 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeckle Noise Analysis for Synthetic Aperture Radar (SAR) Space Data
Aug 16, 2024This research tackles the challenge of speckle noise in Synthetic Aperture Radar (SAR) space data, a prevalent issue that hampers the clarity and utility of SAR images. The study presents a comparative analysis of six distinct speckle noise reduction techniques: Lee Filtering, Frost Filtering, Kuan Filtering, Gaussian Filtering, Median Filtering, and Bilateral Filtering. These methods, selected for their unique approaches to noise reduction and image preservation, were applied to SAR datasets sourced from the Alaska Satellite Facility (ASF). The performance of each technique was evaluated using a comprehensive set of metrics, including Peak Signal-to-Noise Ratio (PSNR), Mean Squared Error (MSE), Structural Similarity Index (SSIM), Equivalent Number of Looks (ENL), and Speckle Suppression Index (SSI). The study concludes that both the Lee and Kuan Filters are effective, with the choice of filter depending on the specific application requirements for image quality and noise suppression. This work provides valuable insights into optimizing SAR image processing, with significant implications for remote sensing, environmental monitoring, and geological surveying.
Automating REST API Postman Test Cases Using LLM
Apr 16, 2024


In the contemporary landscape of technological advancements, the automation of manual processes is crucial, compelling the demand for huge datasets to effectively train and test machines. This research paper is dedicated to the exploration and implementation of an automated approach to generate test cases specifically using Large Language Models. The methodology integrates the use of Open AI to enhance the efficiency and effectiveness of test case generation for training and evaluating Large Language Models. This formalized approach with LLMs simplifies the testing process, making it more efficient and comprehensive. Leveraging natural language understanding, LLMs can intelligently formulate test cases that cover a broad range of REST API properties, ensuring comprehensive testing. The model that is developed during the research is trained using manually collected postman test cases or instances for various Rest APIs. LLMs enhance the creation of Postman test cases by automating the generation of varied and intricate test scenarios. Postman test cases offer streamlined automation, collaboration, and dynamic data handling, providing a user-friendly and efficient approach to API testing compared to traditional test cases. Thus, the model developed not only conforms to current technological standards but also holds the promise of evolving into an idea of substantial importance in future technological advancements.
Finding fake reviews in e-commerce platforms by using hybrid algorithms
Apr 09, 2024Sentiment analysis, a vital component in natural language processing, plays a crucial role in understanding the underlying emotions and opinions expressed in textual data. In this paper, we propose an innovative ensemble approach for sentiment analysis for finding fake reviews that amalgamate the predictive capabilities of Support Vector Machine (SVM), K-Nearest Neighbors (KNN), and Decision Tree classifiers. Our ensemble architecture strategically combines these diverse models to capitalize on their strengths while mitigating inherent weaknesses, thereby achieving superior accuracy and robustness in fake review prediction. By combining all the models of our classifiers, the predictive performance is boosted and it also fosters adaptability to varied linguistic patterns and nuances present in real-world datasets. The metrics accounted for on fake reviews demonstrate the efficacy and competitiveness of the proposed ensemble method against traditional single-model approaches. Our findings underscore the potential of ensemble techniques in advancing the state-of-the-art in finding fake reviews using hybrid algorithms, with implications for various applications in different social media and e-platforms to find the best reviews and neglect the fake ones, eliminating puffery and bluffs.
Comparative Study and Framework for Automated Summariser Evaluation: LangChain and Hybrid Algorithms
Oct 04, 2023Automated Essay Score (AES) is proven to be one of the cutting-edge technologies. Scoring techniques are used for various purposes. Reliable scores are calculated based on influential variables. Such variables can be computed by different methods based on the domain. The research is concentrated on the user's understanding of a given topic. The analysis is based on a scoring index by using Large Language Models. The user can then compare and contrast the understanding of a topic that they recently learned. The results are then contributed towards learning analytics and progression is made for enhancing the learning ability. In this research, the focus is on summarizing a PDF document and gauging a user's understanding of its content. The process involves utilizing a Langchain tool to summarize the PDF and extract the essential information. By employing this technique, the research aims to determine how well the user comprehends the summarized content.
Payday loans -- blessing or growth suppressor? Machine Learning Analysis
May 30, 2022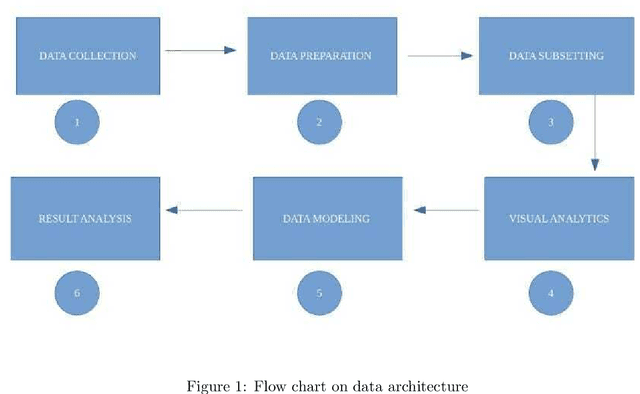
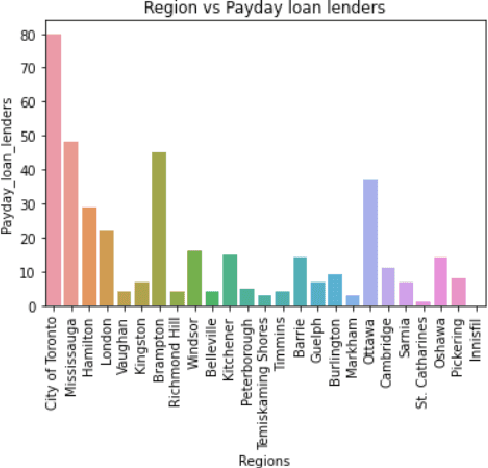
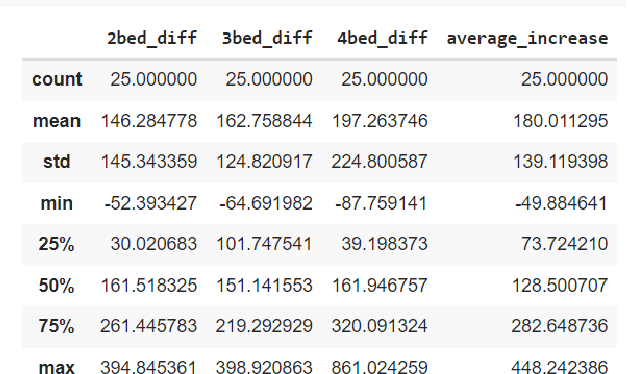
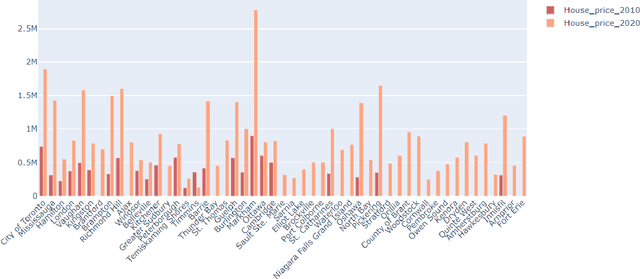
The upsurge of real estate involves a variety of factors that have got influenced by many domains. Indeed, the unrecognized sector that would affect the economy for which regulatory proposals are being drafted to keep this in control is the payday loans. This research paper revolves around the impact of payday loans in the real estate market. The research paper draws a first-hand experience of obtaining the index for the concentration of real estate in an area of reference by virtue of payday loans in Toronto, Ontario in particular, which sets out an ideology to create, evaluate and demonstrate the scenario through research analysis. The purpose of this indexing via payday loans is the basic - debt: income ratio which states that when the income of the person bound to pay the interest of payday loans increases, his debt goes down marginally which hence infers that the person invests in fixed assets like real estate which hikes up its growth.
Turtle Score -- Similarity Based Developer Analyzer
May 10, 2022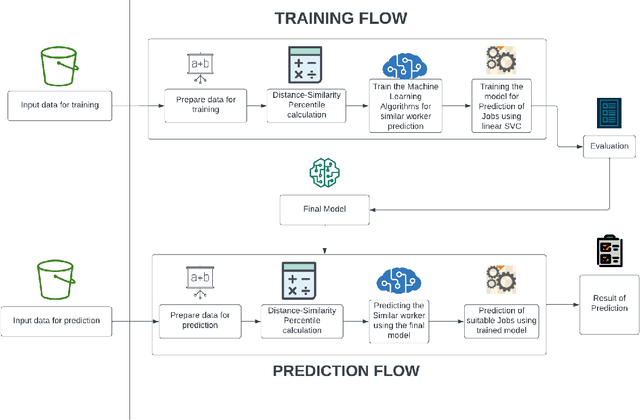
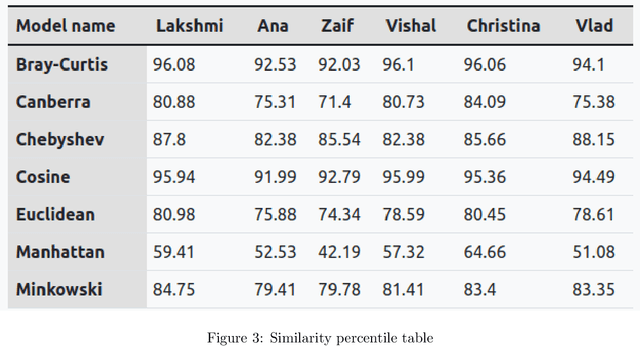
In day-to-day life, a highly demanding task for IT companies is to find the right candidates who fit the companies' culture. This research aims to comprehend, analyze and automatically produce convincing outcomes to find a candidate who perfectly fits right in the company. Data is examined and collected for each employee who works in the IT domain focusing on their performance measure. This is done based on various different categories which bring versatility and a wide view of focus. To this data, learner analysis is done using machine learning algorithms to obtain learner similarity and developer similarity in order to recruit people with identical working patterns. It's been proven that the efficiency and capability of a particular worker go higher when working with a person of a similar personality. Therefore this will serve as a useful tool for recruiters who aim to recruit people with high productivity. This is to say that the model designed will render the best outcome possible with high accuracy and an immaculate recommendation score.
Stack Index Prediction Using Time-Series Analysis
Aug 18, 2021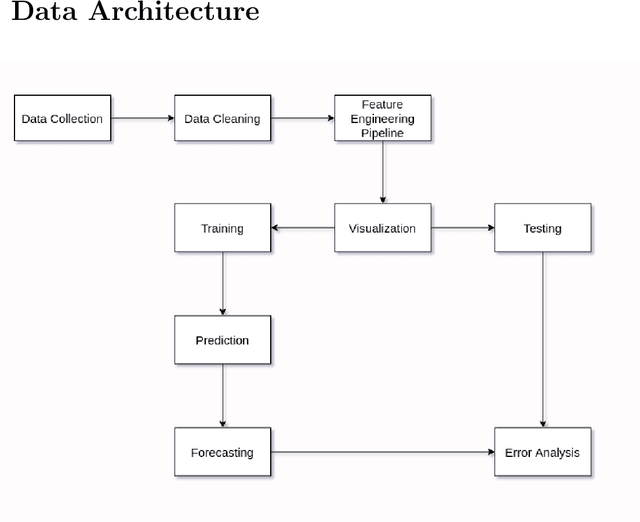
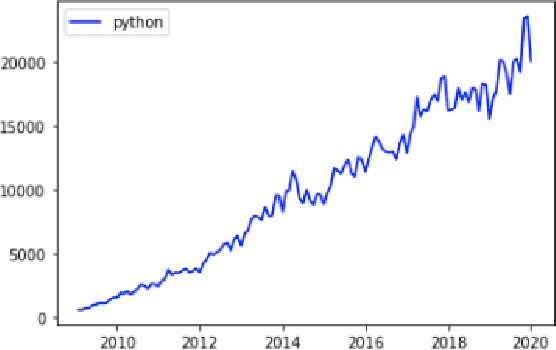
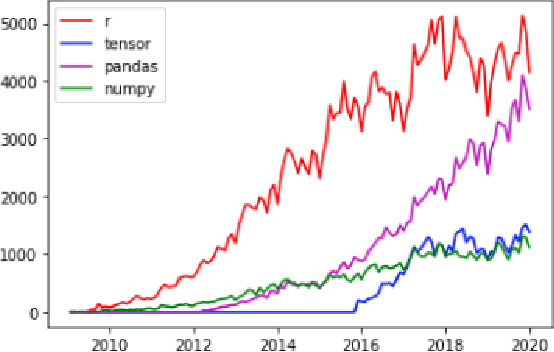
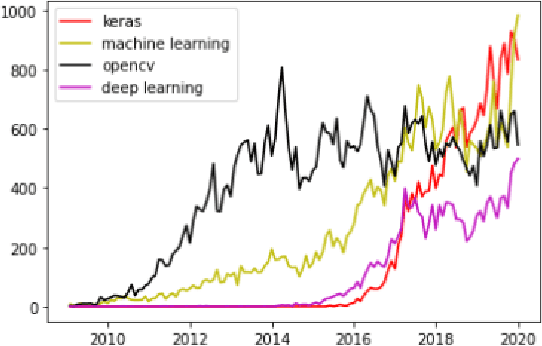
The Prevalence of Community support and engagement for different domains in the tech industry has changed and evolved throughout the years. In this study, we aim to understand, analyze and predict the trends of technology in a scientific manner, having collected data on numerous topics and their growth throughout the years in the past decade. We apply machine learning models on collected data, to understand, analyze and forecast the trends in the advancement of different fields. We show that certain technical concepts such as python, machine learning, and Keras have an undisputed uptrend, finally concluding that the Stackindex model forecasts with high accuracy and can be a viable tool for forecasting different tech domains.