 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuTI! Quantifying Text-Image Consistency in Multimodal Documents
Apr 28, 2021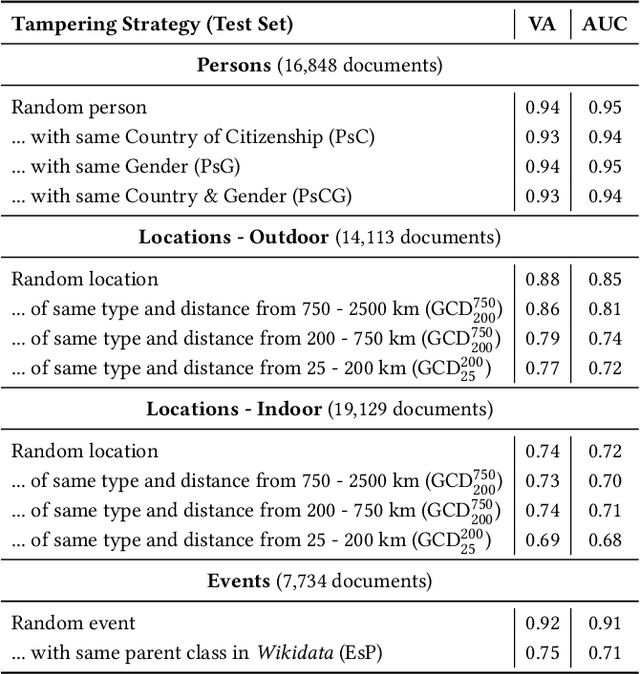
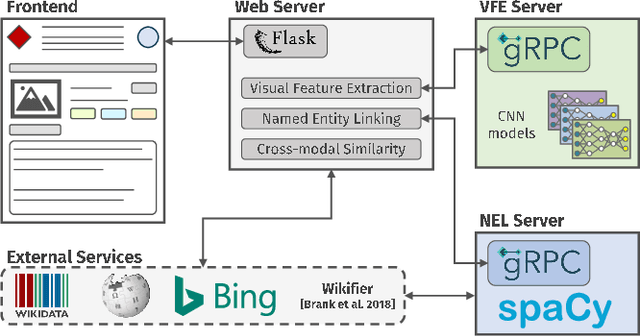
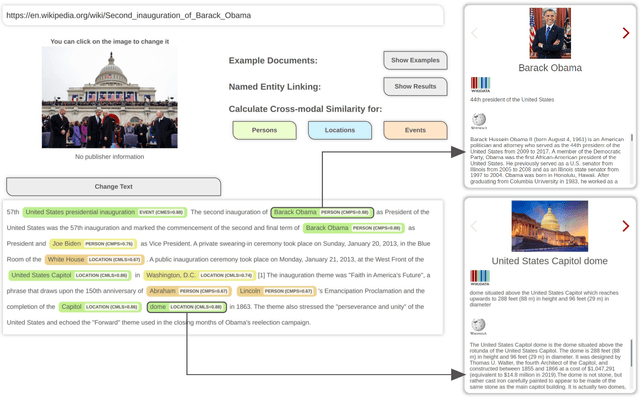
The World Wide Web and social media platforms have become popular sources for news and information. Typically, multimodal information, e.g., image and text is used to convey information more effectively and to attract attention. While in most cases image content is decorative or depicts additional information, it has also been leveraged to spread misinformation and rumors in recent years. In this paper, we present a Web-based demo application that automatically quantifies the cross-modal relations of entities (persons, locations, and events) in image and text. The applications are manifold. For example, the system can help users to explore multimodal articles more efficiently, or can assist human assessors and fact-checking efforts in the verification of the credibility of news stories, tweets, or other multimodal documents.
On the Role of Images for Analyzing Claims in Social Media
Mar 17, 2021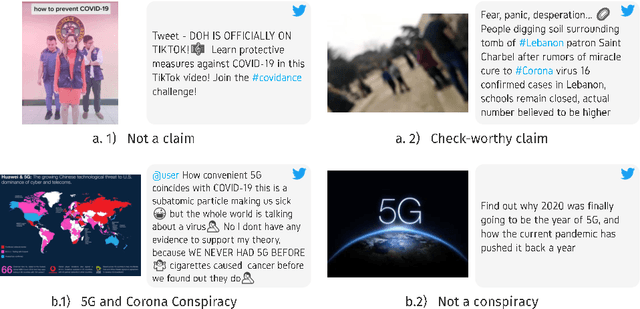
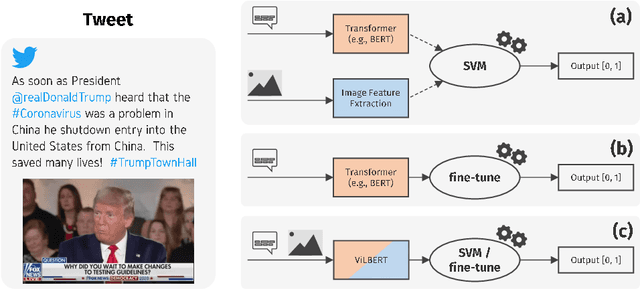
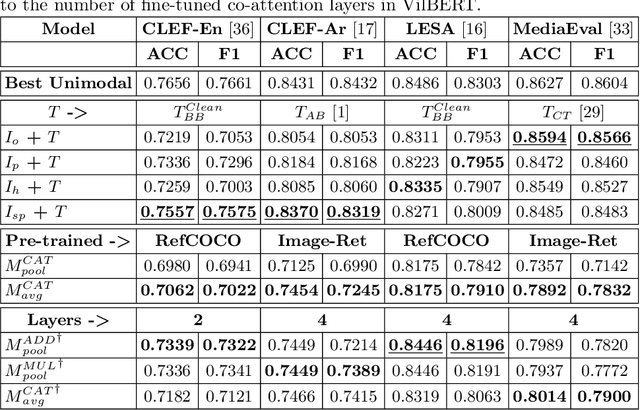
Fake news is a severe problem in social media. In this paper, we present an empirical study on visual, textual, and multimodal models for the tasks of claim, claim check-worthiness, and conspiracy detection, all of which are related to fake news detection. Recent work suggests that images are more influential than text and often appear alongside fake text. To this end, several multimodal models have been proposed in recent years that use images along with text to detect fake news on social media sites like Twitter. However, the role of images is not well understood for claim detection, specifically using transformer-based textual and multimodal models. We investigate state-of-the-art models for images, text (Transformer-based), and multimodal information for four different datasets across two languages to understand the role of images in the task of claim and conspiracy detection.
Analysing the Requirements for an Open Research Knowledge Graph: Use Cases, Quality Requirements and Construction Strategies
Feb 11, 2021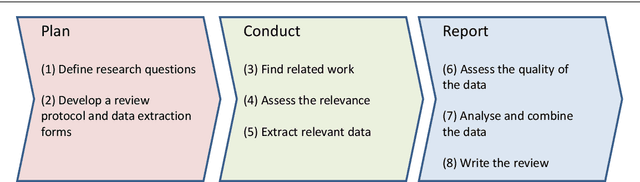
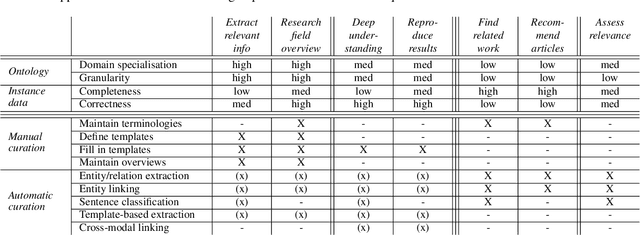
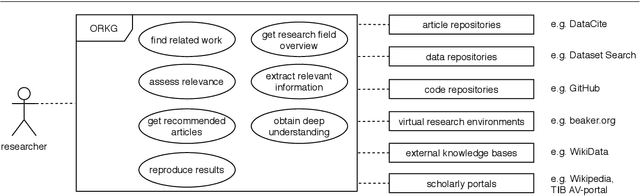
Current science communication has a number of drawbacks and bottlenecks which have been subject of discussion lately: Among others, the rising number of published articles makes it nearly impossible to get a full overview of the state of the art in a certain field, or reproducibility is hampered by fixed-length, document-based publications which normally cannot cover all details of a research work. Recently, several initiatives have proposed knowledge graphs (KG) for organising scientific information as a solution to many of the current issues. The focus of these proposals is, however, usually restricted to very specific use cases. In this paper, we aim to transcend this limited perspective and present a comprehensive analysis of requirements for an Open Research Knowledge Graph (ORKG) by (a) collecting and reviewing daily core tasks of a scientist, (b) establishing their consequential requirements for a KG-based system, (c) identifying overlaps and specificities, and their coverage in current solutions. As a result, we map necessary and desirable requirements for successful KG-based science communication, derive implications, and outline possible solutions.
Sequential Sentence Classification in Research Papers using Cross-Domain Multi-Task Learning
Feb 11, 2021



The task of sequential sentence classification enables the semantic structuring of research papers. This can enhance academic search engines to support researchers in finding and exploring research literature more effectively. However, previous work has not investigated the potential of transfer learning with datasets from different scientific domains for this task yet. We propose a uniform deep learning architecture and multi-task learning to improve sequential sentence classification in scientific texts across domains by exploiting training data from multiple domains. Our contributions can be summarised as follows: (1) We tailor two common transfer learning methods, sequential transfer learning and multi-task learning, and evaluate their performance for sequential sentence classification; (2) The presented multi-task model is able to recognise semantically related classes from different datasets and thus supports manual comparison and assessment of different annotation schemes; (3) The unified approach is capable of handling datasets that contain either only abstracts or full papers without further feature engineering. We demonstrate that models, which are trained on datasets from different scientific domains, benefit from one another when using the proposed multi-task learning architecture. Our approach outperforms the state of the art on three benchmark datasets.
Coreference Resolution in Research Papers from Multiple Domains
Jan 04, 2021



Coreference resolution is essential for automatic text understanding to facilitate high-level information retrieval tasks such as text summarisation or question answering. Previous work indicates that the performance of state-of-the-art approaches (e.g. based on BERT) noticeably declines when applied to scientific papers. In this paper, we investigate the task of coreference resolution in research papers and subsequent knowledge graph population. We present the following contributions: (1) We annotate a corpus for coreference resolution that comprises 10 different scientific disciplines from Science, Technology, and Medicine (STM); (2) We propose transfer learning for automatic coreference resolution in research papers; (3) We analyse the impact of coreference resolution on knowledge graph (KG) population; (4) We release a research KG that is automatically populated from 55,485 papers in 10 STM domains. Comprehensive experiments show the usefulness of the proposed approach. Our transfer learning approach considerably outperforms state-of-the-art baselines on our corpus with an F1 score of 61.4 (+11.0), while the evaluation against a gold standard KG shows that coreference resolution improves the quality of the populated KG significantly with an F1 score of 63.5 (+21.8).
Ontology-driven Event Type Classification in Images
Nov 09, 2020
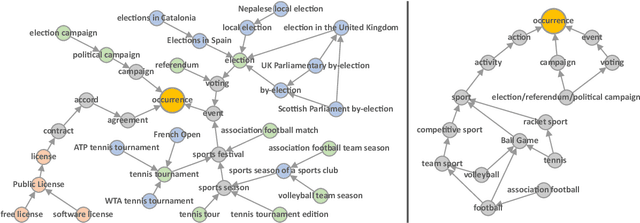
Event classification can add valuable information for semantic search and the increasingly important topic of fact validation in news. So far, only few approaches address image classification for newsworthy event types such as natural disasters, sports events, or elections. Previous work distinguishes only between a limited number of event types and relies on rather small datasets for training. In this paper, we present a novel ontology-driven approach for the classification of event types in images. We leverage a large number of real-world news events to pursue two objectives: First, we create an ontology based on Wikidata comprising the majority of event types. Second, we introduce a novel large-scale dataset that was acquired through Web crawling. Several baselines are proposed including an ontology-driven learning approach that aims to exploit structured information of a knowledge graph to learn relevant event relations using deep neural networks. Experimental results on existing as well as novel benchmark datasets demonstrate the superiority of the proposed ontology-driven approach.
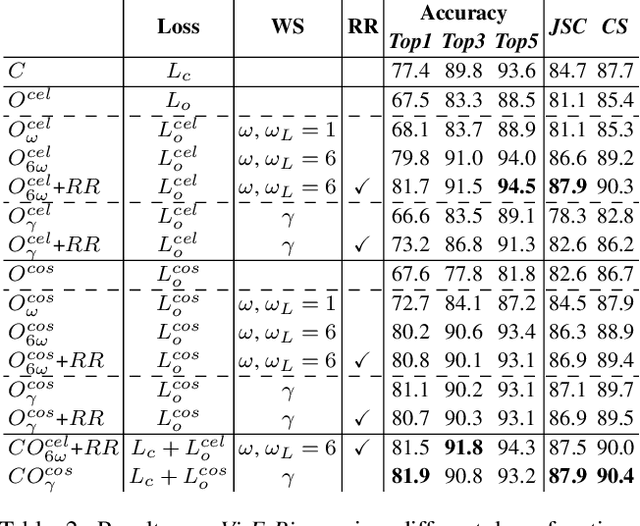
Classification of Important Segments in Educational Videos using Multimodal Features
Oct 26, 2020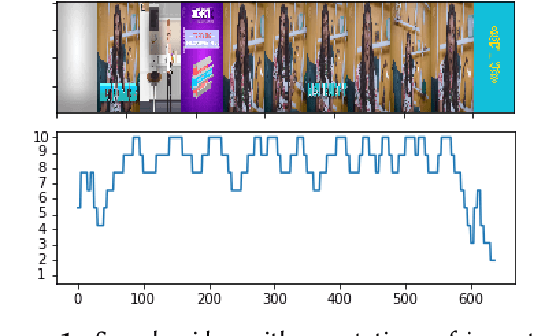
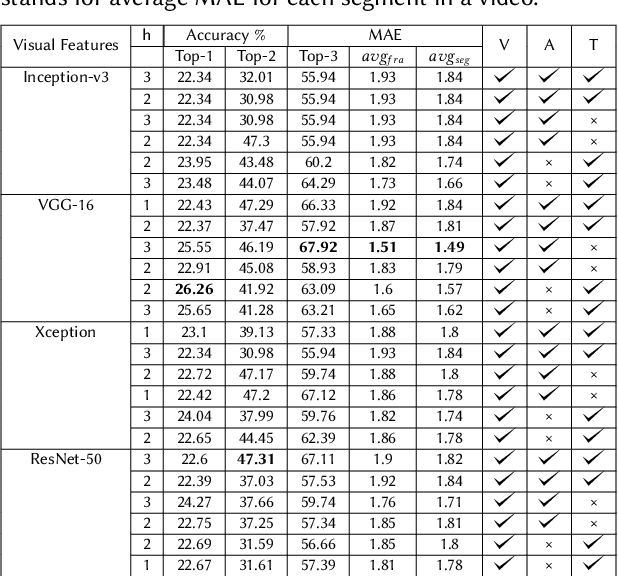
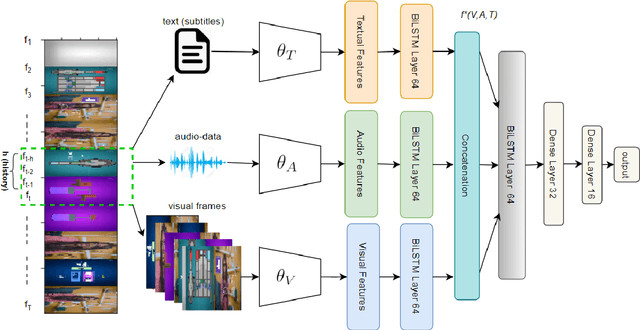
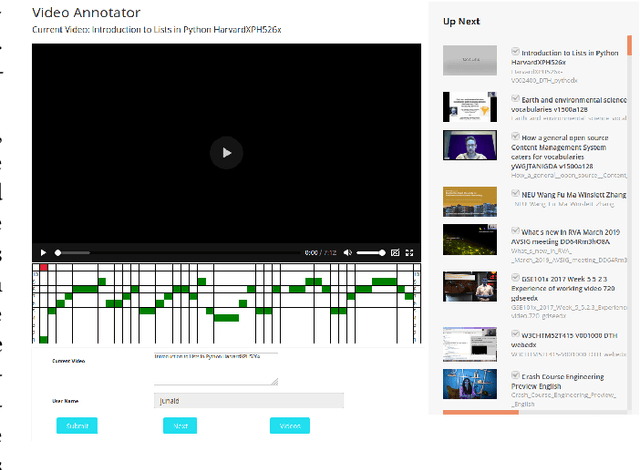
Videos are a commonly-used type of content in learning during Web search. Many e-learning platforms provide quality content, but sometimes educational videos are long and cover many topics. Humans are good in extracting important sections from videos, but it remains a significant challenge for computers. In this paper, we address the problem of assigning importance scores to video segments, that is how much information they contain with respect to the overall topic of an educational video. We present an annotation tool and a new dataset of annotated educational videos collected from popular online learning platforms. Moreover, we propose a multimodal neural architecture that utilizes state-of-the-art audio, visual and textual features. Our experiments investigate the impact of visual and temporal information, as well as the combination of multimodal features on importance prediction.
MLM: A Benchmark Dataset for Multitask Learning with Multiple Languages and Modalities
Sep 04, 2020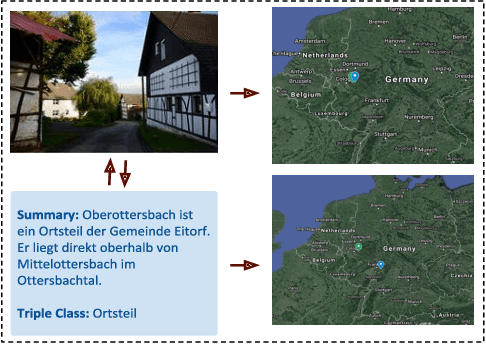
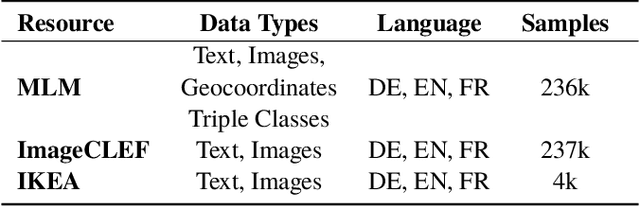
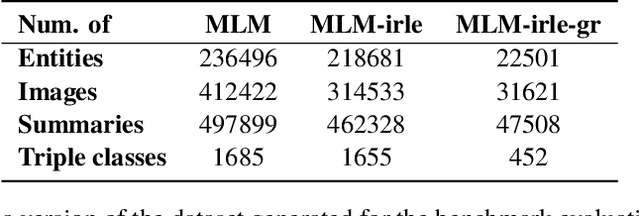
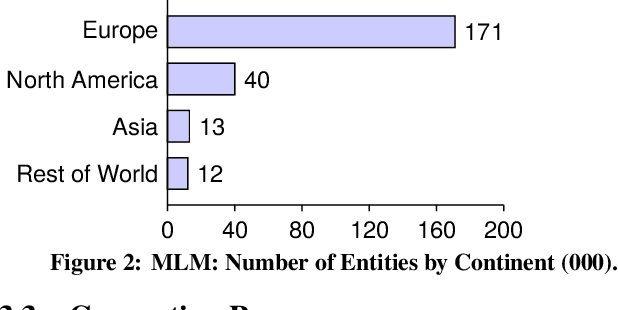
In this paper, we introduce the MLM (Multiple Languages and Modalities) dataset - a new resource to train and evaluate multitask systems on samples in multiple modalities and three languages. The generation process and inclusion of semantic data provide a resource that further tests the ability for multitask systems to learn relationships between entities. The dataset is designed for researchers and developers who build applications that perform multiple tasks on data encountered on the web and in digital archives. A second version of MLM provides a geo-representative subset of the data with weighted samples for countries of the European Union. We demonstrate the value of the resource in developing novel applications in the digital humanities with a motivating use case and specify a benchmark set of tasks to retrieve modalities and locate entities in the dataset. Evaluation of baseline multitask and single task systems on the full and geo-representative versions of MLM demonstrate the challenges of generalising on diverse data. In addition to the digital humanities, we expect the resource to contribute to research in multimodal representation learning, location estimation, and scene understanding.
Check_square at CheckThat! 2020: Claim Detection in Social Media via Fusion of Transformer and Syntactic Features
Jul 21, 2020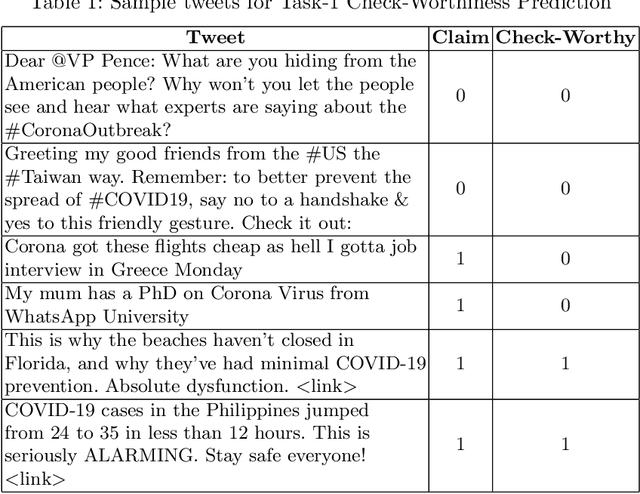
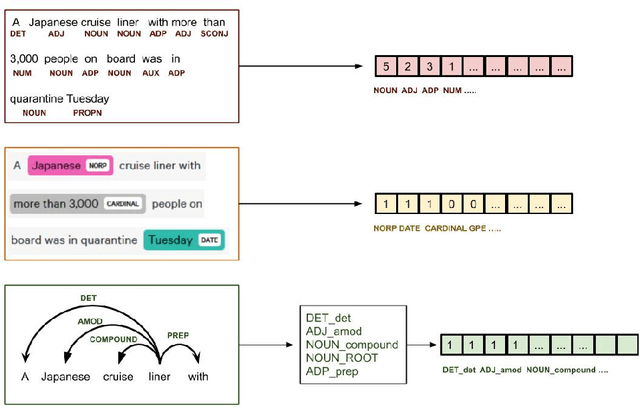
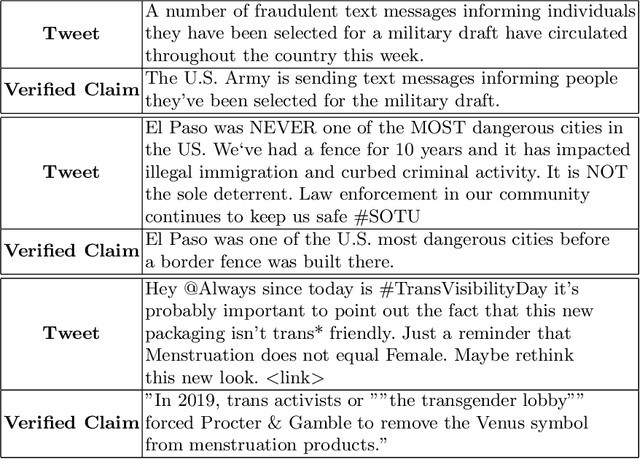
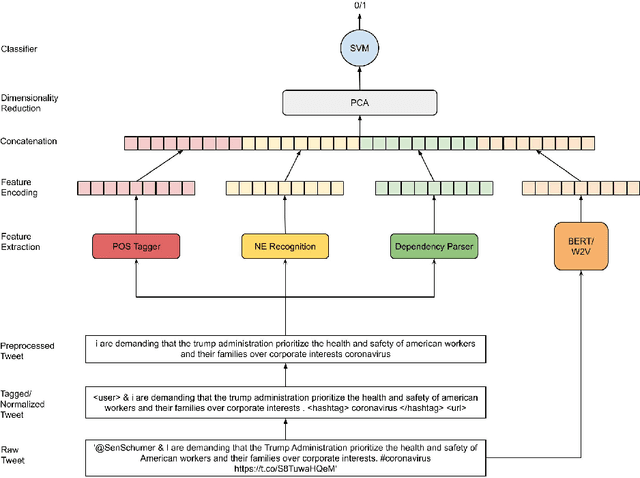
In this digital age of news consumption, a news reader has the ability to react, express and share opinions with others in a highly interactive and fast manner. As a consequence, fake news has made its way into our daily life because of very limited capacity to verify news on the Internet by large companies as well as individuals. In this paper, we focus on solving two problems which are part of the fact-checking ecosystem that can help to automate fact-checking of claims in an ever increasing stream of content on social media. For the first problem, claim check-worthiness prediction, we explore the fusion of syntactic features and deep transformer Bidirectional Encoder Representations from Transformers (BERT) embeddings, to classify check-worthiness of a tweet, i.e. whether it includes a claim or not. We conduct a detailed feature analysis and present our best performing models for English and Arabic tweets. For the second problem, claim retrieval, we explore the pre-trained embeddings from a Siamese network transformer model (sentence-transformers) specifically trained for semantic textual similarity, and perform KD-search to retrieve verified claims with respect to a query tweet.
A Feature Analysis for Multimodal News Retrieval
Jul 13, 2020

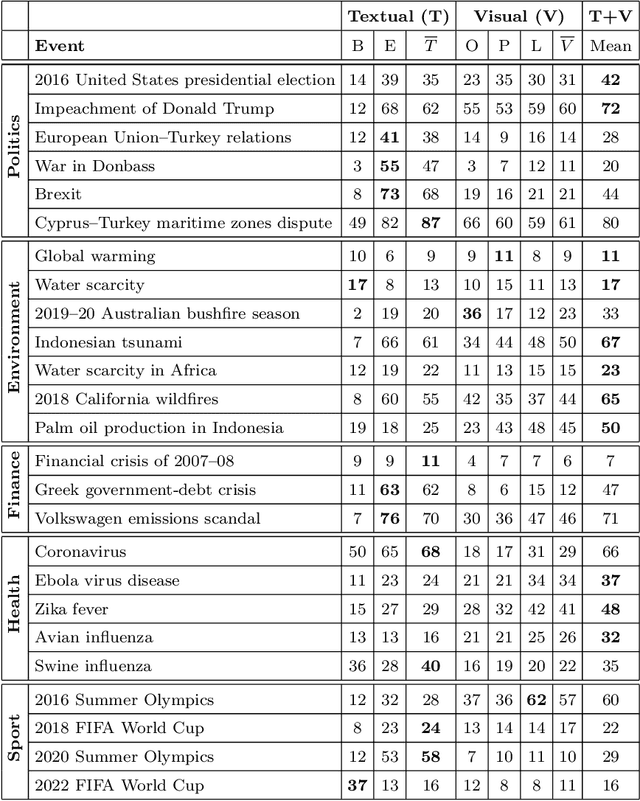
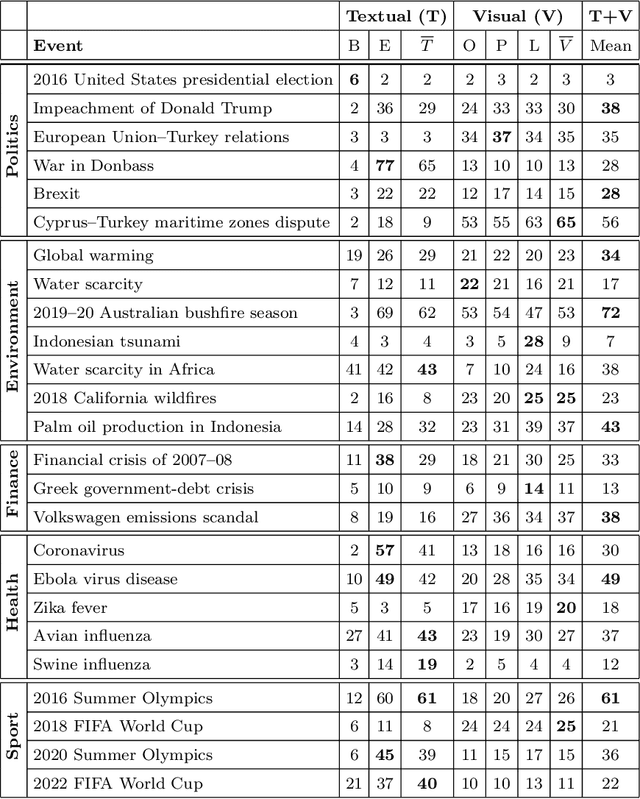
Content-based information retrieval is based on the information contained in documents rather than using metadata such as keywords. Most information retrieval methods are either based on text or image. In this paper, we investigate the usefulness of multimodal features for cross-lingual news search in various domains: politics, health, environment, sport, and finance. To this end, we consider five feature types for image and text and compare the performance of the retrieval system using different combinations. Experimental results show that retrieval results can be improved when considering both visual and textual information. In addition, it is observed that among textual features entity overlap outperforms word embeddings, while geolocation embeddings achieve better performance among visual features in the retrieval task.