 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning an Interpretable Model for Driver Behavior Prediction with Inductive Biases
Jul 31, 2022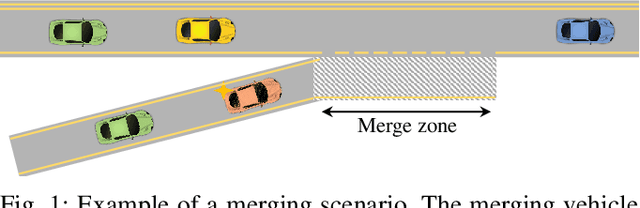
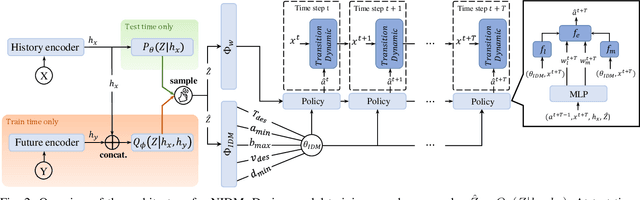
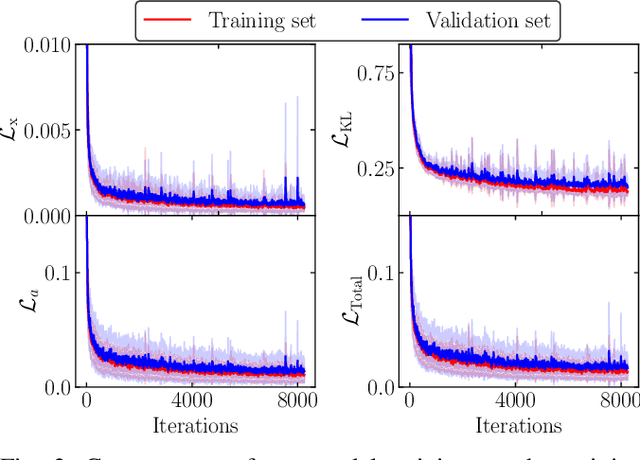
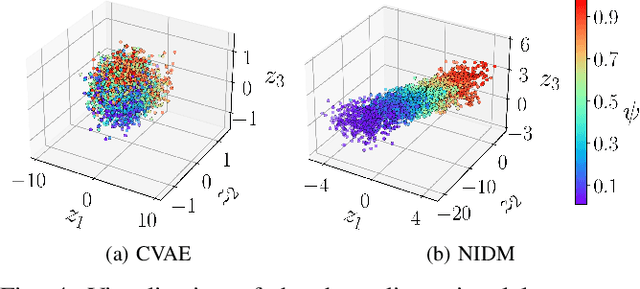
To plan safe maneuvers and act with foresight, autonomous vehicles must be capable of accurately predicting the uncertain future. In the context of autonomous driving, deep neural networks have been successfully applied to learning predictive models of human driving behavior from data. However, the predictions suffer from cascading errors, resulting in large inaccuracies over long time horizons. Furthermore, the learned models are black boxes, and thus it is often unclear how they arrive at their predictions. In contrast, rule-based models, which are informed by human experts, maintain long-term coherence in their predictions and are human-interpretable. However, such models often lack the sufficient expressiveness needed to capture complex real-world dynamics. In this work, we begin to close this gap by embedding the Intelligent Driver Model, a popular hand-crafted driver model, into deep neural networks. Our model's transparency can offer considerable advantages, e.g., in debugging the model and more easily interpreting its predictions. We evaluate our approach on a simulated merging scenario, showing that it yields a robust model that is end-to-end trainable and provides greater transparency at no cost to the model's predictive accuracy.
AFT-VO: Asynchronous Fusion Transformers for Multi-View Visual Odometry Estimation
Jun 26, 2022Motion estimation approaches typically employ sensor fusion techniques, such as the Kalman Filter, to handle individual sensor failures. More recently, deep learning-based fusion approaches have been proposed, increasing the performance and requiring less model-specific implementations. However, current deep fusion approaches often assume that sensors are synchronised, which is not always practical, especially for low-cost hardware. To address this limitation, in this work, we propose AFT-VO, a novel transformer-based sensor fusion architecture to estimate VO from multiple sensors. Our framework combines predictions from asynchronous multi-view cameras and accounts for the time discrepancies of measurements coming from different sources. Our approach first employs a Mixture Density Network (MDN) to estimate the probability distributions of the 6-DoF poses for every camera in the system. Then a novel transformer-based fusion module, AFT-VO, is introduced, which combines these asynchronous pose estimations, along with their confidences. More specifically, we introduce Discretiser and Source Encoding techniques which enable the fusion of multi-source asynchronous signals. We evaluate our approach on the popular nuScenes and KITTI datasets. Our experiments demonstrate that multi-view fusion for VO estimation provides robust and accurate trajectories, outperforming the state of the art in both challenging weather and lighting conditions.
Medusa: Universal Feature Learning via Attentional Multitasking
Apr 12, 2022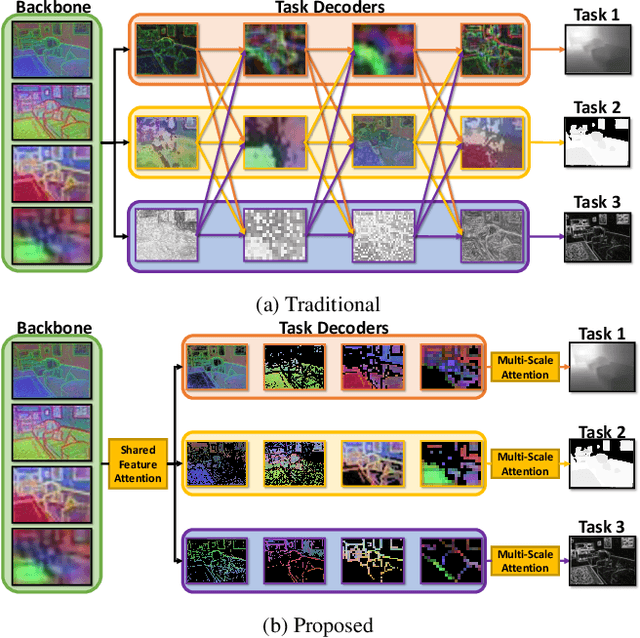
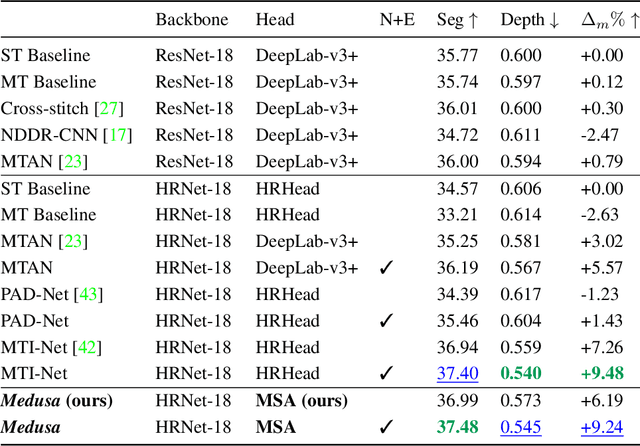
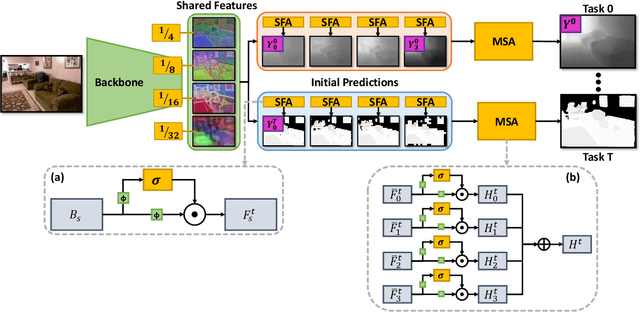
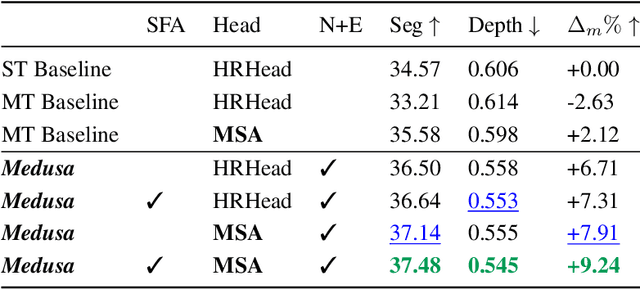
Recent approaches to multi-task learning (MTL) have focused on modelling connections between tasks at the decoder level. This leads to a tight coupling between tasks, which need retraining if a new task is inserted or removed. We argue that MTL is a stepping stone towards universal feature learning (UFL), which is the ability to learn generic features that can be applied to new tasks without retraining. We propose Medusa to realize this goal, designing task heads with dual attention mechanisms. The shared feature attention masks relevant backbone features for each task, allowing it to learn a generic representation. Meanwhile, a novel Multi-Scale Attention head allows the network to better combine per-task features from different scales when making the final prediction. We show the effectiveness of Medusa in UFL (+13.18% improvement), while maintaining MTL performance and being 25% more efficient than previous approaches.
"The Pedestrian next to the Lamppost" Adaptive Object Graphs for Better Instantaneous Mapping
Apr 06, 2022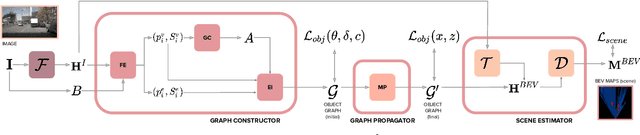

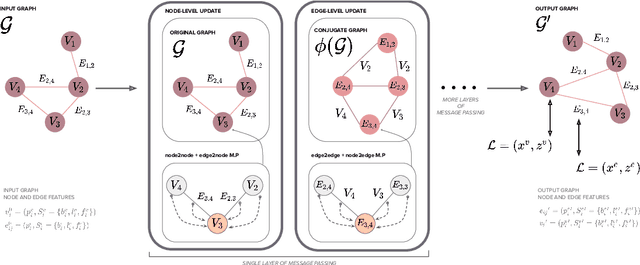

Estimating a semantically segmented bird's-eye-view (BEV) map from a single image has become a popular technique for autonomous control and navigation. However, they show an increase in localization error with distance from the camera. While such an increase in error is entirely expected - localization is harder at distance - much of the drop in performance can be attributed to the cues used by current texture-based models, in particular, they make heavy use of object-ground intersections (such as shadows), which become increasingly sparse and uncertain for distant objects. In this work, we address these shortcomings in BEV-mapping by learning the spatial relationship between objects in a scene. We propose a graph neural network which predicts BEV objects from a monocular image by spatially reasoning about an object within the context of other objects. Our approach sets a new state-of-the-art in BEV estimation from monocular images across three large-scale datasets, including a 50% relative improvement for objects on nuScenes.
Signing at Scale: Learning to Co-Articulate Signs for Large-Scale Photo-Realistic Sign Language Production
Mar 29, 2022
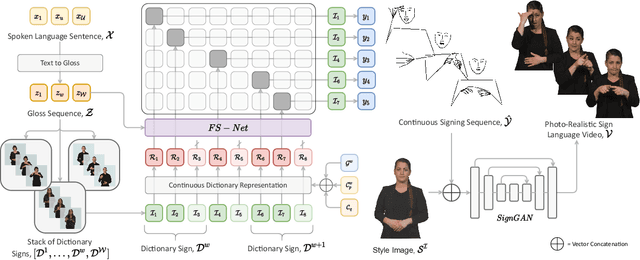
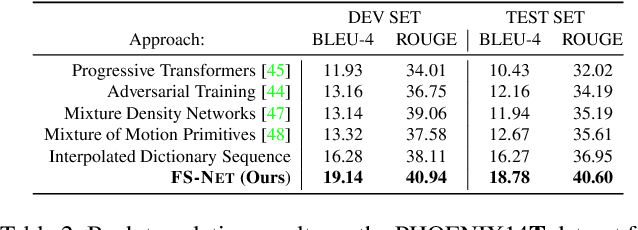
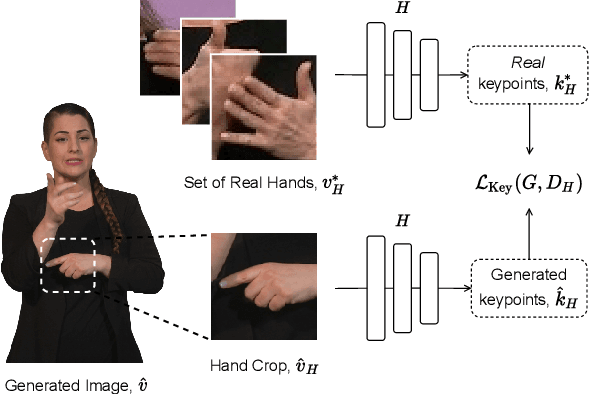
Sign languages are visual languages, with vocabularies as rich as their spoken language counterparts. However, current deep-learning based Sign Language Production (SLP) models produce under-articulated skeleton pose sequences from constrained vocabularies and this limits applicability. To be understandable and accepted by the deaf, an automatic SLP system must be able to generate co-articulated photo-realistic signing sequences for large domains of discourse. In this work, we tackle large-scale SLP by learning to co-articulate between dictionary signs, a method capable of producing smooth signing while scaling to unconstrained domains of discourse. To learn sign co-articulation, we propose a novel Frame Selection Network (FS-Net) that improves the temporal alignment of interpolated dictionary signs to continuous signing sequences. Additionally, we propose SignGAN, a pose-conditioned human synthesis model that produces photo-realistic sign language videos direct from skeleton pose. We propose a novel keypoint-based loss function which improves the quality of synthesized hand images. We evaluate our SLP model on the large-scale meineDGS (mDGS) corpus, conducting extensive user evaluation showing our FS-Net approach improves co-articulation of interpolated dictionary signs. Additionally, we show that SignGAN significantly outperforms all baseline methods for quantitative metrics, human perceptual studies and native deaf signer comprehension.
A Free Lunch with Influence Functions? Improving Neural Network Estimates with Concepts from Semiparametric Statistics
Feb 18, 2022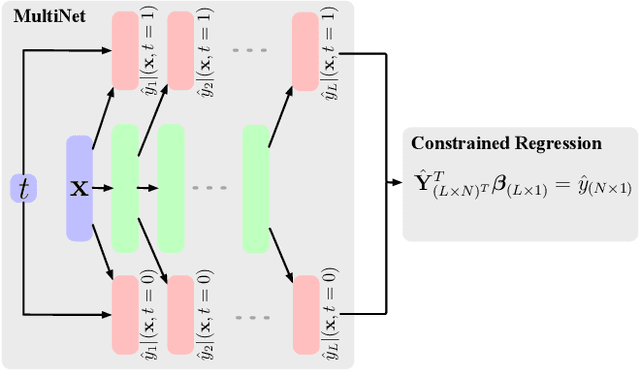
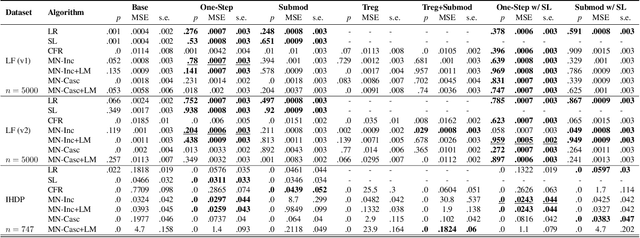
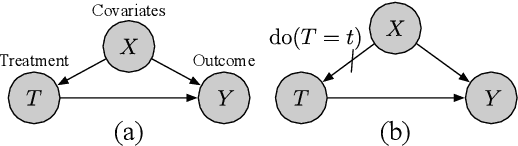
Parameter estimation in the empirical fields is usually undertaken using parametric models, and such models are convenient because they readily facilitate statistical inference. Unfortunately, they are unlikely to have a sufficiently flexible functional form to be able to adequately model real-world phenomena, and their usage may therefore result in biased estimates and invalid inference. Unfortunately, whilst non-parametric machine learning models may provide the needed flexibility to adapt to the complexity of real-world phenomena, they do not readily facilitate statistical inference, and may still exhibit residual bias. We explore the potential for semiparametric theory (in particular, the Influence Function) to be used to improve neural networks and machine learning algorithms in terms of (a) improving initial estimates without needing more data (b) increasing the robustness of our models, and (c) yielding confidence intervals for statistical inference. We propose a new neural network method MultiNet, which seeks the flexibility and diversity of an ensemble using a single architecture. Results on causal inference tasks indicate that MultiNet yields better performance than other approaches, and that all considered methods are amenable to improvement from semiparametric techniques under certain conditions. In other words, with these techniques we show that we can improve existing neural networks for `free', without needing more data, and without needing to retrain them. Finally, we provide the expression for deriving influence functions for estimands from a general graph, and the code to do so automatically.
Multi-Camera Sensor Fusion for Visual Odometry using Deep Uncertainty Estimation
Dec 23, 2021Visual Odometry (VO) estimation is an important source of information for vehicle state estimation and autonomous driving. Recently, deep learning based approaches have begun to appear in the literature. However, in the context of driving, single sensor based approaches are often prone to failure because of degraded image quality due to environmental factors, camera placement, etc. To address this issue, we propose a deep sensor fusion framework which estimates vehicle motion using both pose and uncertainty estimations from multiple on-board cameras. We extract spatio-temporal feature representations from a set of consecutive images using a hybrid CNN - RNN model. We then utilise a Mixture Density Network (MDN) to estimate the 6-DoF pose as a mixture of distributions and a fusion module to estimate the final pose using MDN outputs from multi-cameras. We evaluate our approach on the publicly available, large scale autonomous vehicle dataset, nuScenes. The results show that the proposed fusion approach surpasses the state-of-the-art, and provides robust estimates and accurate trajectories compared to individual camera-based estimations.
MDN-VO: Estimating Visual Odometry with Confidence
Dec 23, 2021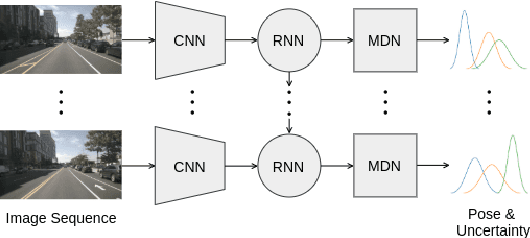
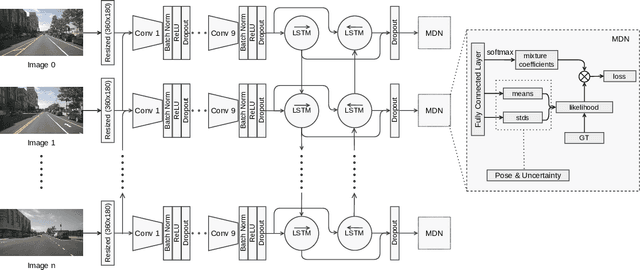
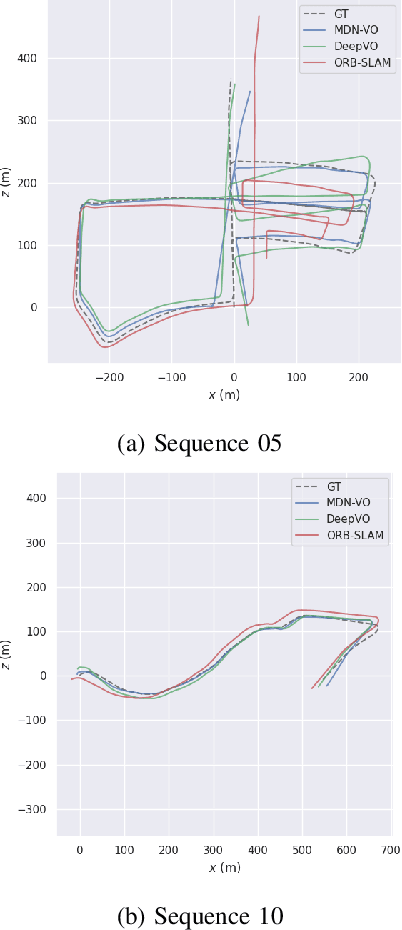
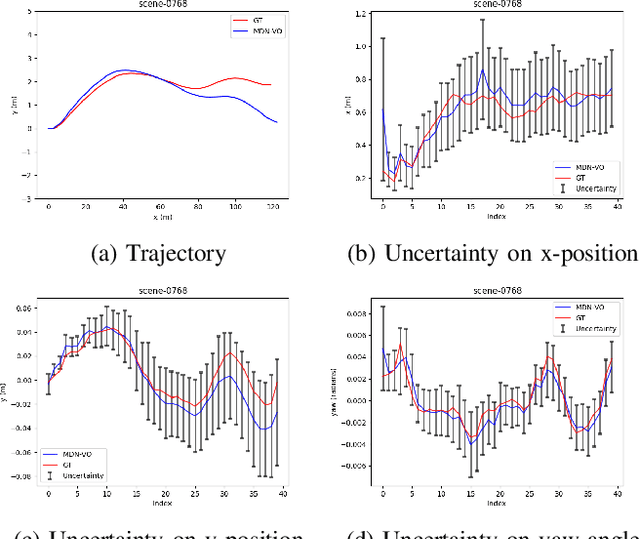
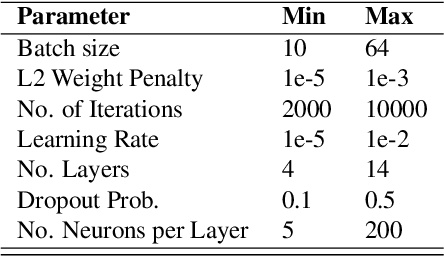
Visual Odometry (VO) is used in many applications including robotics and autonomous systems. However, traditional approaches based on feature matching are computationally expensive and do not directly address failure cases, instead relying on heuristic methods to detect failure. In this work, we propose a deep learning-based VO model to efficiently estimate 6-DoF poses, as well as a confidence model for these estimates. We utilise a CNN - RNN hybrid model to learn feature representations from image sequences. We then employ a Mixture Density Network (MDN) which estimates camera motion as a mixture of Gaussians, based on the extracted spatio-temporal representations. Our model uses pose labels as a source of supervision, but derives uncertainties in an unsupervised manner. We evaluate the proposed model on the KITTI and nuScenes datasets and report extensive quantitative and qualitative results to analyse the performance of both pose and uncertainty estimation. Our experiments show that the proposed model exceeds state-of-the-art performance in addition to detecting failure cases using the predicted pose uncertainty.
Skeletal Graph Self-Attention: Embedding a Skeleton Inductive Bias into Sign Language Production
Dec 06, 2021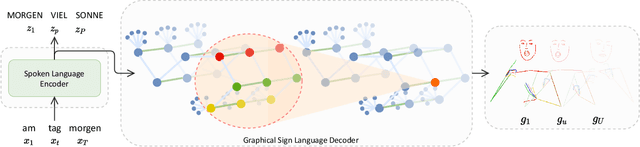
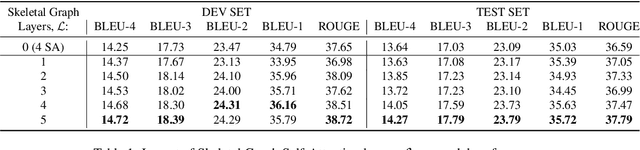
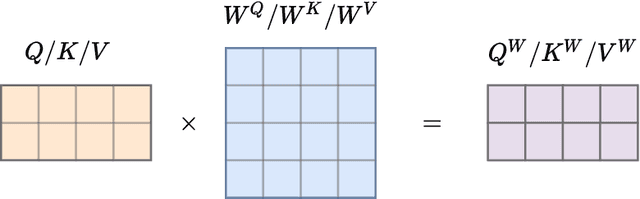
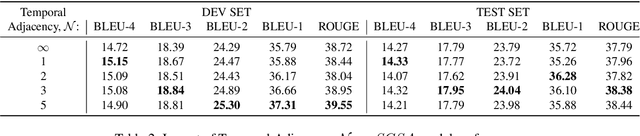
Recent approaches to Sign Language Production (SLP) have adopted spoken language Neural Machine Translation (NMT) architectures, applied without sign-specific modifications. In addition, these works represent sign language as a sequence of skeleton pose vectors, projected to an abstract representation with no inherent skeletal structure. In this paper, we represent sign language sequences as a skeletal graph structure, with joints as nodes and both spatial and temporal connections as edges. To operate on this graphical structure, we propose Skeletal Graph Self-Attention (SGSA), a novel graphical attention layer that embeds a skeleton inductive bias into the SLP model. Retaining the skeletal feature representation throughout, we directly apply a spatio-temporal adjacency matrix into the self-attention formulation. This provides structure and context to each skeletal joint that is not possible when using a non-graphical abstract representation, enabling fluid and expressive sign language production. We evaluate our Skeletal Graph Self-Attention architecture on the challenging RWTH-PHOENIX-Weather-2014T(PHOENIX14T) dataset, achieving state-of-the-art back translation performance with an 8% and 7% improvement over competing methods for the dev and test sets.
Human Pose Manipulation and Novel View Synthesis using Differentiable Rendering
Nov 24, 2021



We present a new approach for synthesizing novel views of people in new poses. Our novel differentiable renderer enables the synthesis of highly realistic images from any viewpoint. Rather than operating over mesh-based structures, our renderer makes use of diffuse Gaussian primitives that directly represent the underlying skeletal structure of a human. Rendering these primitives gives results in a high-dimensional latent image, which is then transformed into an RGB image by a decoder network. The formulation gives rise to a fully differentiable framework that can be trained end-to-end. We demonstrate the effectiveness of our approach to image reconstruction on both the Human3.6M and Panoptic Studio datasets. We show how our approach can be used for motion transfer between individuals; novel view synthesis of individuals captured from just a single camera; to synthesize individuals from any virtual viewpoint; and to re-render people in novel poses. Code and video results are available at https://github.com/GuillaumeRochette/HumanViewSynthesis.