator of this population quantity. The practical utility of the USP test is demonstrated on both simulated data, where its power can be dramatically greater than those of Pearson's test and the $G$-test, and on real data. The USP test is implemented in the R package USP.
Isotonic regression with unknown permutations: Statistics, computation, and adaptation
Sep 05, 2020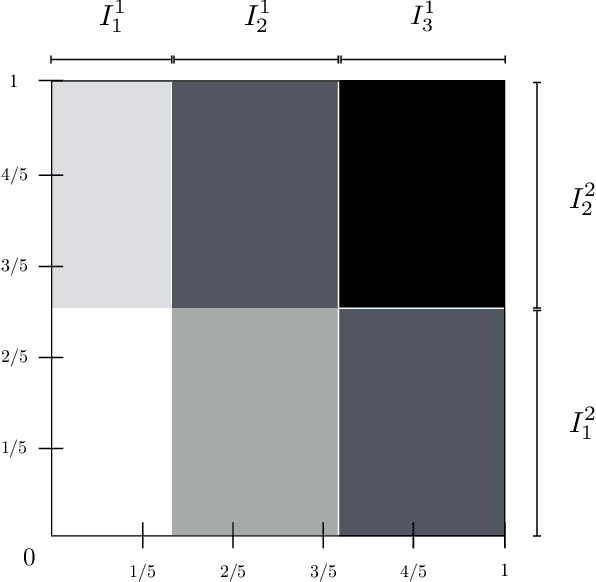
Motivated by models for multiway comparison data, we consider the problem of estimating a coordinate-wise isotonic function on the domain $[0, 1]^d$ from noisy observations collected on a uniform lattice, but where the design points have been permuted along each dimension. While the univariate and bivariate versions of this problem have received significant attention, our focus is on the multivariate case $d \geq 3$. We study both the minimax risk of estimation (in empirical $L_2$ loss) and the fundamental limits of adaptation (quantified by the adaptivity index) to a family of piecewise constant functions. We provide a computationally efficient Mirsky partition estimator that is minimax optimal while also achieving the smallest adaptivity index possible for polynomial time procedures. Thus, from a worst-case perspective and in sharp contrast to the bivariate case, the latent permutations in the model do not introduce significant computational difficulties over and above vanilla isotonic regression. On the other hand, the fundamental limits of adaptation are significantly different with and without unknown permutations: Assuming a hardness conjecture from average-case complexity theory, a statistical-computational gap manifests in the former case. In a complementary direction, we show that natural modifications of existing estimators fail to satisfy at least one of the desiderata of optimal worst-case statistical performance, computational efficiency, and fast adaptation. Along the way to showing our results, we improve adaptation results in the special case $d = 2$ and establish some properties of estimators for vanilla isotonic regression, both of which may be of independent interest.
High-dimensional, multiscale online changepoint detection
Mar 07, 2020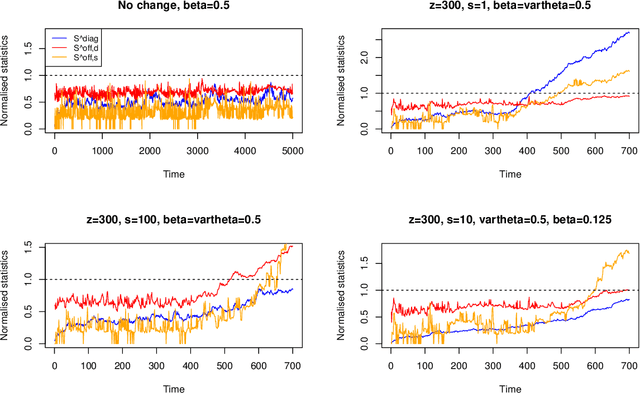
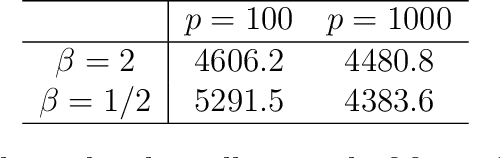
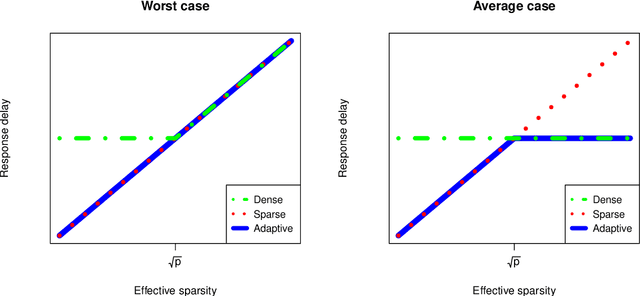
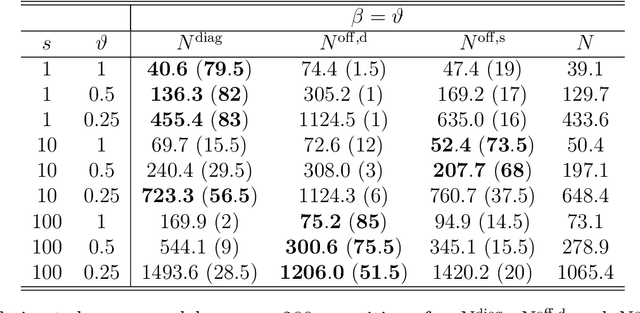
We introduce a new method for high-dimensional, online changepoint detection in settings where a $p$-variate Gaussian data stream may undergo a change in mean. The procedure works by performing likelihood ratio tests against simple alternatives of different scales in each coordinate, and then aggregating test statistics across scales and coordinates. The algorithm is online in the sense that its worst-case computational complexity per new observation, namely $O\bigl(p^2 \log (ep)\bigr)$, is independent of the number of previous observations; in practice, it may even be significantly faster than this. We prove that the patience, or average run length under the null, of our procedure is at least at the desired nominal level, and provide guarantees on its response delay under the alternative that depend on the sparsity of the vector of mean change. Simulations confirm the practical effectiveness of our proposal.
Optimal rates for independence testing via $U$-statistic permutation tests
Jan 15, 2020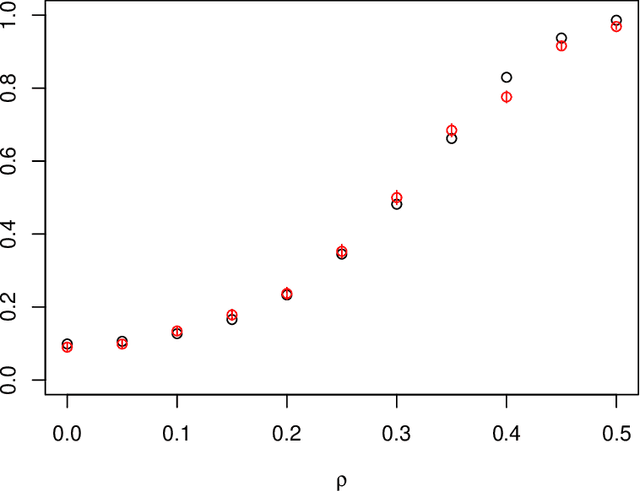
We study the problem of independence testing given independent and identically distributed pairs taking values in a $\sigma$-finite, separable measure space. Defining a natural measure of dependence $D(f)$ as the squared $L_2$-distance between a joint density $f$ and the product of its marginals, we first show that there is no valid test of independence that is uniformly consistent against alternatives of the form $\{f: D(f) \geq \rho^2 \}$. We therefore restrict attention to alternatives that impose additional Sobolev-type smoothness constraints, and define a permutation test based on a basis expansion and a $U$-statistic estimator of $D(f)$ that we prove is minimax optimal in terms of its separation rates in many instances. Finally, for the case of a Fourier basis on $[0,1]^2$, we provide an approximation to the power function that offers several additional insights.
Efficient two-sample functional estimation and the super-oracle phenomenon
Apr 18, 2019We consider the estimation of two-sample integral functionals, of the type that occur naturally, for example, when the object of interest is a divergence between unknown probability densities. Our first main result is that, in wide generality, a weighted nearest neighbour estimator is efficient, in the sense of achieving the local asymptotic minimax lower bound. Moreover, we also prove a corresponding central limit theorem, which facilitates the construction of asymptotically valid confidence intervals for the functional, having asymptotically minimal width. One interesting consequence of our results is the discovery that, for certain functionals, the worst-case performance of our estimator may improve on that of the natural `oracle' estimator, which is given access to the values of the unknown densities at the observations.
Classification with imperfect training labels
Sep 26, 2018



We study the effect of imperfect training data labels on the performance of classification methods. In a general setting, where the probability that an observation in the training dataset is mislabelled may depend on both the feature vector and the true label, we bound the excess risk of an arbitrary classifier trained with imperfect labels in terms of its excess risk for predicting a noisy label. This reveals conditions under which a classifier trained with imperfect labels remains consistent for classifying uncorrupted test data points. Furthermore, under stronger conditions, we derive detailed asymptotic properties for the popular $k$-nearest neighbour ($k$nn), support vector machine (SVM) and linear discriminant analysis (LDA) classifiers. One consequence of these results is that the knn and SVM classifiers are robust to imperfect training labels, in the sense that the rate of convergence of the excess risks of these classifiers remains unchanged; in fact, our theoretical and empirical results even show that in some cases, imperfect labels may improve the performance of these methods. On the other hand, the LDA classifier is shown to be typically inconsistent in the presence of label noise unless the prior probabilities of each class are equal. Our theoretical results are supported by a simulation study.
Local nearest neighbour classification with applications to semi-supervised learning
Aug 24, 2018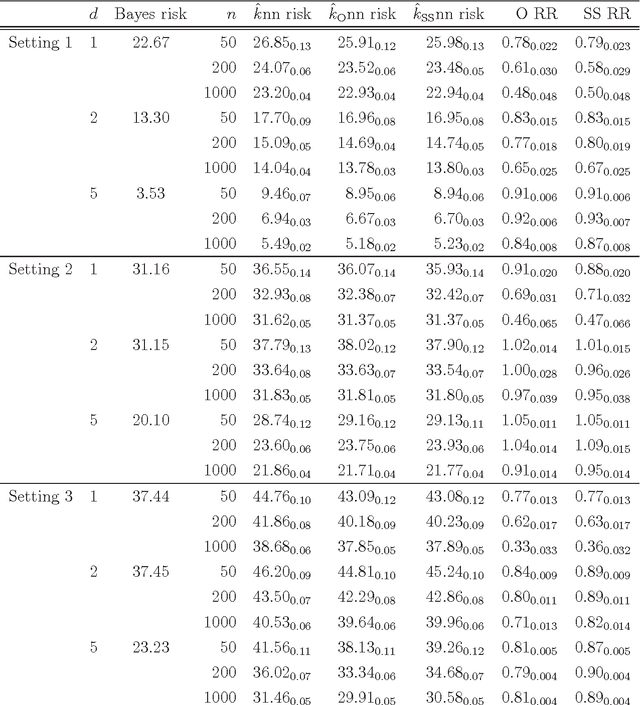
We derive a new asymptotic expansion for the global excess risk of a local $k$-nearest neighbour classifier, where the choice of $k$ may depend upon the test point. This expansion elucidates conditions under which the dominant contribution to the excess risk comes from the locus of points at which each class label is equally likely to occur, but we also show that if these conditions are not satisfied, the dominant contribution may arise from the tails of the marginal distribution of the features. Moreover, we prove that, provided the $d$-dimensional marginal distribution of the features has a finite $\rho$th moment for some $\rho > 4$ (as well as other regularity conditions), a local choice of $k$ can yield a rate of convergence of the excess risk of $O(n^{-4/(d+4)})$, where $n$ is the sample size, whereas for the standard $k$-nearest neighbour classifier, our theory would require $d \geq 5$ and $\rho > 4d/(d-4)$ finite moments to achieve this rate. Our results motivate a new $k$-nearest neighbour classifier for semi-supervised learning problems, where the unlabelled data are used to obtain an estimate of the marginal feature density, and fewer neighbours are used for classification when this density estimate is small. The potential improvements over the standard $k$-nearest neighbour classifier are illustrated both through our theory and via a simulation study.
Sparse principal component analysis via random projections
Jul 24, 2018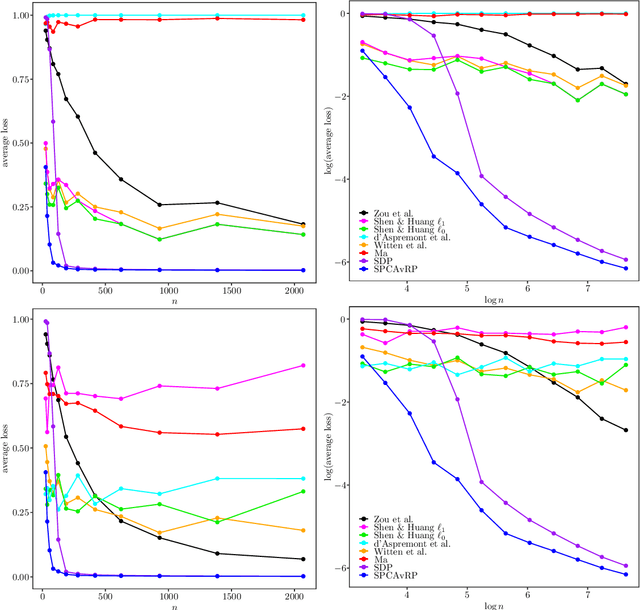
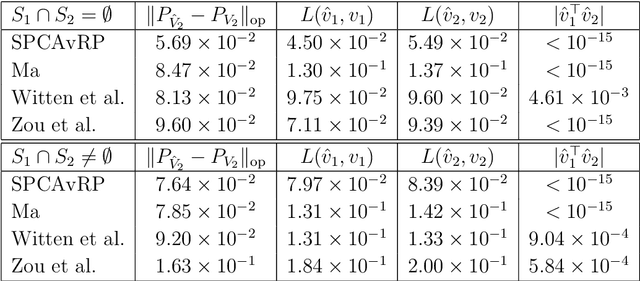
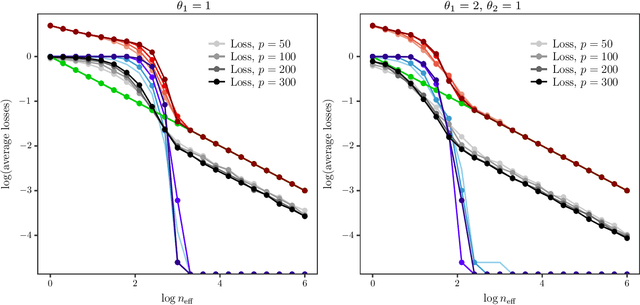
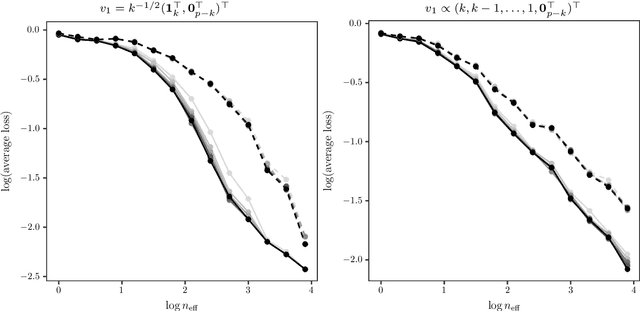
We introduce a new method for sparse principal component analysis, based on the aggregation of eigenvector information from carefully-selected random projections of the sample covariance matrix. Unlike most alternative approaches, our algorithm is non-iterative, so is not vulnerable to a bad choice of initialisation. Our theory provides great detail on the statistical and computational trade-off in our procedure, revealing a subtle interplay between the effective sample size and the number of random projections that are required to achieve the minimax optimal rate. Numerical studies provide further insight into the procedure and confirm its highly competitive finite-sample performance.
Nonparametric independence testing via mutual information
Nov 17, 2017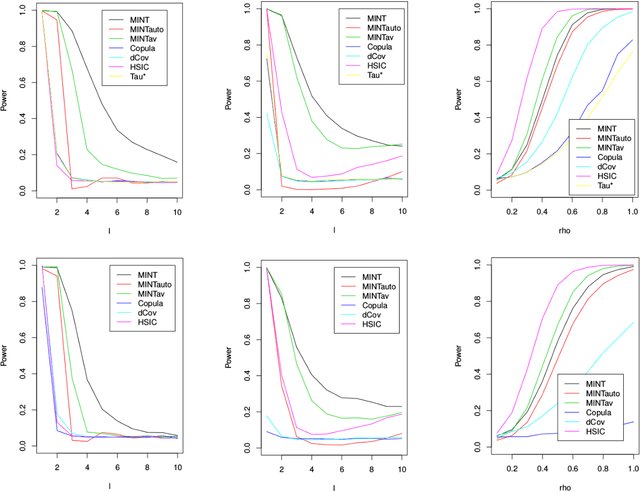
We propose a test of independence of two multivariate random vectors, given a sample from the underlying population. Our approach, which we call MINT, is based on the estimation of mutual information, whose decomposition into joint and marginal entropies facilitates the use of recently-developed efficient entropy estimators derived from nearest neighbour distances. The proposed critical values, which may be obtained from simulation (in the case where one marginal is known) or resampling, guarantee that the test has nominal size, and we provide local power analyses, uniformly over classes of densities whose mutual information satisfies a lower bound. Our ideas may be extended to provide a new goodness-of-fit tests of normal linear models based on assessing the independence of our vector of covariates and an appropriately-defined notion of an error vector. The theory is supported by numerical studies on both simulated and real data.