 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuPEr-SAM: Using the Supervision Signal from a Pose Estimator to Train a Spatial Attention Module for Personal Protective Equipment Recognition
Sep 25, 2020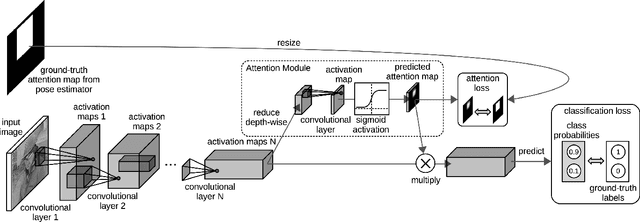
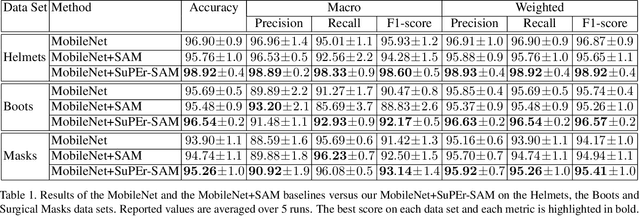
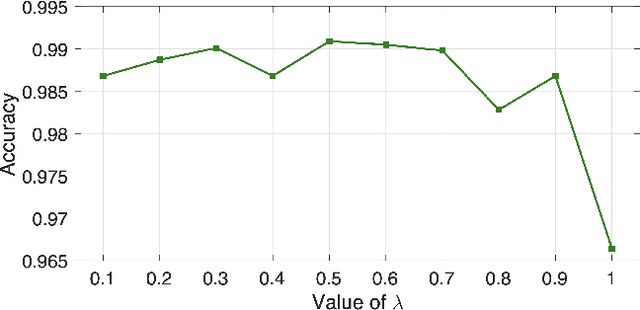
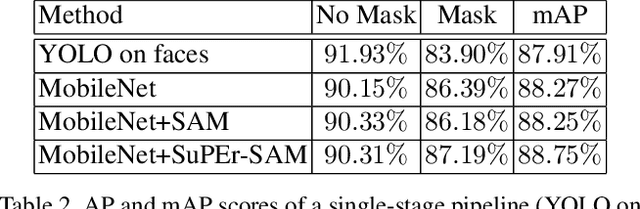
We propose a deep learning method to automatically detect personal protective equipment (PPE), such as helmets, surgical masks, reflective vests, boots and so on, in images of people. Typical approaches for PPE detection based on deep learning are (i) to train an object detector for items such as those listed above or (ii) to train a person detector and a classifier that takes the bounding boxes predicted by the detector and discriminates between people wearing and people not wearing the corresponding PPE items. We propose a novel and accurate approach that uses three components: a person detector, a body pose estimator and a classifier. Our novelty consists in using the pose estimator only at training time, to improve the prediction performance of the classifier. We modify the neural architecture of the classifier by adding a spatial attention mechanism, which is trained using supervision signal from the pose estimator. In this way, the classifier learns to focus on PPE items, using knowledge from the pose estimator with almost no computational overhead during inference.
Adversarial Attacks on Deep Learning Systems for User Identification based on Motion Sensors
Sep 02, 2020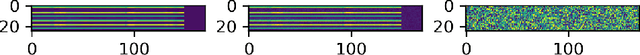
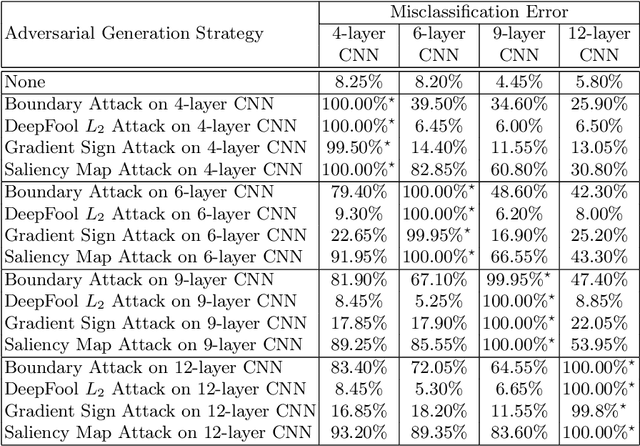
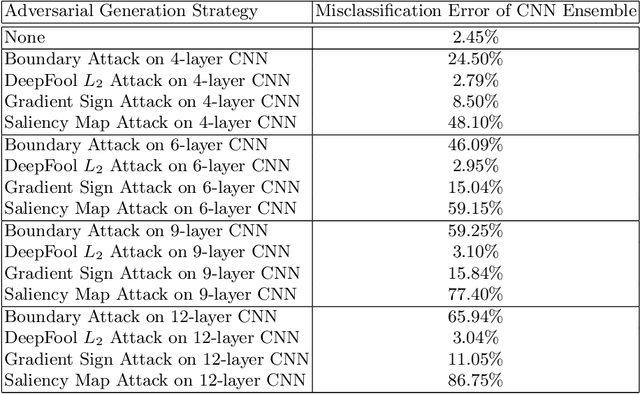
For the time being, mobile devices employ implicit authentication mechanisms, namely, unlock patterns, PINs or biometric-based systems such as fingerprint or face recognition. While these systems are prone to well-known attacks, the introduction of an explicit and unobtrusive authentication layer can greatly enhance security. In this study, we focus on deep learning methods for explicit authentication based on motion sensor signals. In this scenario, attackers could craft adversarial examples with the aim of gaining unauthorized access and even restraining a legitimate user to access his mobile device. To our knowledge, this is the first study that aims at quantifying the impact of adversarial attacks on machine learning models used for user identification based on motion sensors. To accomplish our goal, we study multiple methods for generating adversarial examples. We propose three research questions regarding the impact and the universality of adversarial examples, conducting relevant experiments in order to answer our research questions. Our empirical results demonstrate that certain adversarial example generation methods are specific to the attacked classification model, while others tend to be generic. We thus conclude that deep neural networks trained for user identification tasks based on motion sensors are subject to a high percentage of misclassification when given adversarial input.
To augment or not to augment? Data augmentation in user identification based on motion sensors
Sep 01, 2020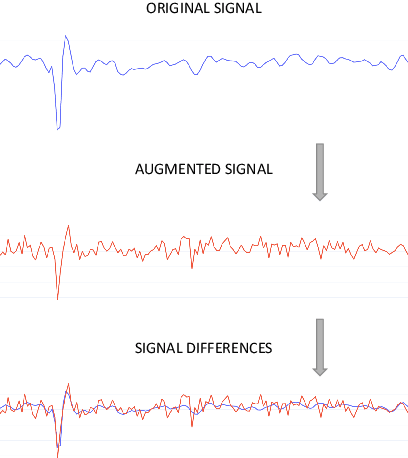
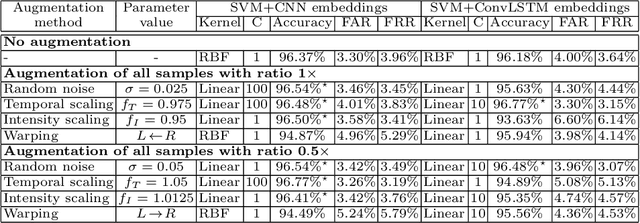
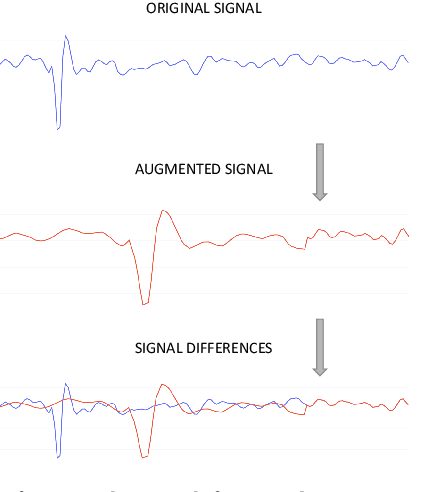
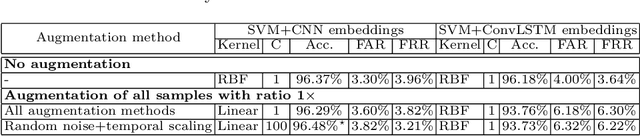
Nowadays, commonly-used authentication systems for mobile device users, e.g. password checking, face recognition or fingerprint scanning, are susceptible to various kinds of attacks. In order to prevent some of the possible attacks, these explicit authentication systems can be enhanced by considering a two-factor authentication scheme, in which the second factor is an implicit authentication system based on analyzing motion sensor data captured by accelerometers or gyroscopes. In order to avoid any additional burdens to the user, the registration process of the implicit authentication system must be performed quickly, i.e. the number of data samples collected from the user is typically small. In the context of designing a machine learning model for implicit user authentication based on motion signals, data augmentation can play an important role. In this paper, we study several data augmentation techniques in the quest of finding useful augmentation methods for motion sensor data. We propose a set of four research questions related to data augmentation in the context of few-shot user identification based on motion sensor signals. We conduct experiments on a benchmark data set, using two deep learning architectures, convolutional neural networks and Long Short-Term Memory networks, showing which and when data augmentation methods bring accuracy improvements. Interestingly, we find that data augmentation is not very helpful, most likely because the signal patterns useful to discriminate users are too sensitive to the transformations brought by certain data augmentation techniques. This result is somewhat contradictory to the common belief that data augmentation is expected to increase the accuracy of machine learning models.
A Scene-Agnostic Framework with Adversarial Training for Abnormal Event Detection in Video
Aug 27, 2020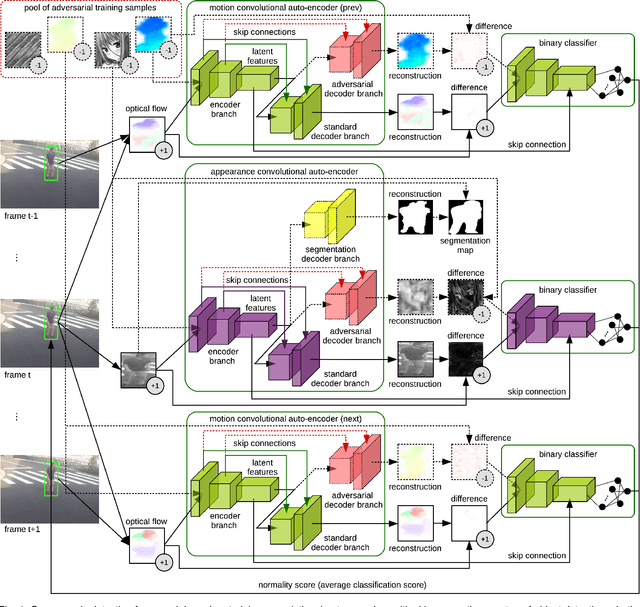
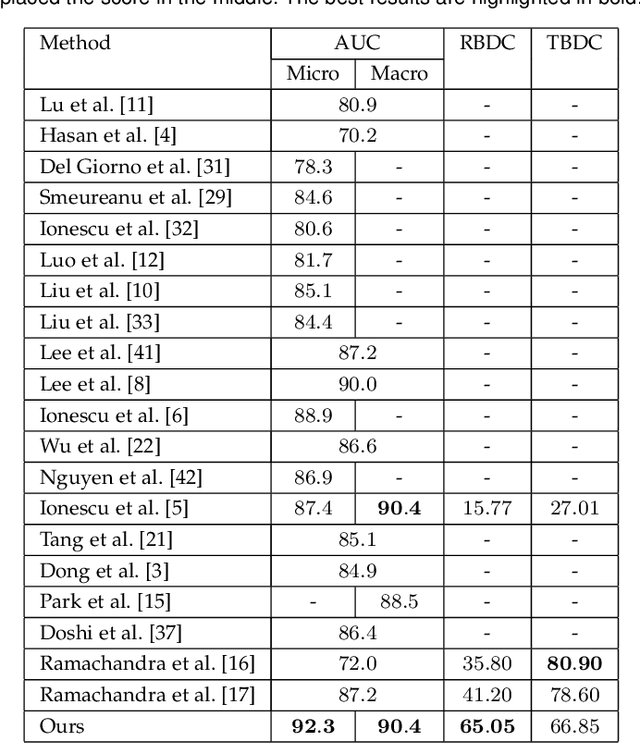

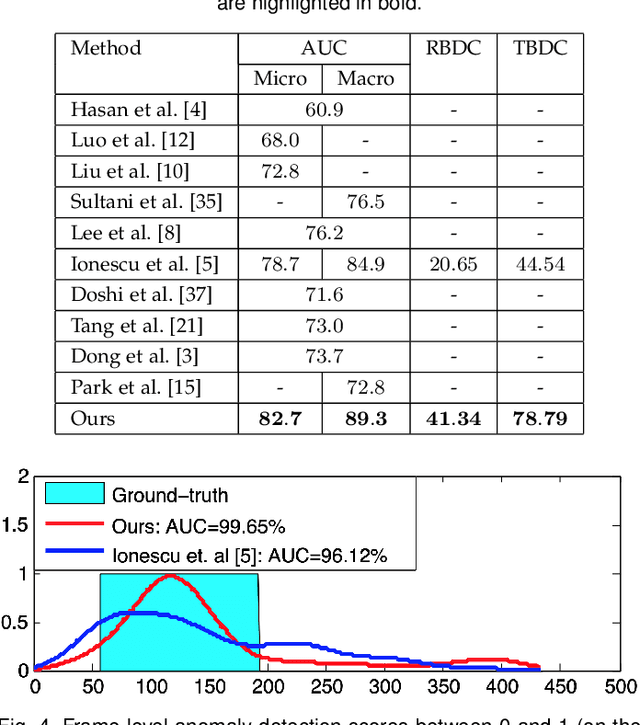
Abnormal event detection in video is a complex computer vision problem that has attracted significant attention in recent years. The complexity of the task arises from the commonly-agreed definition of an abnormal event, that is, a rarely occurring event that typically depends on the surrounding context. Following the standard formulation of abnormal event detection as outlier detection, we propose a scene-agnostic framework that learns from training videos containing only normal events. Our framework is composed of an object detector, a set of appearance and motion auto-encoders, and a discriminator. Since our framework only looks at object detections, it can be applied to different scenes, provided that abnormal events are defined identically across scenes. This makes our method scene agnostic, as we rely strictly on objects that can cause anomalies, and not on the background. To overcome the lack of abnormal data during training, we propose an adversarial learning strategy for the auto-encoders. We create a scene-agnostic set of out-of-domain adversarial examples, which are correctly reconstructed by the auto-encoders before applying gradient ascent on the adversarial examples. We further utilize the adversarial examples to serve as abnormal examples when training a binary classifier to discriminate between normal and abnormal latent features and reconstructions. Furthermore, to ensure that the auto-encoders focus only on the main object inside each bounding box image, we introduce a branch that learns to segment the main object. We compare our framework with the state-of-the-art methods on three benchmark data sets, using various evaluation metrics. Compared to existing methods, the empirical results indicate that our approach achieves favorable performance on all data sets.
Estimating Magnitude and Phase of Automotive Radar Signals under Multiple Interference Sources with Fully Convolutional Networks
Aug 11, 2020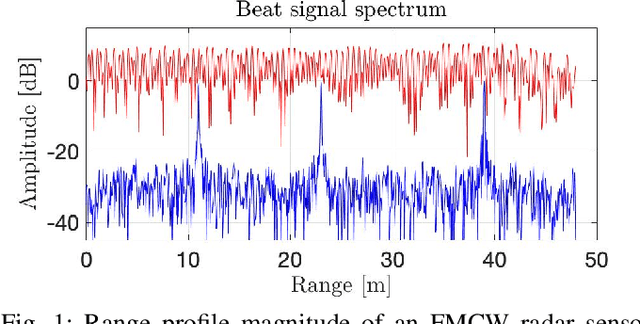
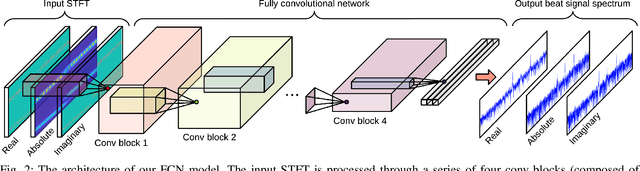
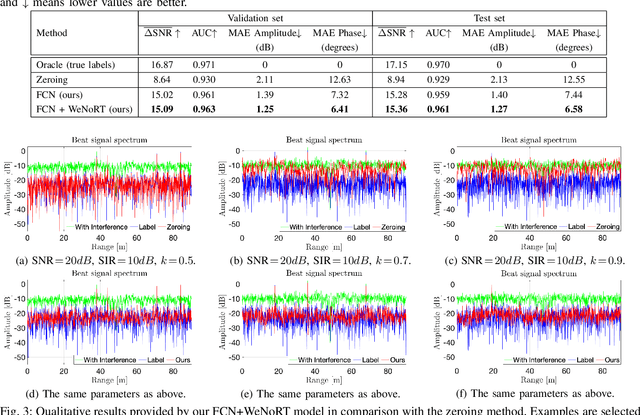
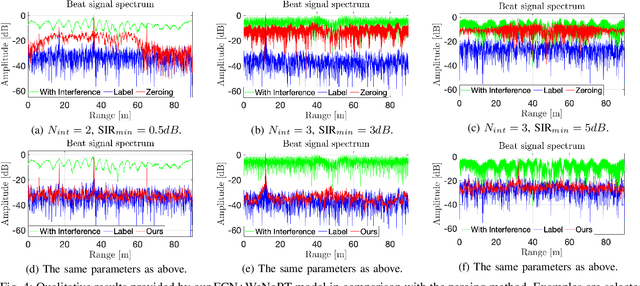
Radar sensors are gradually becoming a wide-spread equipment for road vehicles, playing a crucial role in autonomous driving and road safety. The broad adoption of radar sensors increases the chance of interference among sensors from different vehicles, generating corrupted range profiles and range-Doppler maps. In order to extract distance and velocity of multiple targets from range-Doppler maps, the interference affecting each range profile needs to be mitigated. In this paper, we propose a fully convolutional neural network for automotive radar interference mitigation. In order to train our network in a real-world scenario, we introduce a new data set of realistic automotive radar signals with multiple targets and multiple interferers. To our knowledge, this is the first work to mitigate interference from multiple sources. Furthermore, we introduce a new training regime that eliminates noisy weights, showing superior results compared to the widely-used dropout. While some previous works successfully estimated the magnitude of automotive radar signals, we are the first to propose a deep learning model that can accurately estimate the phase. For instance, our novel approach reduces the phase estimation error with respect to the commonly-adopted zeroing technique by half, from 12.55 degrees to 6.58 degrees. Considering the lack of databases for automotive radar interference mitigation, we release as open source our large-scale data set that closely replicates the real-world automotive scenario for multiple interference cases, allowing others to objectively compare their future work in this domain. Our data set is available for download at: http://github.com/ristea/arim-v2.
Teacher-Student Training and Triplet Loss for Facial Expression Recognition under Occlusion
Aug 03, 2020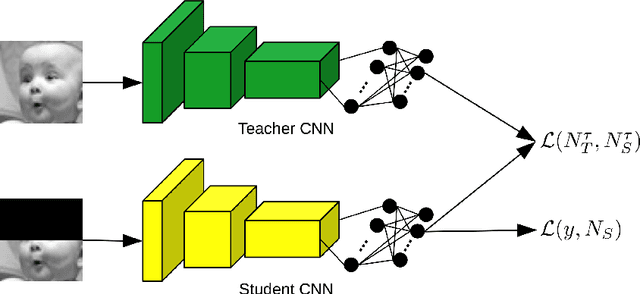
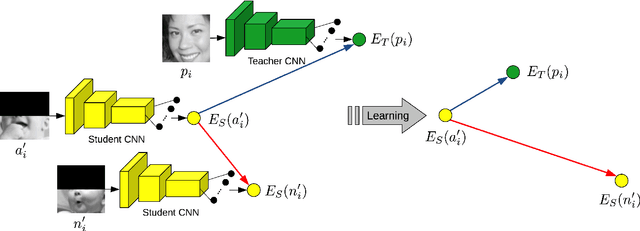
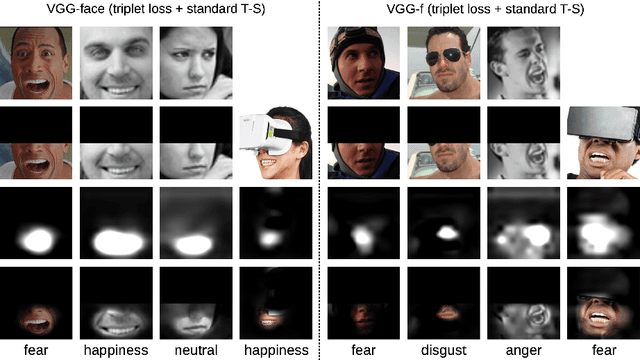
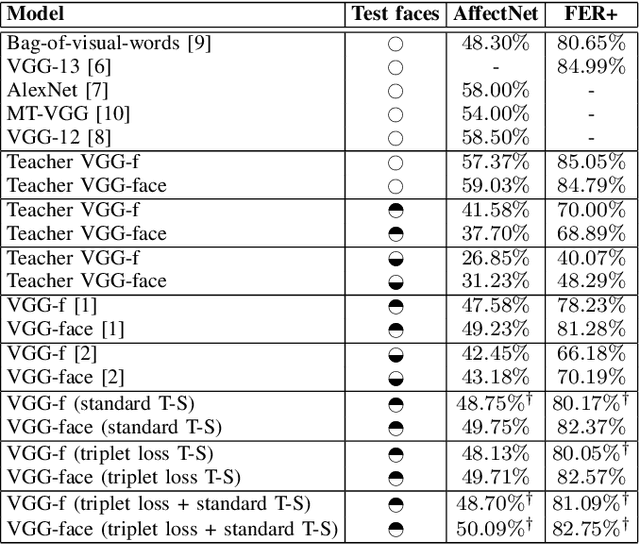
In this paper, we study the task of facial expression recognition under strong occlusion. We are particularly interested in cases where 50% of the face is occluded, e.g. when the subject wears a Virtual Reality (VR) headset. While previous studies show that pre-training convolutional neural networks (CNNs) on fully-visible (non-occluded) faces improves the accuracy, we propose to employ knowledge distillation to achieve further improvements. First of all, we employ the classic teacher-student training strategy, in which the teacher is a CNN trained on fully-visible faces and the student is a CNN trained on occluded faces. Second of all, we propose a new approach for knowledge distillation based on triplet loss. During training, the goal is to reduce the distance between an anchor embedding, produced by a student CNN that takes occluded faces as input, and a positive embedding (from the same class as the anchor), produced by a teacher CNN trained on fully-visible faces, so that it becomes smaller than the distance between the anchor and a negative embedding (from a different class than the anchor), produced by the student CNN. Third of all, we propose to combine the distilled embeddings obtained through the classic teacher-student strategy and our novel teacher-student strategy based on triplet loss into a single embedding vector. We conduct experiments on two benchmarks, FER+ and AffectNet, with two CNN architectures, VGG-f and VGG-face, showing that knowledge distillation can bring significant improvements over the state-of-the-art methods designed for occluded faces in the VR setting.
Accurate and Efficient Intracranial Hemorrhage Detection and Subtype Classification in 3D CT Scans with Convolutional and Long Short-Term Memory Neural Networks
Aug 01, 2020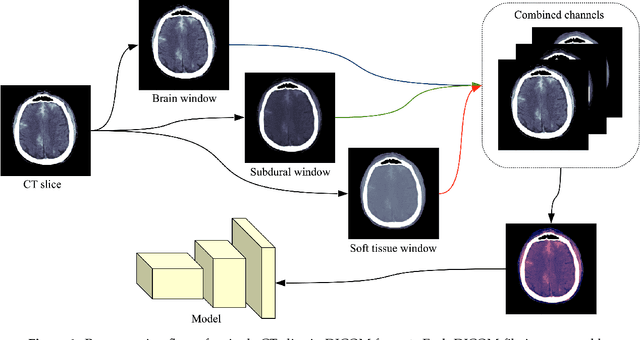
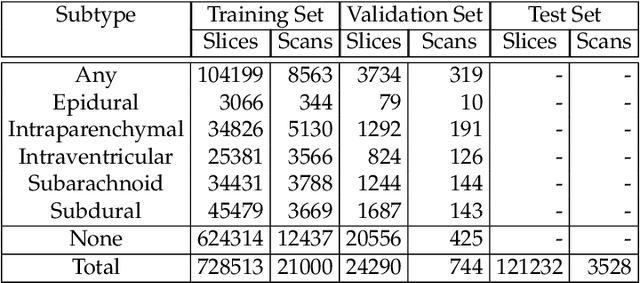
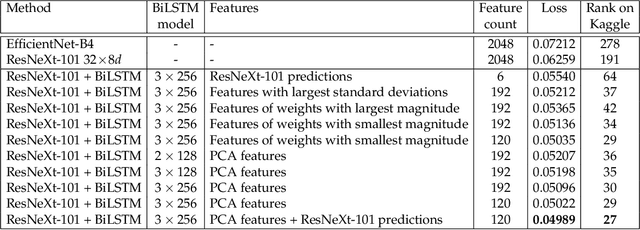
In this paper, we present our system for the RSNA Intracranial Hemorrhage Detection challenge. The proposed system is based on a lightweight deep neural network architecture composed of a convolutional neural network (CNN) that takes as input individual CT slices, and a Long Short-Term Memory (LSTM) network that takes as input feature embeddings provided by the CNN. For efficient processing, we consider various feature selection methods to produce a subset of useful CNN features for the LSTM. Furthermore, we reduce the CT slices by a factor of 2x, allowing ourselves to train the model faster. Even if our model is designed to balance speed and accuracy, we report a weighted mean log loss of 0.04989 on the final test set, which places us in the top 30 ranking (2%) from a total of 1345 participants. Although our computing infrastructure does not allow it, processing CT slices at their original scale is likely to improve performance. In order to enable others to reproduce our results, we provide our code as open source at https://github.com/warchildmd/ihd. After the challenge, we conducted a subjective intracranial hemorrhage detection assessment by radiologists, indicating that the performance of our deep model is on par with that of doctors specialized in reading CT scans. Another contribution of our work is to integrate Grad-CAM visualizations in our system, providing useful explanations for its predictions. We therefore consider our system as a viable option when a fast diagnosis or a second opinion on intracranial hemorrhage detection are needed.
The Unreasonable Effectiveness of Machine Learning in Moldavian versus Romanian Dialect Identification
Jul 30, 2020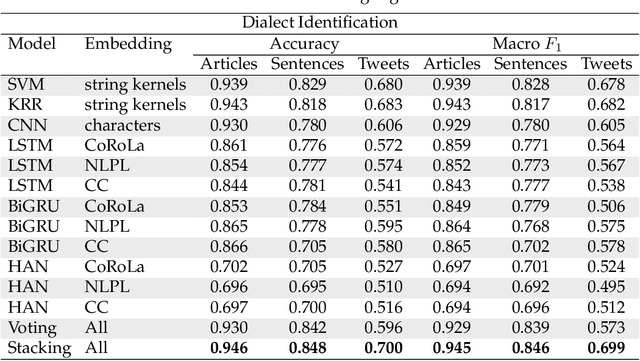
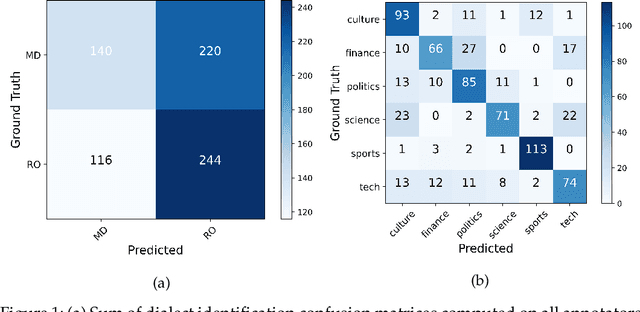
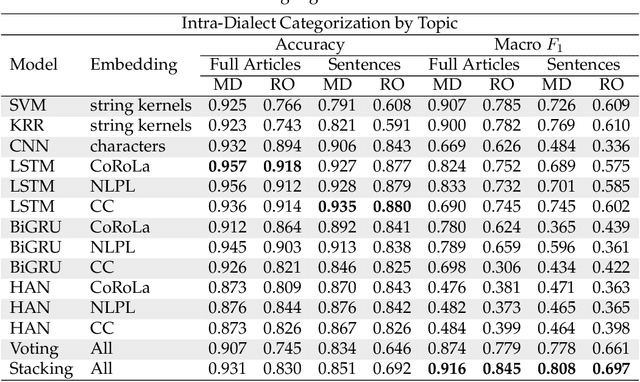
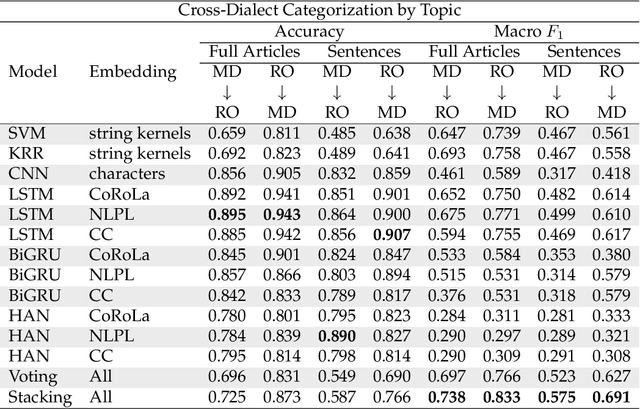
In this work, we provide a follow-up on the Moldavian versus Romanian Cross-Dialect Topic Identification (MRC) shared task of the VarDial 2019 Evaluation Campaign. The shared task included two sub-task types: one that consisted in discriminating between the Moldavian and the Romanian dialects and one that consisted in classifying documents by topic across the two dialects of Romanian. Participants achieved impressive scores, e.g. the top model for Moldavian versus Romanian dialect identification obtained a macro F1 score of 0.895. We conduct a subjective evaluation by human annotators, showing that humans attain much lower accuracy rates compared to machine learning (ML) models. Hence, it remains unclear why the methods proposed by participants attain such high accuracy rates. Our goal is to understand (i) why the proposed methods work so well (by visualizing the discriminative features) and (ii) to what extent these methods can keep their high accuracy levels, e.g. when we shorten the text samples to single sentences or when use tweets at inference time. A secondary goal of our work is to propose an improved ML model using ensemble learning. Our experiments show that ML models can accurately identify the dialects, even at the sentence level and across different domains (news articles versus tweets). We also analyze the most discriminative features of the best performing models, providing some explanations behind the decisions taken by these models. Interestingly, we learn new dialectal patterns previously unknown to us or to our human annotators. Furthermore, we conduct experiments showing that the machine learning performance on the MRC shared task can be improved through an ensemble based on classifier stacking.
A Generic and Model-Agnostic Exemplar Synthetization Framework for Explainable AI
Jul 01, 2020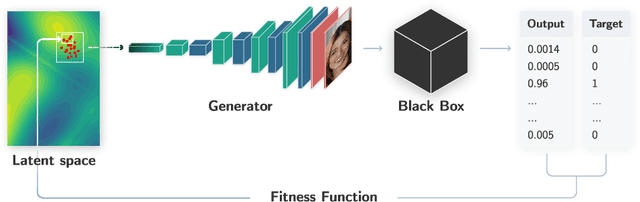
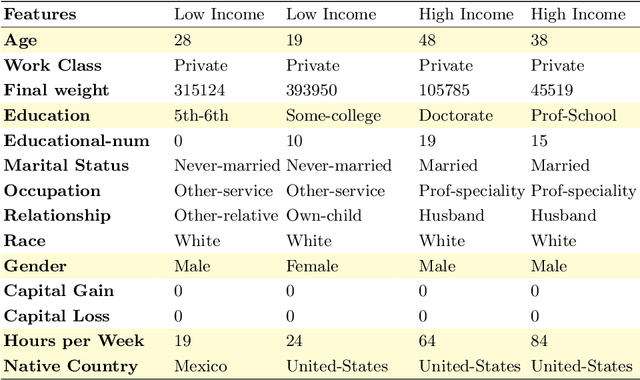


With the growing complexity of deep learning methods adopted in practical applications, there is an increasing and stringent need to explain and interpret the decisions of such methods. In this work, we focus on explainable AI and propose a novel generic and model-agnostic framework for synthesizing input exemplars that maximize a desired response from a machine learning model. To this end, we use a generative model, which acts as a prior for generating data, and traverse its latent space using a novel evolutionary strategy with momentum updates. Our framework is generic because (i) it can employ any underlying generator, e.g. Variational Auto-Encoders (VAEs) or Generative Adversarial Networks (GANs), and (ii) it can be applied to any input data, e.g. images, text samples or tabular data. Since we use a zero-order optimization method, our framework is model-agnostic, in the sense that the machine learning model that we aim to explain is a black-box. We stress out that our novel framework does not require access or knowledge of the internal structure or the training data of the black-box model. We conduct experiments with two generative models, VAEs and GANs, and synthesize exemplars for various data formats, image, text and tabular, demonstrating that our framework is generic. We also employ our prototype synthetization framework on various black-box models, for which we only know the input and the output formats, showing that it is model-agnostic. Moreover, we compare our framework (available at https://github.com/antoniobarbalau/exemplar) with a model-dependent approach based on gradient descent, proving that our framework obtains equally-good exemplars in a shorter computational time.
Are you wearing a mask? Improving mask detection from speech using augmentation by cycle-consistent GANs
Jun 17, 2020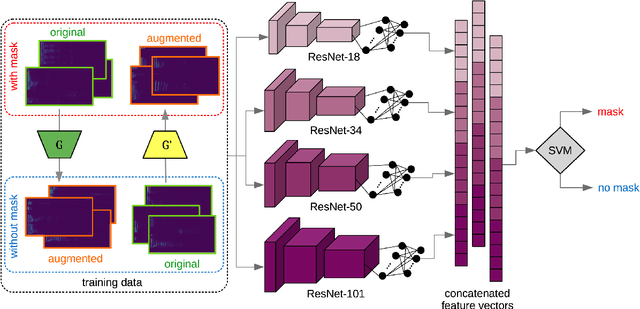
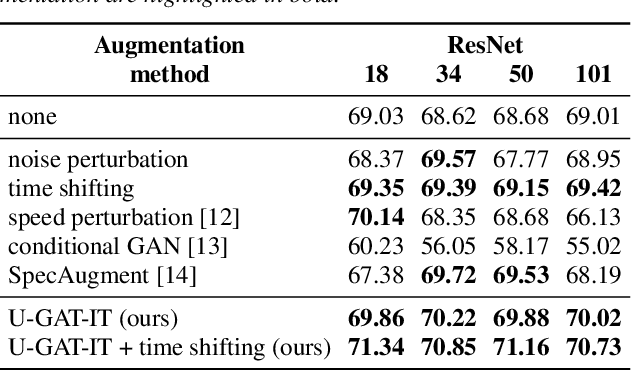
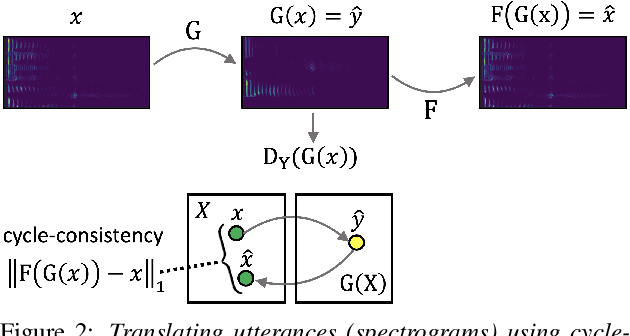

The task of detecting whether a person wears a face mask from speech is useful in modelling speech in forensic investigations, communication between surgeons or people protecting themselves against infectious diseases such as COVID-19. In this paper, we propose a novel data augmentation approach for mask detection from speech. Our approach is based on (i) training Generative Adversarial Networks (GANs) with cycle-consistency loss to translate unpaired utterances between two classes (with mask and without mask), and on (ii) generating new training utterances using the cycle-consistent GANs, assigning opposite labels to each translated utterance. Original and translated utterances are converted into spectrograms which are provided as input to a set of ResNet neural networks with various depths. The networks are combined into an ensemble through a Support Vector Machines (SVM) classifier. With this system, we participated in the Mask Sub-Challenge (MSC) of the INTERSPEECH 2020 Computational Paralinguistics Challenge, surpassing the baseline proposed by the organizers by 2.8%. Our data augmentation technique provided a performance boost of 0.9% on the private test set. Furthermore, we show that our data augmentation approach yields better results than other baseline and state-of-the-art augmentation methods.