 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Sources and Sinks in the Presence of Multiple Agents with Gaussian Process Vector Calculus
Feb 22, 2018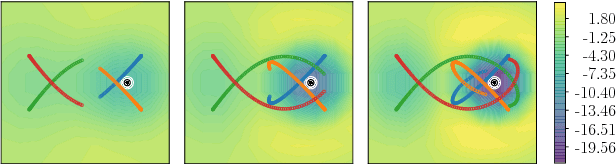
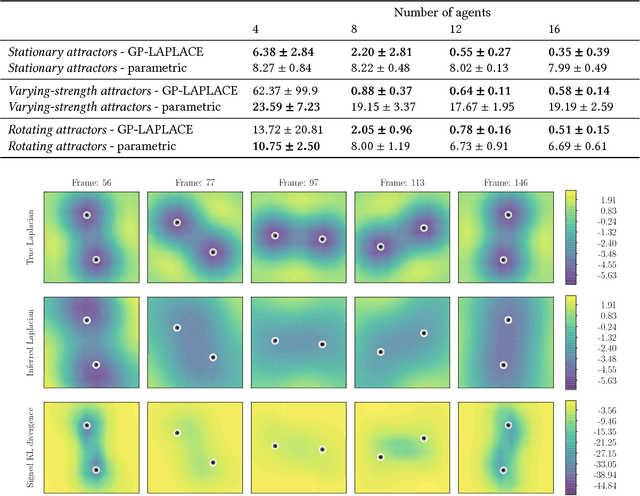
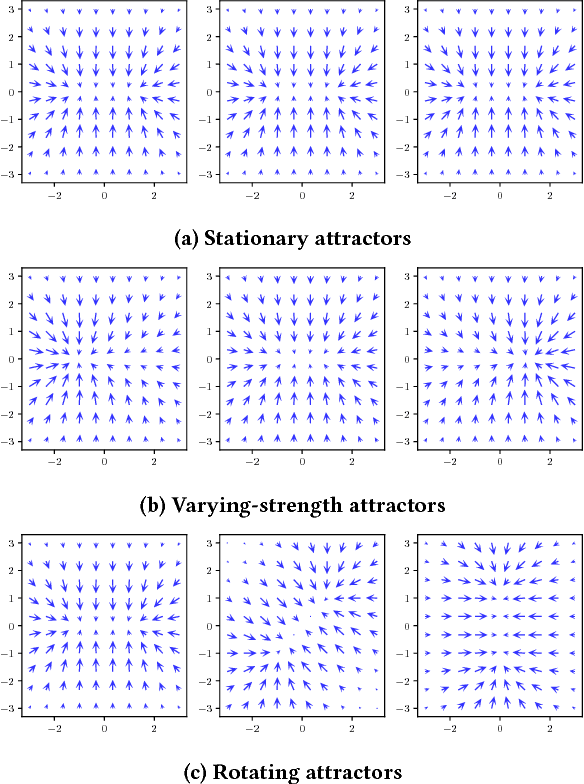
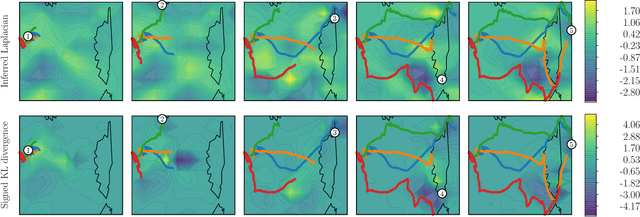
In systems of multiple agents, identifying the cause of observed agent dynamics is challenging. Often, these agents operate in diverse, non-stationary environments, where models rely on hand-crafted environment-specific features to infer influential regions in the system's surroundings. To overcome the limitations of these inflexible models, we present GP-LAPLACE, a technique for locating sources and sinks from trajectories in time-varying fields. Using Gaussian processes, we jointly infer a spatio-temporal vector field, as well as canonical vector calculus operations on that field. Notably, we do this from only agent trajectories without requiring knowledge of the environment, and also obtain a metric for denoting the significance of inferred causal features in the environment by exploiting our probabilistic method. To evaluate our approach, we apply it to both synthetic and real-world GPS data, demonstrating the applicability of our technique in the presence of multiple agents, as well as its superiority over existing methods.
Inferring agent objectives at different scales of a complex adaptive system
Dec 04, 2017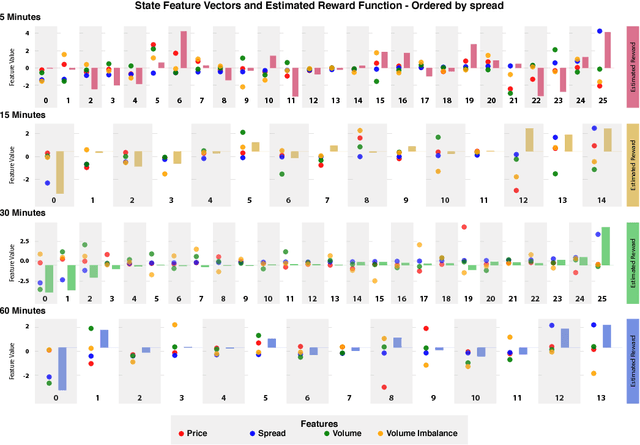
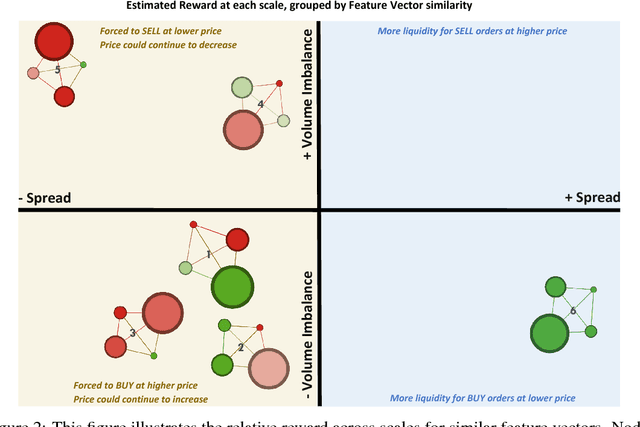
We introduce a framework to study the effective objectives at different time scales of financial market microstructure. The financial market can be regarded as a complex adaptive system, where purposeful agents collectively and simultaneously create and perceive their environment as they interact with it. It has been suggested that multiple agent classes operate in this system, with a non-trivial hierarchy of top-down and bottom-up causation classes with different effective models governing each level. We conjecture that agent classes may in fact operate at different time scales and thus act differently in response to the same perceived market state. Given scale-specific temporal state trajectories and action sequences estimated from aggregate market behaviour, we use Inverse Reinforcement Learning to compute the effective reward function for the aggregate agent class at each scale, allowing us to assess the relative attractiveness of feature vectors across different scales. Differences in reward functions for feature vectors may indicate different objectives of market participants, which could assist in finding the scale boundary for agent classes. This has implications for learning algorithms operating in this domain.