 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Random-Matrix Criterion for Initializing Gated Recurrent Neural Networks
May 11, 2026Proper weight initialization prior to training has historically been one of the key factors that helped kick off the deep learning revolution. Initialization is even more crucial in "reservoir computing", where the weights of a readout layer are learned linearly while the reservoir weights are fixed and largely determine the richness, stability and memory of the resulting dynamics. In the infinite-width limit it has been shown that meaningful initializations are those sitting at an effective critical point of the randomly initialized model. The phase transition is controlled by the weight variance $g^2$ and separates an ordered phase from a chaotic one where information progressively degrades. Here we derive a simple criterion to estimate the critical $g_c$ for a broad class of recurrent architectures and we show that it closely tracks the gain at which a gated-RNN reservoir achieves peak performance on a chaotic forecasting task. Finally, we argue that our criterion can serve as a design principle for future initialization schemes.
Deep Reinforcement Learning for Active High Frequency Trading
Feb 04, 2021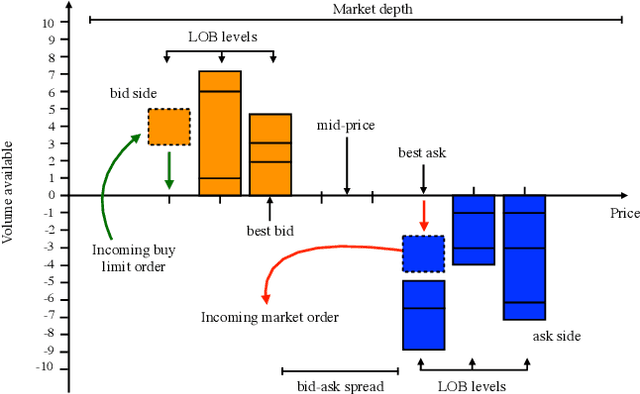
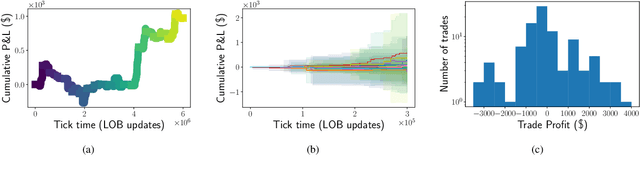
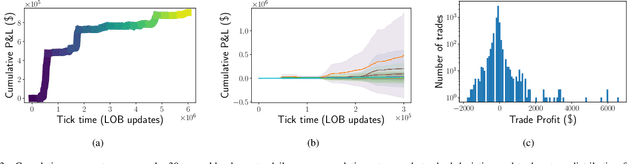
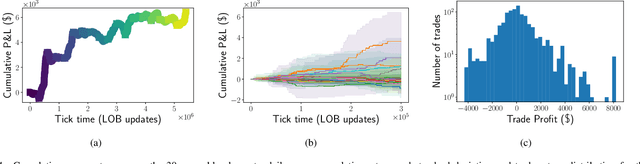
We introduce the first end-to-end Deep Reinforcement Learning (DRL) based framework for active high frequency trading. We train DRL agents to trade one unit of Intel Corporation stock by employing the Proximal Policy Optimization algorithm. The training is performed on three contiguous months of high frequency Limit Order Book data, of which the last month constitutes the validation data. In order to maximise the signal to noise ratio in the training data, we compose the latter by only selecting training samples with largest price changes. The test is then carried out on the following month of data. Hyperparameters are tuned using the Sequential Model Based Optimization technique. We consider three different state characterizations, which differ in their LOB-based meta-features. Analysing the agents' performances on test data, we argue that the agents are able to create a dynamic representation of the underlying environment. They identify occasional regularities present in the data and exploit them to create long-term profitable trading strategies. Indeed, agents learn trading strategies able to produce stable positive returns in spite of the highly stochastic and non-stationary environment.