 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplayable Financial Agents: A Determinism-Faithfulness Assurance Harness for Tool-Using LLM Agents
Jan 17, 2026LLM agents struggle with regulatory audit replay: when asked to reproduce a flagged transaction decision with identical inputs, most deployments fail to return consistent results. This paper introduces the Determinism-Faithfulness Assurance Harness (DFAH), a framework for measuring trajectory determinism and evidence-conditioned faithfulness in tool-using agents deployed in financial services. Across 74 configurations (12 models, 4 providers, 8-24 runs each at T=0.0) in non-agentic baseline experiments, 7-20B parameter models achieved 100% determinism, while 120B+ models required 3.7x larger validation samples to achieve equivalent statistical reliability. Agentic tool-use introduces additional variance (see Tables 4-7). Contrary to the assumed reliability-capability trade-off, a positive Pearson correlation emerged (r = 0.45, p < 0.01, n = 51 at T=0.0) between determinism and faithfulness; models producing consistent outputs also tended to be more evidence-aligned. Three financial benchmarks are provided (compliance triage, portfolio constraints, DataOps exceptions; 50 cases each) along with an open-source stress-test harness. In these benchmarks and under DFAH evaluation settings, Tier 1 models with schema-first architectures achieved determinism levels consistent with audit replay requirements.
An Empirical Framework for Evaluating Semantic Preservation Using Hugging Face
Dec 08, 2025



As machine learning (ML) becomes an integral part of high-autonomy systems, it is critical to ensure the trustworthiness of learning-enabled software systems (LESS). Yet, the nondeterministic and run-time-defined semantics of ML complicate traditional software refactoring. We define semantic preservation in LESS as the property that optimizations of intelligent components do not alter the system's overall functional behavior. This paper introduces an empirical framework to evaluate semantic preservation in LESS by mining model evolution data from HuggingFace. We extract commit histories, $\textit{Model Cards}$, and performance metrics from a large number of models. To establish baselines, we conducted case studies in three domains, tracing performance changes across versions. Our analysis demonstrates how $\textit{semantic drift}$ can be detected via evaluation metrics across commits and reveals common refactoring patterns based on commit message analysis. Although API constraints limited the possibility of estimating a full-scale threshold, our pipeline offers a foundation for defining community-accepted boundaries for semantic preservation. Our contributions include: (1) a large-scale dataset of ML model evolution, curated from 1.7 million Hugging Face entries via a reproducible pipeline using the native HF hub API, (2) a practical pipeline for the evaluation of semantic preservation for a subset of 536 models and 4000+ metrics and (3) empirical case studies illustrating semantic drift in practice. Together, these contributions advance the foundations for more maintainable and trustworthy ML systems.
LLM Output Drift: Cross-Provider Validation & Mitigation for Financial Workflows
Nov 10, 2025Financial institutions deploy Large Language Models (LLMs) for reconciliations, regulatory reporting, and client communications, but nondeterministic outputs (output drift) undermine auditability and trust. We quantify drift across five model architectures (7B-120B parameters) on regulated financial tasks, revealing a stark inverse relationship: smaller models (Granite-3-8B, Qwen2.5-7B) achieve 100% output consistency at T=0.0, while GPT-OSS-120B exhibits only 12.5% consistency (95% CI: 3.5-36.0%) regardless of configuration (p<0.0001, Fisher's exact test). This finding challenges conventional assumptions that larger models are universally superior for production deployment. Our contributions include: (i) a finance-calibrated deterministic test harness combining greedy decoding (T=0.0), fixed seeds, and SEC 10-K structure-aware retrieval ordering; (ii) task-specific invariant checking for RAG, JSON, and SQL outputs using finance-calibrated materiality thresholds (plus or minus 5%) and SEC citation validation; (iii) a three-tier model classification system enabling risk-appropriate deployment decisions; and (iv) an audit-ready attestation system with dual-provider validation. We evaluated five models (Qwen2.5-7B via Ollama, Granite-3-8B via IBM watsonx.ai, Llama-3.3-70B, Mistral-Medium-2505, and GPT-OSS-120B) across three regulated financial tasks. Across 480 runs (n=16 per condition), structured tasks (SQL) remain stable even at T=0.2, while RAG tasks show drift (25-75%), revealing task-dependent sensitivity. Cross-provider validation confirms deterministic behavior transfers between local and cloud deployments. We map our framework to Financial Stability Board (FSB), Bank for International Settlements (BIS), and Commodity Futures Trading Commission (CFTC) requirements, demonstrating practical pathways for compliance-ready AI deployments.
Safe Automated Refactoring for Efficient Migration of Imperative Deep Learning Programs to Graph Execution
Apr 07, 2025Efficiency is essential to support responsiveness w.r.t. ever-growing datasets, especially for Deep Learning (DL) systems. DL frameworks have traditionally embraced deferred execution-style DL code -- supporting symbolic, graph-based Deep Neural Network (DNN) computation. While scalable, such development is error-prone, non-intuitive, and difficult to debug. Consequently, more natural, imperative DL frameworks encouraging eager execution have emerged at the expense of run-time performance. Though hybrid approaches aim for the "best of both worlds," using them effectively requires subtle considerations to make code amenable to safe, accurate, and efficient graph execution. We present an automated refactoring approach that assists developers in specifying whether their otherwise eagerly-executed imperative DL code could be reliably and efficiently executed as graphs while preserving semantics. The approach, based on a novel imperative tensor analysis, automatically determines when it is safe and potentially advantageous to migrate imperative DL code to graph execution. The approach is implemented as a PyDev Eclipse IDE plug-in that integrates the WALA Ariadne analysis framework and evaluated on 19 Python projects consisting of 132.05 KLOC. We found that 326 of 766 candidate functions (42.56%) were refactorable, and an average speedup of 2.16 on performance tests was observed. The results indicate that the approach is useful in optimizing imperative DL code to its full potential.
Challenges in Migrating Imperative Deep Learning Programs to Graph Execution: An Empirical Study
Jan 24, 2022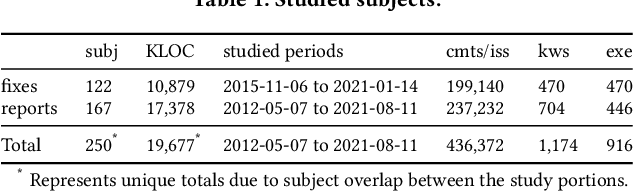
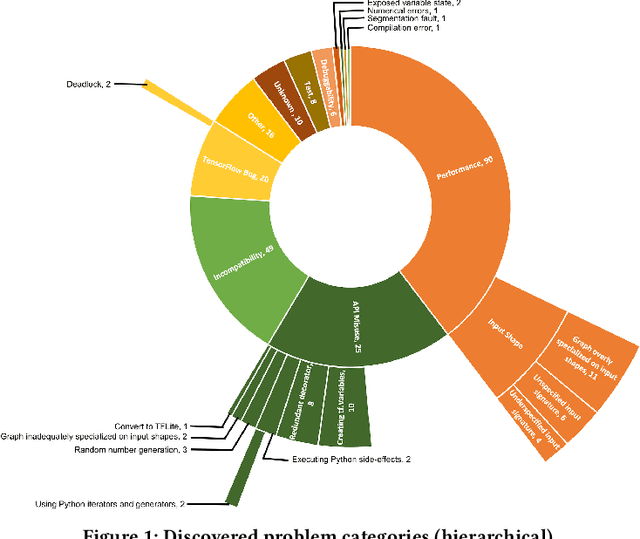
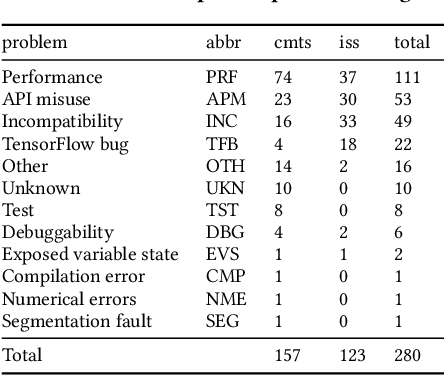

Efficiency is essential to support responsiveness w.r.t. ever-growing datasets, especially for Deep Learning (DL) systems. DL frameworks have traditionally embraced deferred execution-style DL code that supports symbolic, graph-based Deep Neural Network (DNN) computation. While scalable, such development tends to produce DL code that is error-prone, non-intuitive, and difficult to debug. Consequently, more natural, less error-prone imperative DL frameworks encouraging eager execution have emerged but at the expense of run-time performance. While hybrid approaches aim for the "best of both worlds," the challenges in applying them in the real world are largely unknown. We conduct a data-driven analysis of challenges -- and resultant bugs -- involved in writing reliable yet performant imperative DL code by studying 250 open-source projects, consisting of 19.7 MLOC, along with 470 and 446 manually examined code patches and bug reports, respectively. The results indicate that hybridization: (i) is prone to API misuse, (ii) can result in performance degradation -- the opposite of its intention, and (iii) has limited application due to execution mode incompatibility. We put forth several recommendations, best practices, and anti-patterns for effectively hybridizing imperative DL code, potentially benefiting DL practitioners, API designers, tool developers, and educators.