 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymphony: A Heuristic Normalized Calibrated Advantage Actor and Critic Algorithm in application for Humanoid Robots
Dec 18, 2025In our work we not explicitly hint that it is a misconception to think that humans learn fast. Learning process takes time. Babies start learning to move in the restricted liquid area called placenta. Children often are limited by underdeveloped body. Even adults are not allowed to participate in complex competitions right away. However, with robots, when learning from scratch, we often don't have the privilege of waiting for dozen millions of steps. "Swaddling" regularization is responsible for restraining an agent in rapid but unstable development penalizing action strength in a specific way not affecting actions directly. The Symphony, Transitional-policy Deterministic Actor and Critic algorithm, is a concise combination of different ideas for possibility of training humanoid robots from scratch with Sample Efficiency, Sample Proximity and Safety of Actions in mind. It is no secret that continuous increase in Gaussian noise without appropriate smoothing is harmful for motors and gearboxes. Compared to Stochastic algorithms, we set a limited parametric noise and promote a reduced strength of actions, safely increasing entropy, since the actions are kind of immersed in weaker noise. When actions require more extreme values, actions rise above the weak noise. Training becomes empirically much safer for both the environment around and the robot's mechanisms. We use Fading Replay Buffer: using a fixed formula containing the hyperbolic tangent, we adjust the batch sampling probability: the memory contains a recent memory and a long-term memory trail. Fading Replay Buffer allows us to use Temporal Advantage when we improve the current Critic Network prediction compared to the exponential moving average. Temporal Advantage allows us to update Actor and Critic in one pass, as well as combine Actor and Critic in one Object and implement their Losses in one line.
Advancing Hungarian Text Processing with HuSpaCy: Efficient and Accurate NLP Pipelines
Aug 24, 2023This paper presents a set of industrial-grade text processing models for Hungarian that achieve near state-of-the-art performance while balancing resource efficiency and accuracy. Models have been implemented in the spaCy framework, extending the HuSpaCy toolkit with several improvements to its architecture. Compared to existing NLP tools for Hungarian, all of our pipelines feature all basic text processing steps including tokenization, sentence-boundary detection, part-of-speech tagging, morphological feature tagging, lemmatization, dependency parsing and named entity recognition with high accuracy and throughput. We thoroughly evaluated the proposed enhancements, compared the pipelines with state-of-the-art tools and demonstrated the competitive performance of the new models in all text preprocessing steps. All experiments are reproducible and the pipelines are freely available under a permissive license.
Hybrid lemmatization in HuSpaCy
Jun 13, 2023



Lemmatization is still not a trivial task for morphologically rich languages. Previous studies showed that hybrid architectures usually work better for these languages and can yield great results. This paper presents a hybrid lemmatizer utilizing both a neural model, dictionaries and hand-crafted rules. We introduce a hybrid architecture along with empirical results on a widely used Hungarian dataset. The presented methods are published as three HuSpaCy models.
HuSpaCy: an industrial-strength Hungarian natural language processing toolkit
Jan 10, 2022
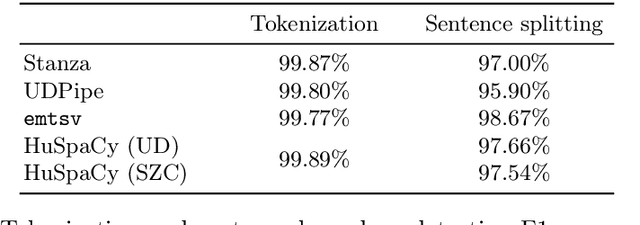
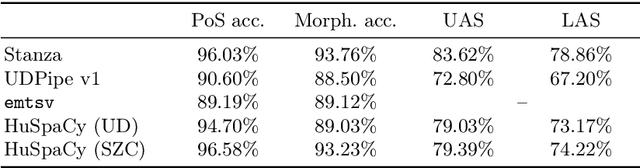
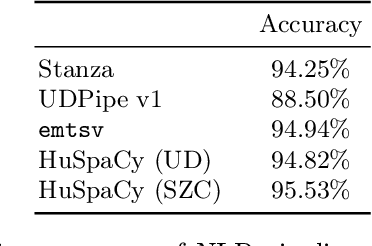
Although there are a couple of open-source language processing pipelines available for Hungarian, none of them satisfies the requirements of today's NLP applications. A language processing pipeline should consist of close to state-of-the-art lemmatization, morphosyntactic analysis, entity recognition and word embeddings. Industrial text processing applications have to satisfy non-functional software quality requirements, what is more, frameworks supporting multiple languages are more and more favored. This paper introduces HuSpaCy, an industry-ready Hungarian language processing toolkit. The presented tool provides components for the most important basic linguistic analysis tasks. It is open-source and is available under a permissive license. Our system is built upon spaCy's NLP components resulting in an easily usable, fast yet accurate application. Experiments confirm that HuSpaCy has high accuracy while maintaining resource-efficient prediction capabilities.