 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Scalable Evaluation of Bias Patterns in Medical LLMs
Oct 18, 2024



Large language models (LLMs) have shown impressive potential in helping with numerous medical challenges. Deploying LLMs in high-stakes applications such as medicine, however, brings in many concerns. One major area of concern relates to biased behaviors of LLMs in medical applications, leading to unfair treatment of individuals. To pave the way for the responsible and impactful deployment of Med LLMs, rigorous evaluation is a key prerequisite. Due to the huge complexity and variability of different medical scenarios, existing work in this domain has primarily relied on using manually crafted datasets for bias evaluation. In this study, we present a new method to scale up such bias evaluations by automatically generating test cases based on rigorous medical evidence. We specifically target the challenges of a) domain-specificity of bias characterization, b) hallucinating while generating the test cases, and c) various dependencies between the health outcomes and sensitive attributes. To that end, we offer new methods to address these challenges integrated with our generative pipeline, using medical knowledge graphs, medical ontologies, and customized general LLM evaluation frameworks in our method. Through a series of extensive experiments, we show that the test cases generated by our proposed method can effectively reveal bias patterns in Med LLMs at larger and more flexible scales than human-crafted datasets. We publish a large bias evaluation dataset using our pipeline, which is dedicated to a few medical case studies. A live demo of our application for vignette generation is available at https://vignette.streamlit.app. Our code is also available at https://github.com/healthylaife/autofair.
Aligning (Medical) LLMs for (Counterfactual) Fairness
Aug 22, 2024Large Language Models (LLMs) have emerged as promising solutions for a variety of medical and clinical decision support applications. However, LLMs are often subject to different types of biases, which can lead to unfair treatment of individuals, worsening health disparities, and reducing trust in AI-augmented medical tools. Aiming to address this important issue, in this study, we present a new model alignment approach for aligning LLMs using a preference optimization method within a knowledge distillation framework. Prior to presenting our proposed method, we first use an evaluation framework to conduct a comprehensive (largest to our knowledge) empirical evaluation to reveal the type and nature of existing biases in LLMs used for medical applications. We then offer a bias mitigation technique to reduce the unfair patterns in LLM outputs across different subgroups identified by the protected attributes. We show that our mitigation method is effective in significantly reducing observed biased patterns. Our code is publicly available at \url{https://github.com/healthylaife/FairAlignmentLLM}.
Fairness-Optimized Synthetic EHR Generation for Arbitrary Downstream Predictive Tasks
Jun 04, 2024



Among various aspects of ensuring the responsible design of AI tools for healthcare applications, addressing fairness concerns has been a key focus area. Specifically, given the wide spread of electronic health record (EHR) data and their huge potential to inform a wide range of clinical decision support tasks, improving fairness in this category of health AI tools is of key importance. While such a broad problem (that is, mitigating fairness in EHR-based AI models) has been tackled using various methods, task- and model-agnostic methods are noticeably rare. In this study, we aimed to target this gap by presenting a new pipeline that generates synthetic EHR data, which is not only consistent with (faithful to) the real EHR data but also can reduce the fairness concerns (defined by the end-user) in the downstream tasks, when combined with the real data. We demonstrate the effectiveness of our proposed pipeline across various downstream tasks and two different EHR datasets. Our proposed pipeline can add a widely applicable and complementary tool to the existing toolbox of methods to address fairness in health AI applications such as those modifying the design of a downstream model. The codebase for our project is available at https://github.com/healthylaife/FairSynth
Bias patterns in the application of LLMs for clinical decision support: A comprehensive study
Apr 23, 2024



Large Language Models (LLMs) have emerged as powerful candidates to inform clinical decision-making processes. While these models play an increasingly prominent role in shaping the digital landscape, two growing concerns emerge in healthcare applications: 1) to what extent do LLMs exhibit social bias based on patients' protected attributes (like race), and 2) how do design choices (like architecture design and prompting strategies) influence the observed biases? To answer these questions rigorously, we evaluated eight popular LLMs across three question-answering (QA) datasets using clinical vignettes (patient descriptions) standardized for bias evaluations. We employ red-teaming strategies to analyze how demographics affect LLM outputs, comparing both general-purpose and clinically-trained models. Our extensive experiments reveal various disparities (some significant) across protected groups. We also observe several counter-intuitive patterns such as larger models not being necessarily less biased and fined-tuned models on medical data not being necessarily better than the general-purpose models. Furthermore, our study demonstrates the impact of prompt design on bias patterns and shows that specific phrasing can influence bias patterns and reflection-type approaches (like Chain of Thought) can reduce biased outcomes effectively. Consistent with prior studies, we call on additional evaluations, scrutiny, and enhancement of LLMs used in clinical decision support applications.
Improving Fairness in AI Models on Electronic Health Records: The Case for Federated Learning Methods
May 19, 2023



Developing AI tools that preserve fairness is of critical importance, specifically in high-stakes applications such as those in healthcare. However, health AI models' overall prediction performance is often prioritized over the possible biases such models could have. In this study, we show one possible approach to mitigate bias concerns by having healthcare institutions collaborate through a federated learning paradigm (FL; which is a popular choice in healthcare settings). While FL methods with an emphasis on fairness have been previously proposed, their underlying model and local implementation techniques, as well as their possible applications to the healthcare domain remain widely underinvestigated. Therefore, we propose a comprehensive FL approach with adversarial debiasing and a fair aggregation method, suitable to various fairness metrics, in the healthcare domain where electronic health records are used. Not only our approach explicitly mitigates bias as part of the optimization process, but an FL-based paradigm would also implicitly help with addressing data imbalance and increasing the data size, offering a practical solution for healthcare applications. We empirically demonstrate our method's superior performance on multiple experiments simulating large-scale real-world scenarios and compare it to several baselines. Our method has achieved promising fairness performance with the lowest impact on overall discrimination performance (accuracy).
An Extensive Data Processing Pipeline for MIMIC-IV
Apr 29, 2022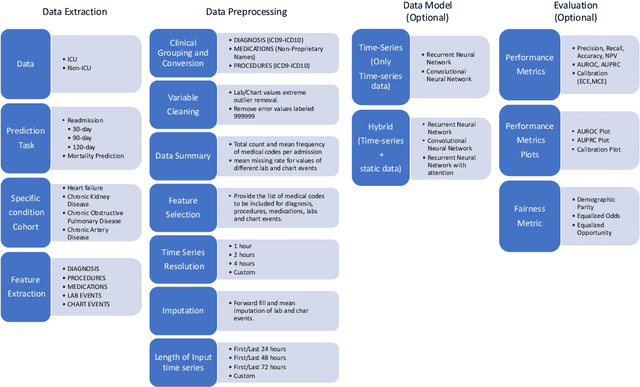

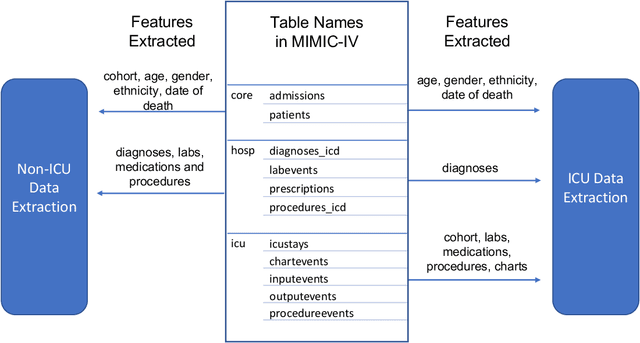
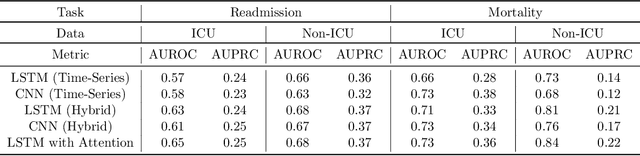
An increasing amount of research is being devoted to applying machine learning methods to electronic health record (EHR) data for various clinical tasks. This growing area of research has exposed the limitation of accessibility of EHR datasets for all, as well as the reproducibility of different modeling frameworks. One reason for these limitations is the lack of standardized pre-processing pipelines. MIMIC is a freely available EHR dataset in a raw format that has been used in numerous studies. The absence of standardized pre-processing steps serves as a major barrier to the wider adoption of the dataset. It also leads to different cohorts being used in downstream tasks, limiting the ability to compare the results among similar studies. Contrasting studies also use various distinct performance metrics, which can greatly reduce the ability to compare model results. In this work, we provide an end-to-end fully customizable pipeline to extract, clean, and pre-process data; and to predict and evaluate the fourth version of the MIMIC dataset (MIMIC-IV) for ICU and non-ICU-related clinical time-series prediction tasks.