 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding learning from EEG data: Combining machine learning and feature engineering based on hidden Markov models and mixed models
Nov 14, 2023Theta oscillations, ranging from 4-8 Hz, play a significant role in spatial learning and memory functions during navigation tasks. Frontal theta oscillations are thought to play an important role in spatial navigation and memory. Electroencephalography (EEG) datasets are very complex, making any changes in the neural signal related to behaviour difficult to interpret. However, multiple analytical methods are available to examine complex data structure, especially machine learning based techniques. These methods have shown high classification performance and the combination with feature engineering enhances the capability of these methods. This paper proposes using hidden Markov and linear mixed effects models to extract features from EEG data. Based on the engineered features obtained from frontal theta EEG data during a spatial navigation task in two key trials (first, last) and between two conditions (learner and non-learner), we analysed the performance of six machine learning methods (Polynomial Support Vector Machines, Non-linear Support Vector Machines, Random Forests, K-Nearest Neighbours, Ridge, and Deep Neural Networks) on classifying learner and non-learner participants. We also analysed how different standardisation methods used to pre-process the EEG data contribute to classification performance. We compared the classification performance of each trial with data gathered from the same subjects, including solely coordinate-based features, such as idle time and average speed. We found that more machine learning methods perform better classification using coordinate-based data. However, only deep neural networks achieved an area under the ROC curve higher than 80% using the theta EEG data alone. Our findings suggest that standardising the theta EEG data and using deep neural networks enhances the classification of learner and non-learner subjects in a spatial learning task.
Frame by frame completion probability of an NFL pass
Sep 16, 2021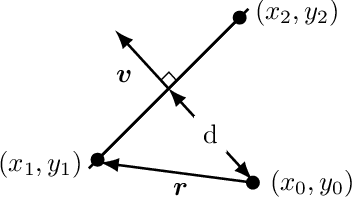

American football is an increasingly popular sport, with a growing audience in many countries in the world. The most watched American football league in the world is the United States' National Football League (NFL), where every offensive play can be either a run or a pass, and in this work we focus on passes. Many factors can affect the probability of pass completion, such as receiver separation from the nearest defender, distance from receiver to passer, offense formation, among many others. When predicting the completion probability of a pass, it is essential to know who the target of the pass is. By using distance measures between players and the ball, it is possible to calculate empirical probabilities and predict very accurately who the target will be. The big question is: how likely is it for a pass to be completed in an NFL match while the ball is in the air? We developed a machine learning algorithm to answer this based on several predictors. Using data from the 2018 NFL season, we obtained conditional and marginal predictions for pass completion probability based on a random forest model. This is based on a two-stage procedure: first, we calculate the probability of each offensive player being the pass target, then, conditional on the target, we predict completion probability based on the random forest model. Finally, the general completion probability can be calculated using the law of total probability. We present animations for selected plays and show the pass completion probability evolution.