 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrySQL: text-to-SQL training with retry data for self-correcting query generation
Jul 03, 2025



The text-to-SQL task is an active challenge in Natural Language Processing. Many existing solutions focus on using black-box language models extended with specialized components within customized end-to-end text-to-SQL pipelines. While these solutions use both closed-source proprietary language models and coding-oriented open-source models, there is a lack of research regarding SQL-specific generative models. At the same time, recent advancements in self-correcting generation strategies show promise for improving the capabilities of existing architectures. The application of these concepts to the text-to-SQL task remains unexplored. In this paper, we introduce RetrySQL, a new approach to training text-to-SQL generation models. We prepare reasoning steps for reference SQL queries and then corrupt them to create retry data that contains both incorrect and corrected steps, divided with a special token. We continuously pre-train an open-source coding model with this data and demonstrate that retry steps yield an improvement of up to 4 percentage points in both overall and challenging execution accuracy metrics, compared to pre-training without retry data. Additionally, we confirm that supervised fine-tuning with LoRA is ineffective for learning from retry data and that full-parameter pre-training is a necessary requirement for that task. We showcase that the self-correcting behavior is learned by the model and the increase in downstream accuracy metrics is a result of this additional skill. Finally, we incorporate RetrySQL-trained models into the full text-to-SQL pipeline and showcase that they are competitive in terms of execution accuracy with proprietary models that contain orders of magnitude more parameters. RetrySQL demonstrates that self-correction can be learned in the text-to-SQL task and provides a novel way of improving generation accuracy for SQL-oriented language models.
Interactive Lungs Auscultation with Reinforcement Learning Agent
Jul 25, 2019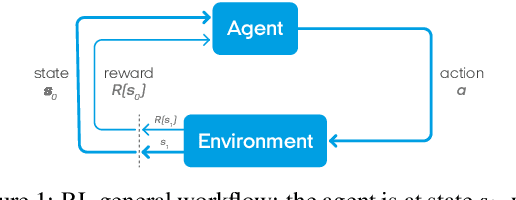

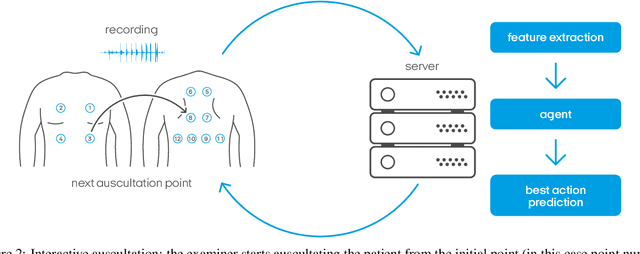
To perform a precise auscultation for the purposes of examination of respiratory system normally requires the presence of an experienced doctor. With most recent advances in machine learning and artificial intelligence, automatic detection of pathological breath phenomena in sounds recorded with stethoscope becomes a reality. But to perform a full auscultation in home environment by layman is another matter, especially if the patient is a child. In this paper we propose a unique application of Reinforcement Learning for training an agent that interactively guides the end user throughout the auscultation procedure. We show that \textit{intelligent} selection of auscultation points by the agent reduces time of the examination fourfold without significant decrease in diagnosis accuracy compared to exhaustive auscultation.