 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWind Noise Reduction with a Diffusion-based Stochastic Regeneration Model
Jun 22, 2023



In this paper we present a method for single-channel wind noise reduction using our previously proposed diffusion-based stochastic regeneration model combining predictive and generative modelling. We introduce a non-additive speech in noise model to account for the non-linear deformation of the membrane caused by the wind flow and possible clipping. We show that our stochastic regeneration model outperforms other neural-network-based wind noise reduction methods as well as purely predictive and generative models, on a dataset using simulated and real-recorded wind noise. We further show that the proposed method generalizes well by testing on an unseen dataset with real-recorded wind noise. Audio samples, data generation scripts and code for the proposed methods can be found online (https://uhh.de/inf-sp-storm-wind).
Neural Network-augmented Kalman Filtering for Robust Online Speech Dereverberation in Noisy Reverberant Environments
Apr 06, 2022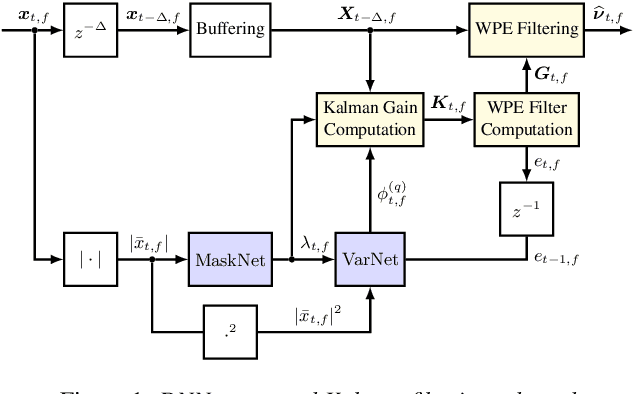
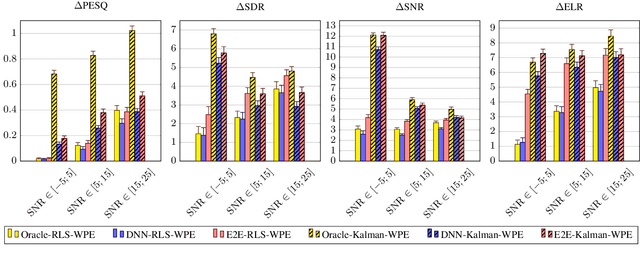
In this paper, a neural network-augmented algorithm for noise-robust online dereverberation with a Kalman filtering variant of the weighted prediction error (WPE) method is proposed. The filter stochastic variations are predicted by a deep neural network (DNN) trained end-to-end using the filter residual error and signal characteristics. The presented framework allows for robust dereverberation on a single-channel noisy reverberant dataset similar to WHAMR!. The Kalman filtering WPE introduces distortions in the enhanced signal when predicting the filter variations from the residual error only, if the target speech power spectral density is not perfectly known and the observation is noisy. The proposed approach avoids these distortions by correcting the filter variations estimation in a data-driven way, increasing the robustness of the method to noisy scenarios. Furthermore, it yields a strong dereverberation and denoising performance compared to a DNN-supported recursive least squares variant of WPE, especially for highly noisy inputs.
End-To-End Optimization of Online Neural Network-supported Two-Stage Dereverberation for Hearing Devices
Apr 06, 2022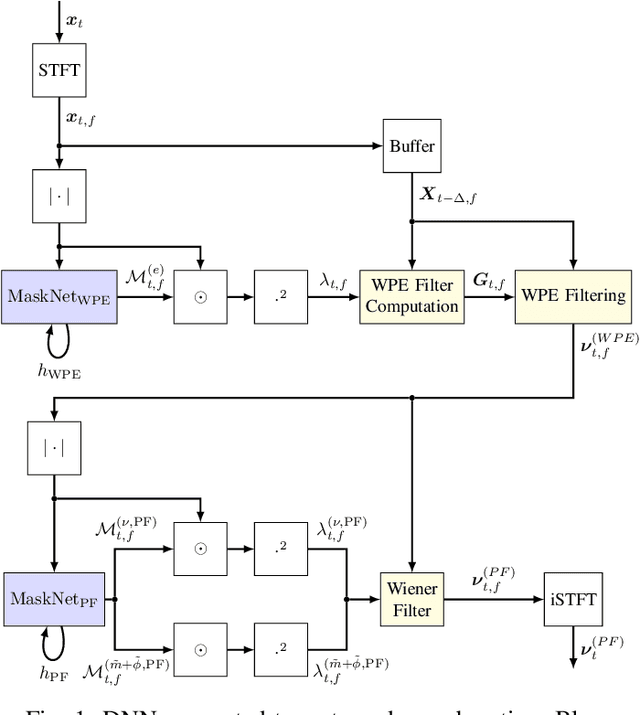
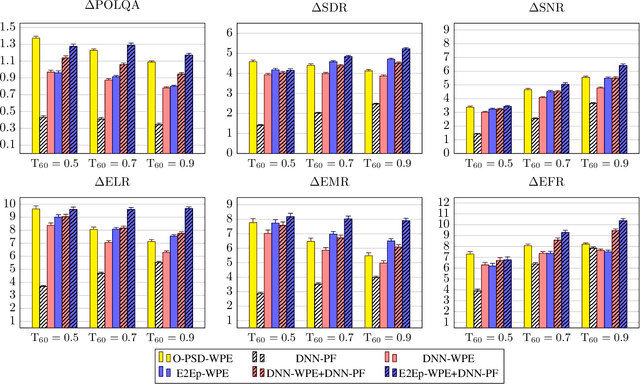
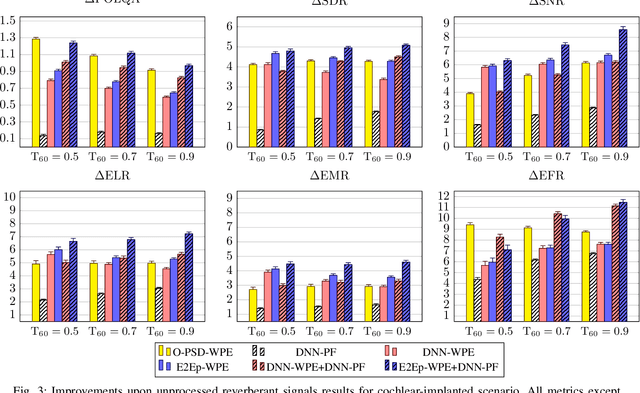
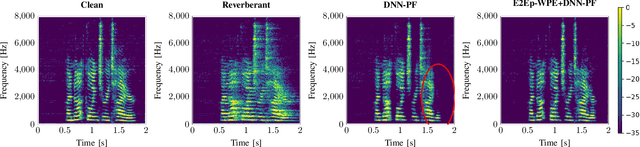
A two-stage online dereverberation algorithm for hearing devices is presented in this paper. The approach combines a multi-channel multi-frame linear filtering approach with a single-channel single-frame post-filter. Both components rely on power spectral density (PSD) estimates provided by deep neural networks (DNNs). This contribution extends our prior work, which shows that directly optimizing for a criterion at the output of the multi-channel linear filtering stage results in a more efficient dereverberation, as compared to placing the criterion at the output of the DNN to optimize the PSD estimation. In the present work, we show that the dereverberation performance of the proposed first stage particularly improves the early-to-mid reverberation ratio if trained end-to-end. We thus argue that it can be combined with a post-filtering stage which benefits from the early-to-mid ratio improvement and is consequently able to efficiently suppress the residual late reverberation. This proposed two stage procedure is shown to be both very effective in terms of dereverberation performance and computational demands. Furthermore, the proposed system can be adapted to the needs of different types of hearing-device users by controlling the amount of reduction of early reflections. The proposed system outperforms the previously proposed end-to-end DNN-supported linear filtering algorithm, as well as other traditional approaches, based on an evaluation using the noise-free version of the WHAMR! dataset.
Customizable End-to-end Optimization of Online Neural Network-supported Dereverberation for Hearing Devices
Apr 06, 2022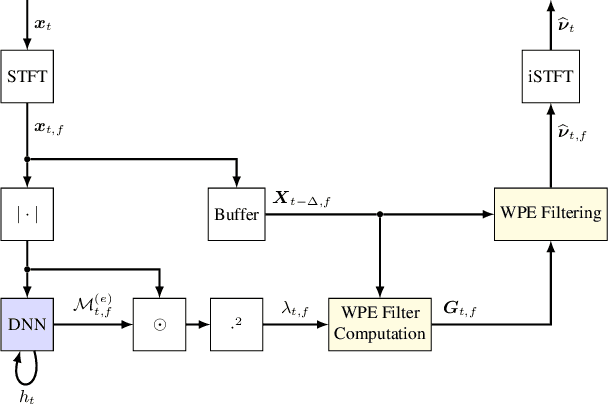


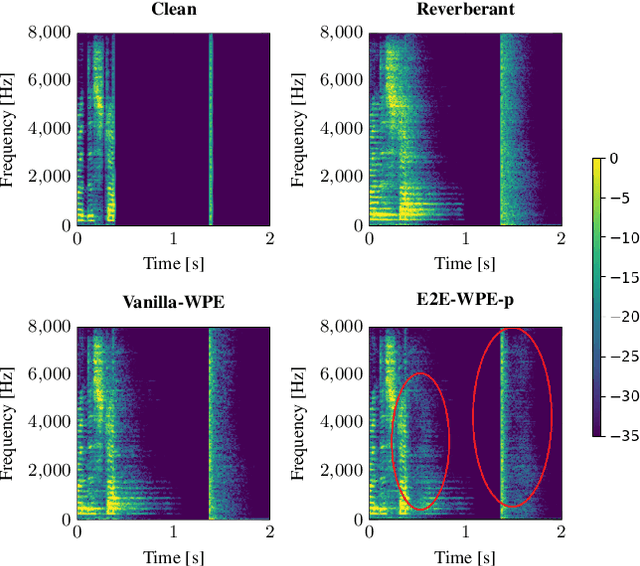
This work focuses on online dereverberation for hearing devices using the weighted prediction error (WPE) algorithm. WPE filtering requires an estimate of the target speech power spectral density (PSD). Recently deep neural networks (DNNs) have been used for this task. However, these approaches optimize the PSD estimate which only indirectly affects the WPE output, thus potentially resulting in limited dereverberation. In this paper, we propose an end-to-end approach specialized for online processing, that directly optimizes the dereverberated output signal. In addition, we propose to adapt it to the needs of different types of hearing-device users by modifying the optimization target as well as the WPE algorithm characteristics used in training. We show that the proposed end-to-end approach outperforms the traditional and conventional DNN-supported WPEs on a noise-free version of the WHAMR! dataset.
* \copyright 2022 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works