 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRRULES: An improvement of the RULES rule-based classifier
Jun 14, 2021
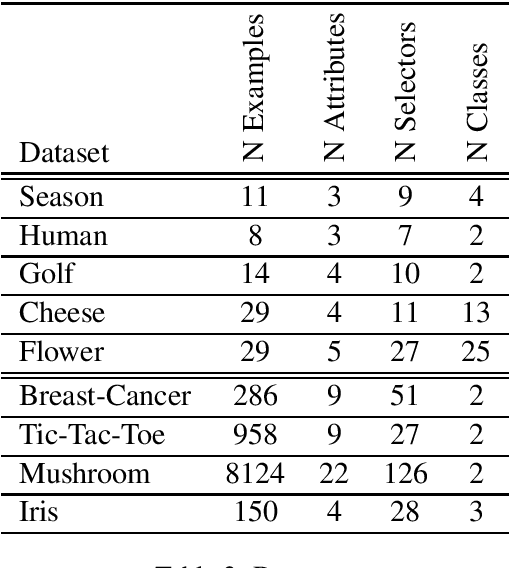
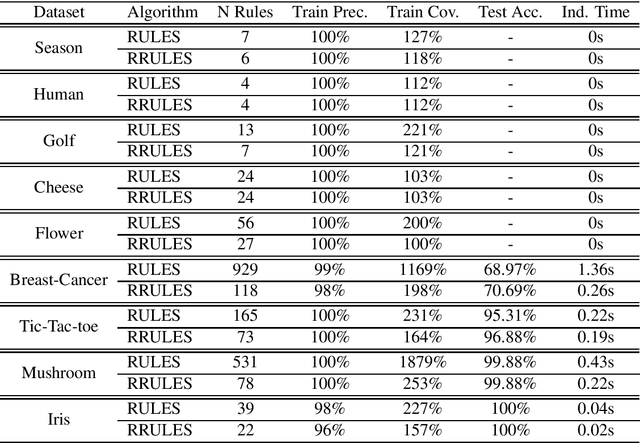
RRULES is presented as an improvement and optimization over RULES, a simple inductive learning algorithm for extracting IF-THEN rules from a set of training examples. RRULES optimizes the algorithm by implementing a more effective mechanism to detect irrelevant rules, at the same time that checks the stopping conditions more often. This results in a more compact rule set containing more general rules which prevent overfitting the training set and obtain a higher test accuracy. Moreover, the results show that RRULES outperforms the original algorithm by reducing the coverage rate up to a factor of 7 while running twice or three times faster consistently over several datasets.
HLE-UPC at SemEval-2021 Task 5: Multi-Depth DistilBERT for Toxic Spans Detection
Apr 09, 2021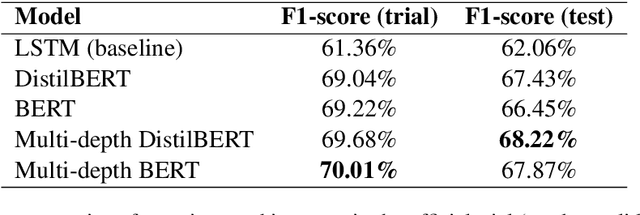
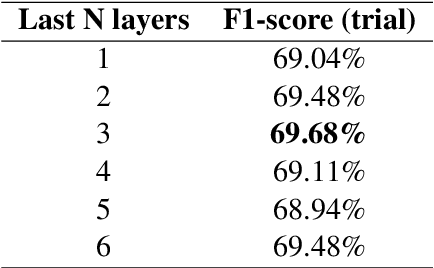

This paper presents our submission to SemEval-2021 Task 5: Toxic Spans Detection. The purpose of this task is to detect the spans that make a text toxic, which is a complex labour for several reasons. Firstly, because of the intrinsic subjectivity of toxicity, and secondly, due to toxicity not always coming from single words like insults or offends, but sometimes from whole expressions formed by words that may not be toxic individually. Following this idea of focusing on both single words and multi-word expressions, we study the impact of using a multi-depth DistilBERT model, which uses embeddings from different layers to estimate the final per-token toxicity. Our quantitative results show that using information from multiple depths boosts the performance of the model. Finally, we also analyze our best model qualitatively.