 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting English Writing Styles For Non Native Speakers
Apr 24, 2017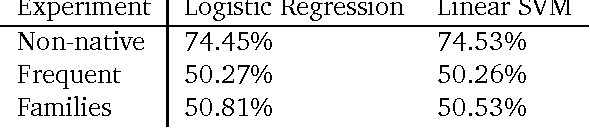
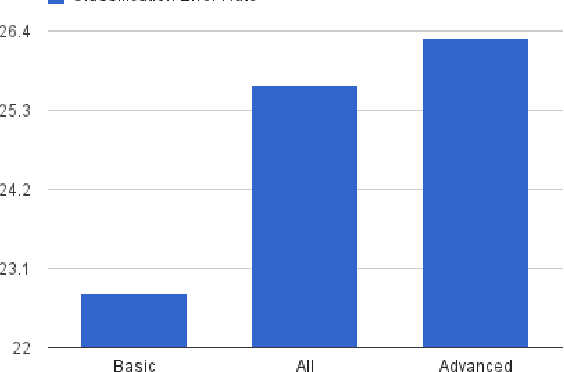
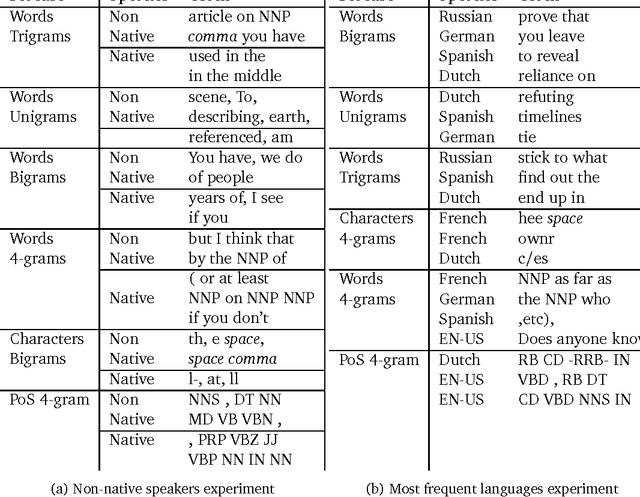
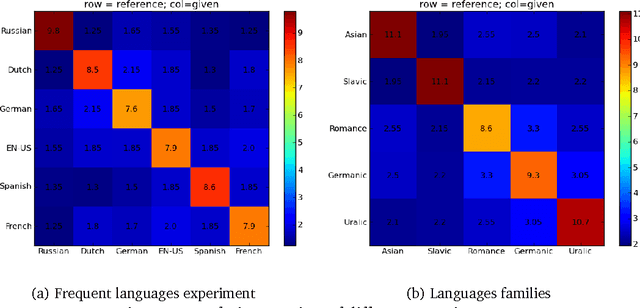
This paper presents the first attempt, up to our knowledge, to classify English writing styles on this scale with the challenge of classifying day to day language written by writers with different backgrounds covering various areas of topics.The paper proposes simple machine learning algorithms and simple to generate features to solve hard problems. Relying on the scale of the data available from large sources of knowledge like Wikipedia. We believe such sources of data are crucial to generate robust solutions for the web with high accuracy and easy to deploy in practice. The paper achieves 74\% accuracy classifying native versus non native speakers writing styles. Moreover, the paper shows some interesting observations on the similarity between different languages measured by the similarity of their users English writing styles. This technique could be used to show some well known facts about languages as in grouping them into families, which our experiments support.
Exploring the power of GPU's for training Polyglot language models
Apr 15, 2014
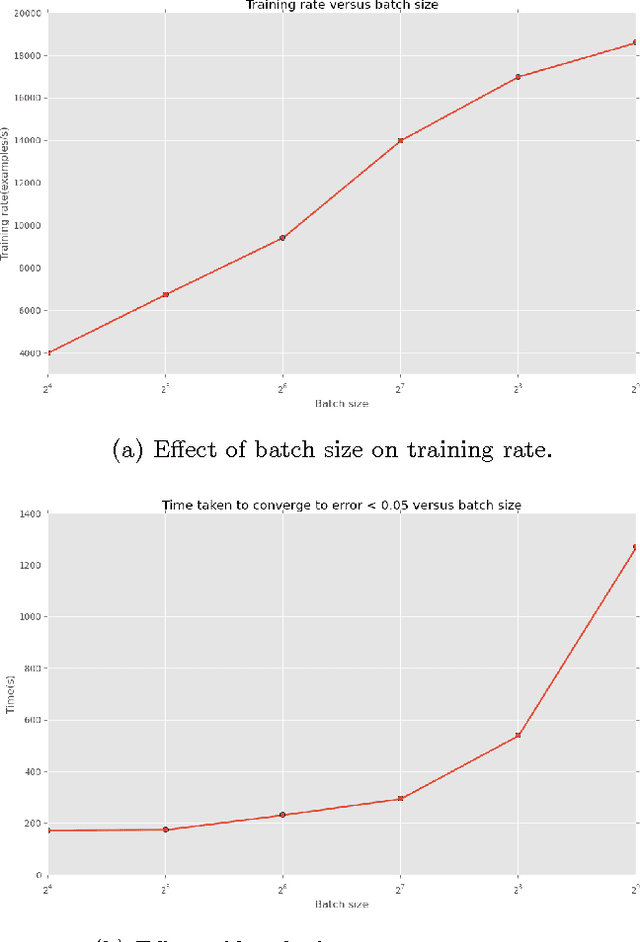
One of the major research trends currently is the evolution of heterogeneous parallel computing. GP-GPU computing is being widely used and several applications have been designed to exploit the massive parallelism that GP-GPU's have to offer. While GPU's have always been widely used in areas of computer vision for image processing, little has been done to investigate whether the massive parallelism provided by GP-GPU's can be utilized effectively for Natural Language Processing(NLP) tasks. In this work, we investigate and explore the power of GP-GPU's in the task of learning language models. More specifically, we investigate the performance of training Polyglot language models using deep belief neural networks. We evaluate the performance of training the model on the GPU and present optimizations that boost the performance on the GPU.One of the key optimizations, we propose increases the performance of a function involved in calculating and updating the gradient by approximately 50 times on the GPU for sufficiently large batch sizes. We show that with the above optimizations, the GP-GPU's performance on the task increases by factor of approximately 3-4. The optimizations we made are generic Theano optimizations and hence potentially boost the performance of other models which rely on these operations.We also show that these optimizations result in the GPU's performance at this task being now comparable to that on the CPU. We conclude by presenting a thorough evaluation of the applicability of GP-GPU's for this task and highlight the factors limiting the performance of training a Polyglot model on the GPU.
SpeedRead: A Fast Named Entity Recognition Pipeline
Jan 14, 2013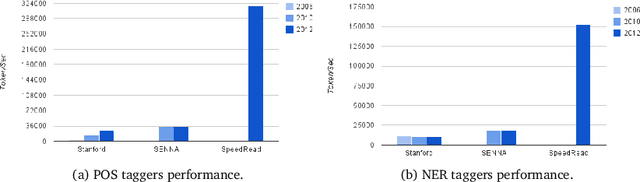
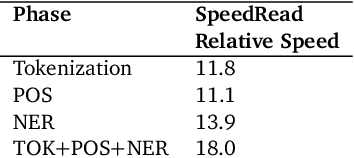
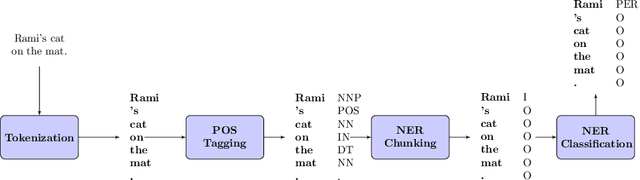
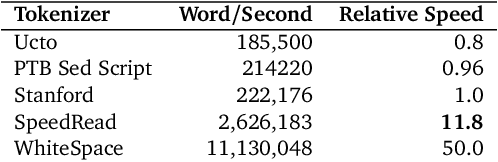
Online content analysis employs algorithmic methods to identify entities in unstructured text. Both machine learning and knowledge-base approaches lie at the foundation of contemporary named entities extraction systems. However, the progress in deploying these approaches on web-scale has been been hampered by the computational cost of NLP over massive text corpora. We present SpeedRead (SR), a named entity recognition pipeline that runs at least 10 times faster than Stanford NLP pipeline. This pipeline consists of a high performance Penn Treebank- compliant tokenizer, close to state-of-art part-of-speech (POS) tagger and knowledge-based named entity recognizer.
Detecting English Writing Styles For Non-native Speakers
Nov 02, 2012Analyzing writing styles of non-native speakers is a challenging task. In this paper, we analyze the comments written in the discussion pages of the English Wikipedia. Using learning algorithms, we are able to detect native speakers' writing style with an accuracy of 74%. Given the diversity of the English Wikipedia users and the large number of languages they speak, we measure the similarities among their native languages by comparing the influence they have on their English writing style. Our results show that languages known to have the same origin and development path have similar footprint on their speakers' English writing style. To enable further studies, the dataset we extracted from Wikipedia will be made available publicly.