 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Unifying Evaluation of Counterfactual Explanations: Leveraging Large Language Models for Human-Centric Assessments
Oct 28, 2024



As machine learning models evolve, maintaining transparency demands more human-centric explainable AI techniques. Counterfactual explanations, with roots in human reasoning, identify the minimal input changes needed to obtain a given output and, hence, are crucial for supporting decision-making. Despite their importance, the evaluation of these explanations often lacks grounding in user studies and remains fragmented, with existing metrics not fully capturing human perspectives. To address this challenge, we developed a diverse set of 30 counterfactual scenarios and collected ratings across 8 evaluation metrics from 206 respondents. Subsequently, we fine-tuned different Large Language Models (LLMs) to predict average or individual human judgment across these metrics. Our methodology allowed LLMs to achieve an accuracy of up to 63% in zero-shot evaluations and 85% (over a 3-classes prediction) with fine-tuning across all metrics. The fine-tuned models predicting human ratings offer better comparability and scalability in evaluating different counterfactual explanation frameworks.
Exploring Commonalities in Explanation Frameworks: A Multi-Domain Survey Analysis
May 20, 2024



This study presents insights gathered from surveys and discussions with specialists in three domains, aiming to find essential elements for a universal explanation framework that could be applied to these and other similar use cases. The insights are incorporated into a software tool that utilizes GP algorithms, known for their interpretability. The applications analyzed include a medical scenario (involving predictive ML), a retail use case (involving prescriptive ML), and an energy use case (also involving predictive ML). We interviewed professionals from each sector, transcribing their conversations for further analysis. Additionally, experts and non-experts in these fields filled out questionnaires designed to probe various dimensions of explanatory methods. The findings indicate a universal preference for sacrificing a degree of accuracy in favor of greater explainability. Additionally, we highlight the significance of feature importance and counterfactual explanations as critical components of such a framework. Our questionnaires are publicly available to facilitate the dissemination of knowledge in the field of XAI.
Enhancing Counterfactual Explanation Search with Diffusion Distance and Directional Coherence
Apr 19, 2024A pressing issue in the adoption of AI models is the increasing demand for more human-centric explanations of their predictions. To advance towards more human-centric explanations, understanding how humans produce and select explanations has been beneficial. In this work, inspired by insights of human cognition we propose and test the incorporation of two novel biases to enhance the search for effective counterfactual explanations. Central to our methodology is the application of diffusion distance, which emphasizes data connectivity and actionability in the search for feasible counterfactual explanations. In particular, diffusion distance effectively weights more those points that are more interconnected by numerous short-length paths. This approach brings closely connected points nearer to each other, identifying a feasible path between them. We also introduce a directional coherence term that allows the expression of a preference for the alignment between the joint and marginal directional changes in feature space to reach a counterfactual. This term enables the generation of counterfactual explanations that align with a set of marginal predictions based on expectations of how the outcome of the model varies by changing one feature at a time. We evaluate our method, named Coherent Directional Counterfactual Explainer (CoDiCE), and the impact of the two novel biases against existing methods such as DiCE, FACE, Prototypes, and Growing Spheres. Through a series of ablation experiments on both synthetic and real datasets with continuous and mixed-type features, we demonstrate the effectiveness of our method.
COIN: Counterfactual inpainting for weakly supervised semantic segmentation for medical images
Apr 19, 2024Deep learning is dramatically transforming the field of medical imaging and radiology, enabling the identification of pathologies in medical images, including computed tomography (CT) and X-ray scans. However, the performance of deep learning models, particularly in segmentation tasks, is often limited by the need for extensive annotated datasets. To address this challenge, the capabilities of weakly supervised semantic segmentation are explored through the lens of Explainable AI and the generation of counterfactual explanations. The scope of this research is development of a novel counterfactual inpainting approach (COIN) that flips the predicted classification label from abnormal to normal by using a generative model. For instance, if the classifier deems an input medical image X as abnormal, indicating the presence of a pathology, the generative model aims to inpaint the abnormal region, thus reversing the classifier's original prediction label. The approach enables us to produce precise segmentations for pathologies without depending on pre-existing segmentation masks. Crucially, image-level labels are utilized, which are substantially easier to acquire than creating detailed segmentation masks. The effectiveness of the method is demonstrated by segmenting synthetic targets and actual kidney tumors from CT images acquired from Tartu University Hospital in Estonia. The findings indicate that COIN greatly surpasses established attribution methods, such as RISE, ScoreCAM, and LayerCAM, as well as an alternative counterfactual explanation method introduced by Singla et al. This evidence suggests that COIN is a promising approach for semantic segmentation of tumors in CT images, and presents a step forward in making deep learning applications more accessible and effective in healthcare, where annotated data is scarce.
Emergence of Adaptive Circadian Rhythms in Deep Reinforcement Learning
Jul 22, 2023



Adapting to regularities of the environment is critical for biological organisms to anticipate events and plan. A prominent example is the circadian rhythm corresponding to the internalization by organisms of the $24$-hour period of the Earth's rotation. In this work, we study the emergence of circadian-like rhythms in deep reinforcement learning agents. In particular, we deployed agents in an environment with a reliable periodic variation while solving a foraging task. We systematically characterize the agent's behavior during learning and demonstrate the emergence of a rhythm that is endogenous and entrainable. Interestingly, the internal rhythm adapts to shifts in the phase of the environmental signal without any re-training. Furthermore, we show via bifurcation and phase response curve analyses how artificial neurons develop dynamics to support the internalization of the environmental rhythm. From a dynamical systems view, we demonstrate that the adaptation proceeds by the emergence of a stable periodic orbit in the neuron dynamics with a phase response that allows an optimal phase synchronisation between the agent's dynamics and the environmental rhythm.
Mind the gap: Challenges of deep learning approaches to Theory of Mind
Mar 30, 2022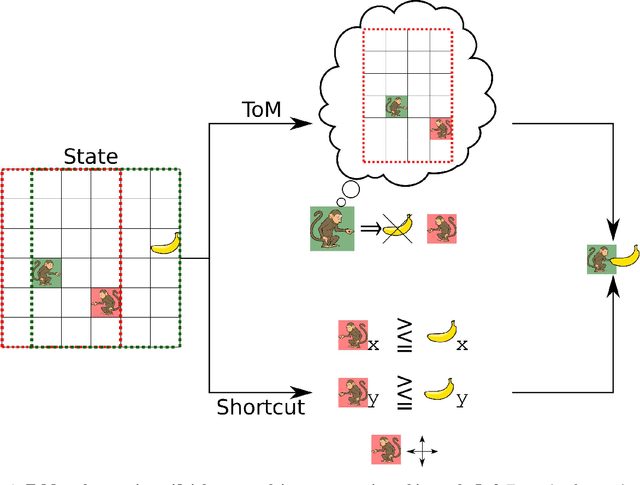
Theory of Mind is an essential ability of humans to infer the mental states of others. Here we provide a coherent summary of the potential, current progress, and problems of deep learning approaches to Theory of Mind. We highlight that many current findings can be explained through shortcuts. These shortcuts arise because the tasks used to investigate Theory of Mind in deep learning systems have been too narrow. Thus, we encourage researchers to investigate Theory of Mind in complex open-ended environments. Furthermore, to inspire future deep learning systems we provide a concise overview of prior work done in humans. We further argue that when studying Theory of Mind with deep learning, the research's main focus and contribution ought to be opening up the network's representations. We recommend researchers use tools from the field of interpretability of AI to study the relationship between different network components and aspects of Theory of Mind.
Did I do that? Blame as a means to identify controlled effects in reinforcement learning
Jun 01, 2021
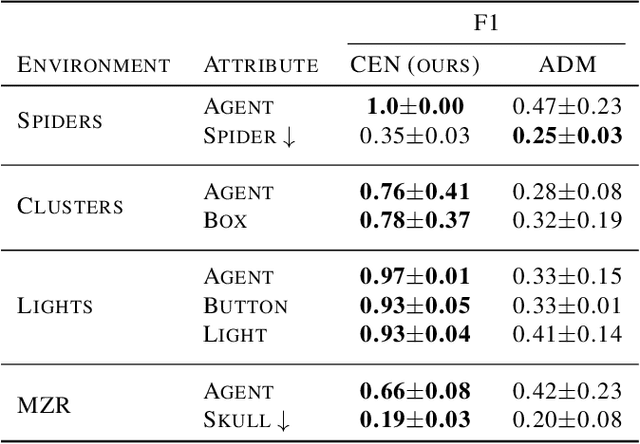
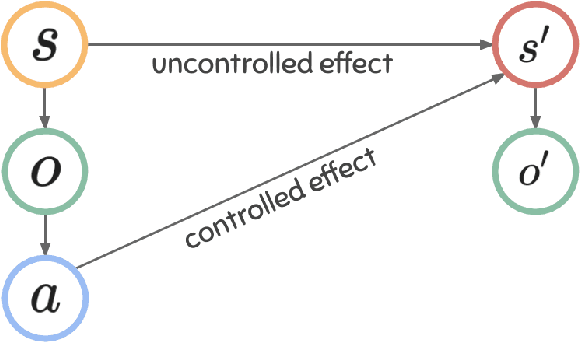
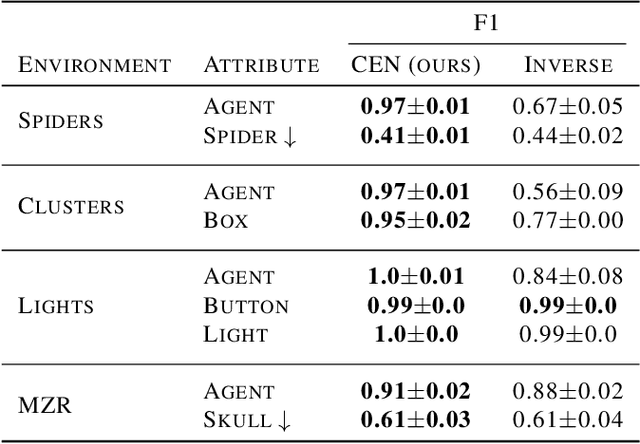
Modeling controllable aspects of the environment enable better prioritization of interventions and has become a popular exploration strategy in reinforcement learning methods. Despite repeatedly achieving State-of-the-Art results, this approach has only been studied as a proxy to a reward-based task and has not yet been evaluated on its own. We show that solutions relying on action prediction fail to model important events. Humans, on the other hand, assign blame to their actions to decide what they controlled. Here we propose Controlled Effect Network (CEN), an unsupervised method based on counterfactual measures of blame. CEN is evaluated in a wide range of environments showing that it can identify controlled effects better than popular models based on action prediction.
Deep Learning with a Single Neuron: Folding a Deep Neural Network in Time using Feedback-Modulated Delay Loops
Nov 19, 2020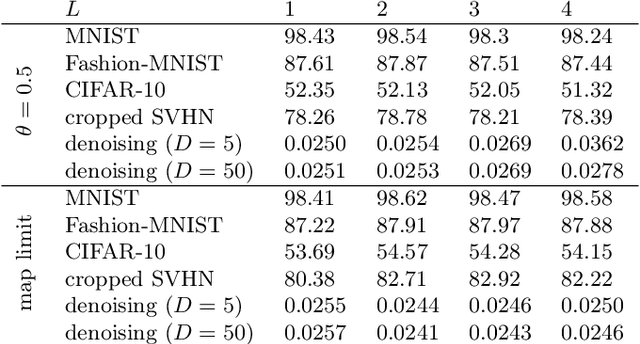
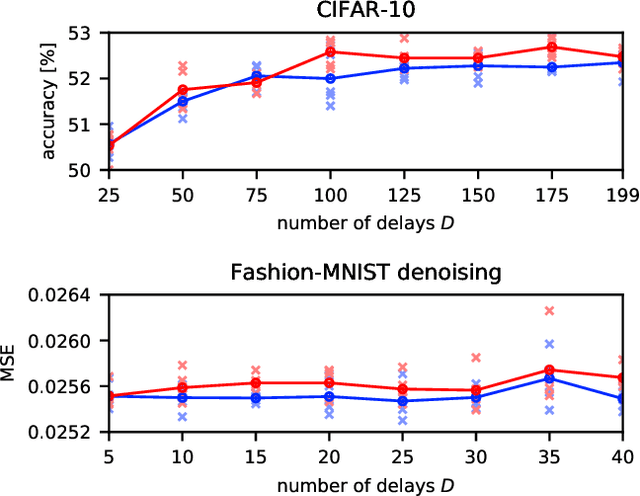
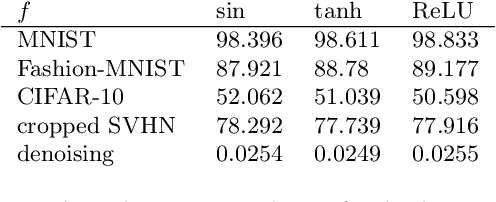
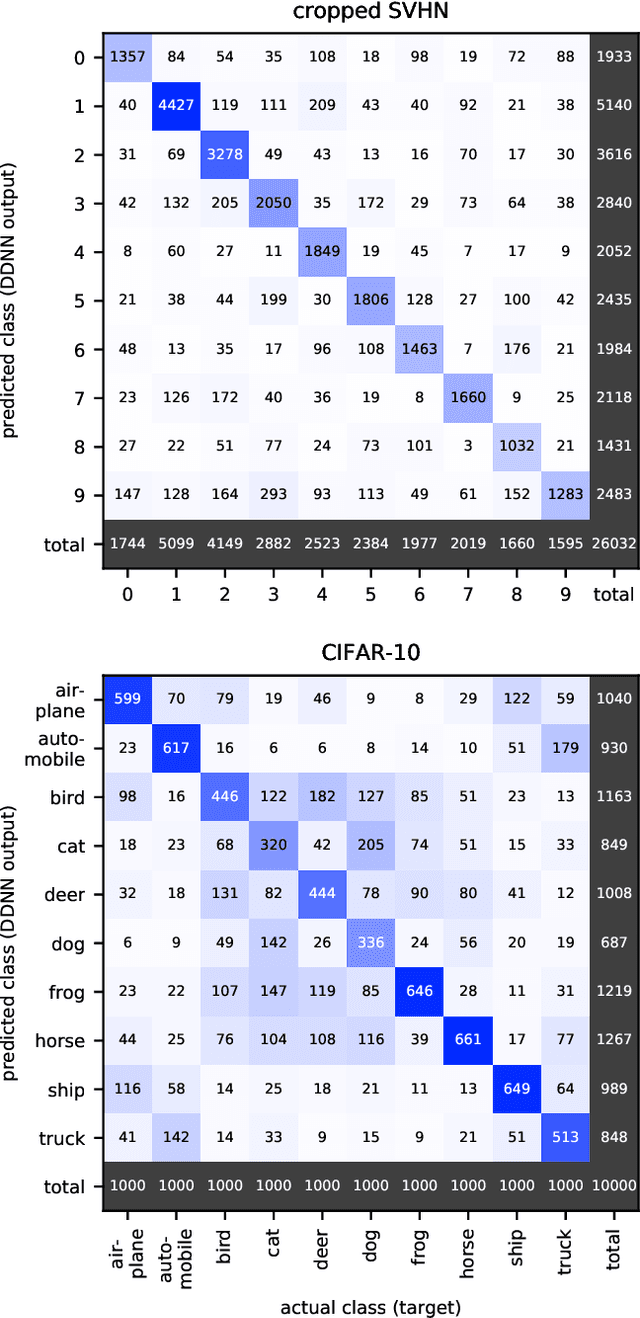
Deep neural networks are among the most widely applied machine learning tools showing outstanding performance in a broad range of tasks. We present a method for folding a deep neural network of arbitrary size into a single neuron with multiple time-delayed feedback loops. This single-neuron deep neural network comprises only a single nonlinearity and appropriately adjusted modulations of the feedback signals. The network states emerge in time as a temporal unfolding of the neuron's dynamics. By adjusting the feedback-modulation within the loops, we adapt the network's connection weights. These connection weights are determined via a modified back-propagation algorithm that we designed for such types of networks. Our approach fully recovers standard Deep Neural Networks (DNN), encompasses sparse DNNs, and extends the DNN concept toward dynamical systems implementations. The new method, which we call Folded-in-time DNN (Fit-DNN), exhibits promising performance in a set of benchmark tasks.
Disentangling causal effects for hierarchical reinforcement learning
Oct 03, 2020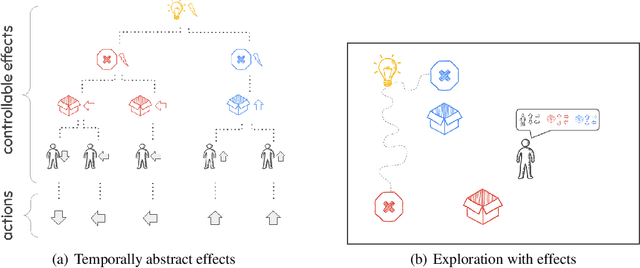
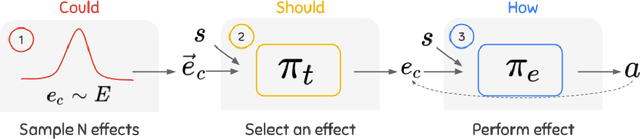

Exploration and credit assignment under sparse rewards are still challenging problems. We argue that these challenges arise in part due to the intrinsic rigidity of operating at the level of actions. Actions can precisely define how to perform an activity but are ill-suited to describe what activity to perform. Instead, causal effects are inherently composable and temporally abstract, making them ideal for descriptive tasks. By leveraging a hierarchy of causal effects, this study aims to expedite the learning of task-specific behavior and aid exploration. Borrowing counterfactual and normality measures from causal literature, we disentangle controllable effects from effects caused by other dynamics of the environment. We propose CEHRL, a hierarchical method that models the distribution of controllable effects using a Variational Autoencoder. This distribution is used by a high-level policy to 1) explore the environment via random effect exploration so that novel effects are continuously discovered and learned, and to 2) learn task-specific behavior by prioritizing the effects that maximize a given reward function. In comparison to exploring with random actions, experimental results show that random effect exploration is a more efficient mechanism and that by assigning credit to few effects rather than many actions, CEHRL learns tasks more rapidly.
The many faces of deep learning
Aug 25, 2019Deep learning has sparked a network of mutual interactions between different disciplines and AI. Naturally, each discipline focuses and interprets the workings of deep learning in different ways. This diversity of perspectives on deep learning, from neuroscience to statistical physics, is a rich source of inspiration that fuels novel developments in the theory and applications of machine learning. In this perspective, we collect and synthesize different intuitions scattered across several communities as for how deep learning works. In particular, we will briefly discuss the different perspectives that disciplines across mathematics, physics, computation, and neuroscience take on how deep learning does its tricks. Our discussion on each perspective is necessarily shallow due to the multiple views that had to be covered. The deepness in this case should come from putting all these faces of deep learning together in the reader's mind, so that one can look at the same problem from different angles.