 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffect in Tweets Using Experts Model
Mar 20, 2019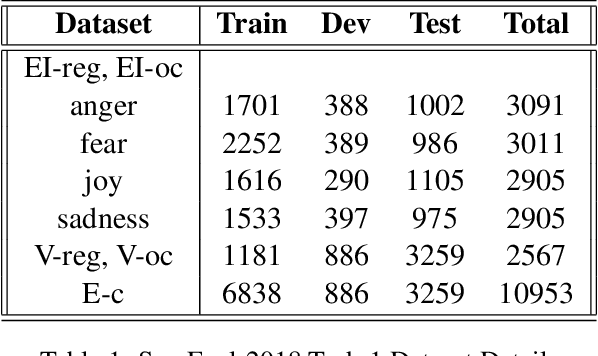
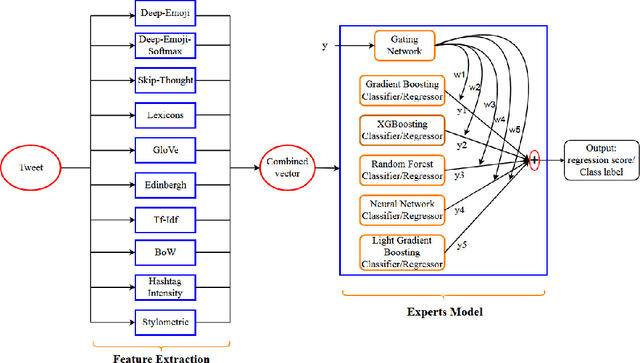
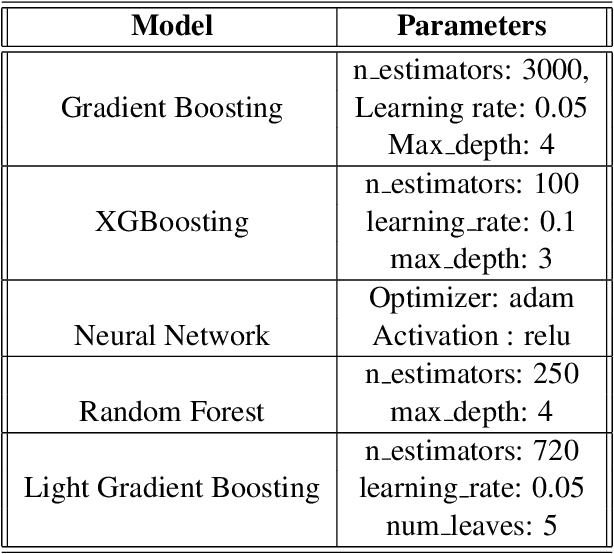
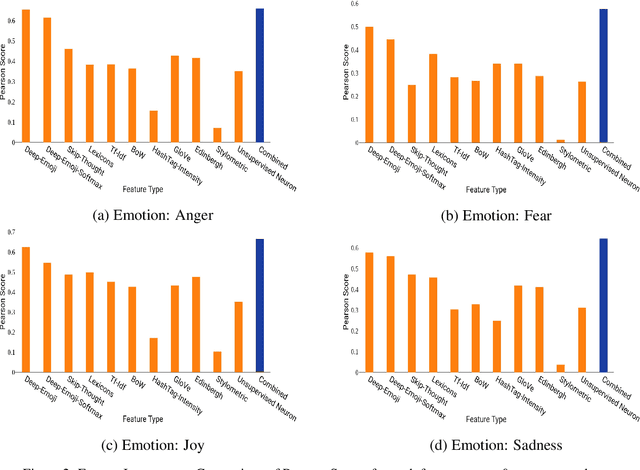
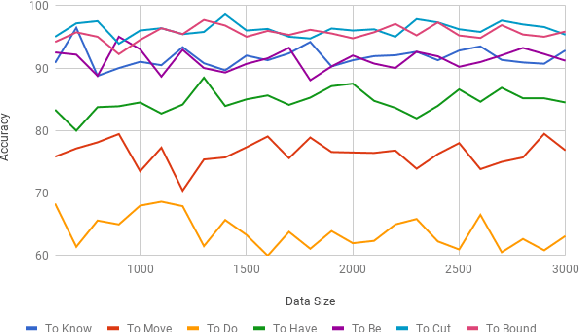
Estimating the intensity of emotion has gained significance as modern textual inputs in potential applications like social media, e-retail markets, psychology, advertisements etc., carry a lot of emotions, feelings, expressions along with its meaning. However, the approaches of traditional sentiment analysis primarily focuses on classifying the sentiment in general (positive or negative) or at an aspect level(very positive, low negative, etc.) and cannot exploit the intensity information. Moreover, automatically identifying emotions like anger, fear, joy, sadness, disgust etc., from text introduces challenging scenarios where single tweet may contain multiple emotions with different intensities and some emotions may even co-occur in some of the tweets. In this paper, we propose an architecture, Experts Model, inspired from the standard Mixture of Experts (MoE) model. The key idea here is each expert learns different sets of features from the feature vector which helps in better emotion detection from the tweet. We compared the results of our Experts Model with both baseline results and top five performers of SemEval-2018 Task-1, Affect in Tweets (AIT). The experimental results show that our proposed approach deals with the emotion detection problem and stands at top-5 results.
Towards Enhancing Lexical Resource and Using Sense-annotations of OntoSenseNet for Sentiment Analysis
Jul 25, 2018
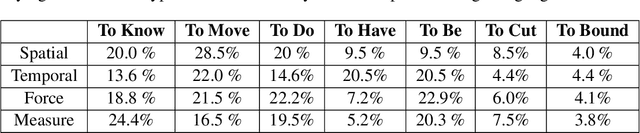
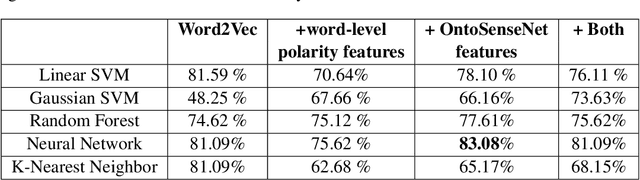
This paper illustrates the interface of the tool we developed for crowd sourcing and we explain the annotation procedure in detail. Our tool is named as 'Parupalli Padajaalam' which means web of words by Parupalli. The aim of this tool is to populate the OntoSenseNet, sentiment polarity annotated Telugu resource. Recent works have shown the importance of word-level annotations on sentiment analysis. With this as basis, we aim to analyze the importance of sense-annotations obtained from OntoSenseNet in performing the task of sentiment analysis. We explain the fea- tures extracted from OntoSenseNet (Telugu). Furthermore we compute and explain the adverbial class distribution of verbs in OntoSenseNet. This task is known to aid in disambiguating word-senses which helps in enhancing the performance of word-sense disambiguation (WSD) task(s).
BCSAT : A Benchmark Corpus for Sentiment Analysis in Telugu Using Word-level Annotations
Jul 04, 2018
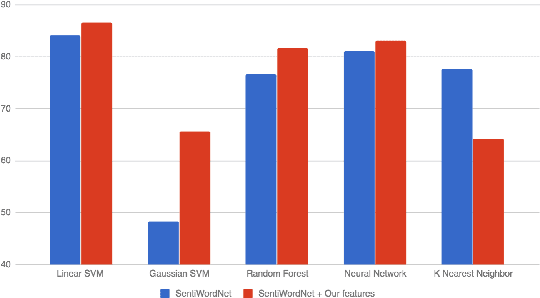

The presented work aims at generating a systematically annotated corpus that can support the enhancement of sentiment analysis tasks in Telugu using word-level sentiment annotations. From OntoSenseNet, we extracted 11,000 adjectives, 253 adverbs, 8483 verbs and sentiment annotation is being done by language experts. We discuss the methodology followed for the polarity annotations and validate the developed resource. This work aims at developing a benchmark corpus, as an extension to SentiWordNet, and baseline accuracy for a model where lexeme annotations are applied for sentiment predictions. The fundamental aim of this paper is to validate and study the possibility of utilizing machine learning algorithms, word-level sentiment annotations in the task of automated sentiment identification. Furthermore, accuracy is improved by annotating the bi-grams extracted from the target corpus.
Towards Automation of Sense-type Identification of Verbs in OntoSenseNet(Telugu)
Jul 04, 2018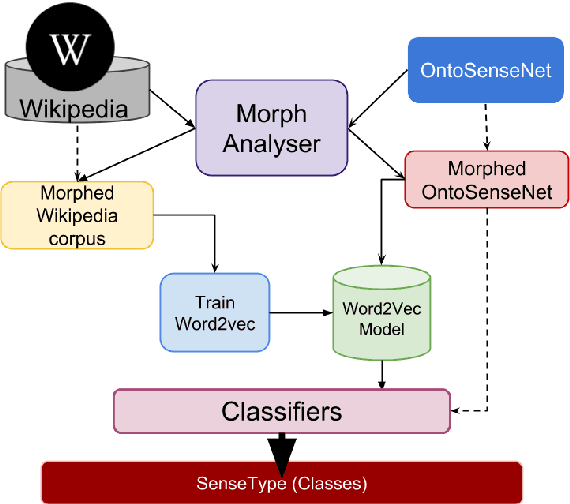
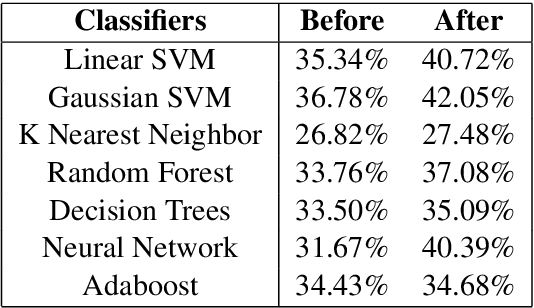
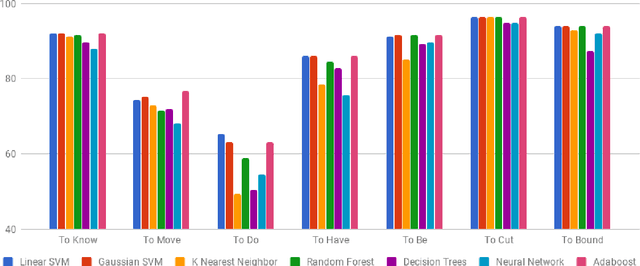
In this paper, we discuss the enrichment of a manually developed resource of Telugu lexicon, OntoSenseNet. OntoSenseNet is a ontological sense annotated lexicon that marks each verb of Telugu with a primary and a secondary sense. The area of research is relatively recent but has a large scope of development. We provide an introductory work to enrich the OntoSenseNet to promote further research in Telugu. Classifiers are adopted to learn the sense relevant features of the words in the resource and also to automate the tagging of sense-types for verbs. We perform a comparative analysis of different classifiers applied on OntoSenseNet. The results of the experiment prove that automated enrichment of the resource is effective using SVM classifiers and Adaboost ensemble.
Automatic Target Recovery for Hindi-English Code Mixed Puns
Jun 11, 2018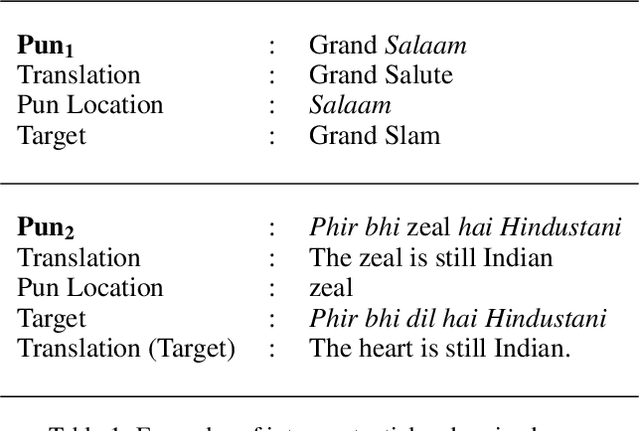
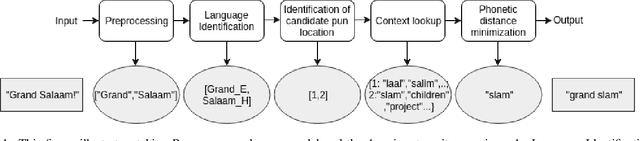

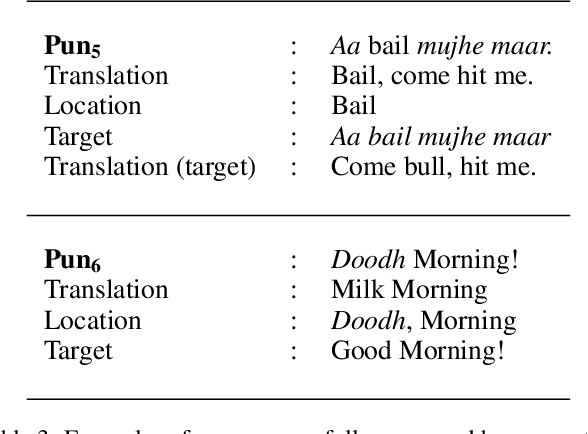
In order for our computer systems to be more human-like, with a higher emotional quotient, they need to be able to process and understand intrinsic human language phenomena like humour. In this paper, we consider a subtype of humour - puns, which are a common type of wordplay-based jokes. In particular, we consider code-mixed puns which have become increasingly mainstream on social media, in informal conversations and advertisements and aim to build a system which can automatically identify the pun location and recover the target of such puns. We first study and classify code-mixed puns into two categories namely intra-sentential and intra-word, and then propose a four-step algorithm to recover the pun targets for puns belonging to the intra-sentential category. Our algorithm uses language models, and phonetic similarity-based features to get the desired results. We test our approach on a small set of code-mixed punning advertisements, and observe that our system is successfully able to recover the targets for 67% of the puns.
Addition of Code Mixed Features to Enhance the Sentiment Prediction of Song Lyrics
Jun 11, 2018
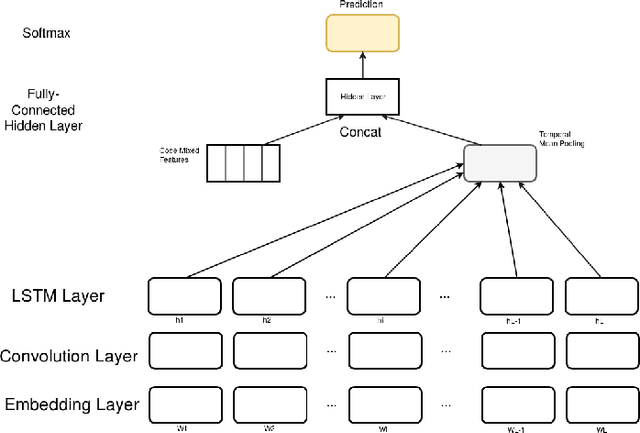

Sentiment analysis, also called opinion mining, is the field of study that analyzes people's opinions,sentiments, attitudes and emotions. Songs are important to sentiment analysis since the songs and mood are mutually dependent on each other. Based on the selected song it becomes easy to find the mood of the listener, in future it can be used for recommendation. The song lyric is a rich source of datasets containing words that are helpful in analysis and classification of sentiments generated from it. Now a days we observe a lot of inter-sentential and intra-sentential code-mixing in songs which has a varying impact on audience. To study this impact we created a Telugu songs dataset which contained both Telugu-English code-mixed and pure Telugu songs. In this paper, we classify the songs based on its arousal as exciting or non-exciting. We develop a language identification tool and introduce code-mixing features obtained from it as additional features. Our system with these additional features attains 4-5% accuracy greater than traditional approaches on our dataset.
"How to rate a video game?" - A prediction system for video games based on multimodal information
May 29, 2018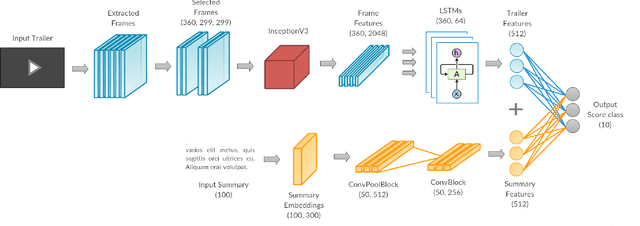
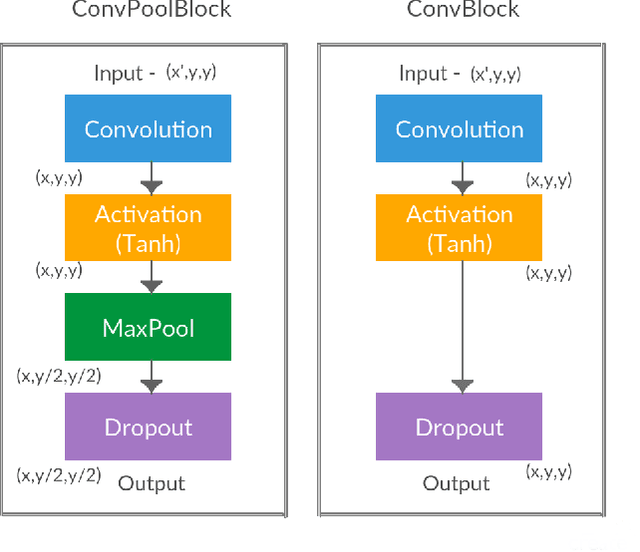

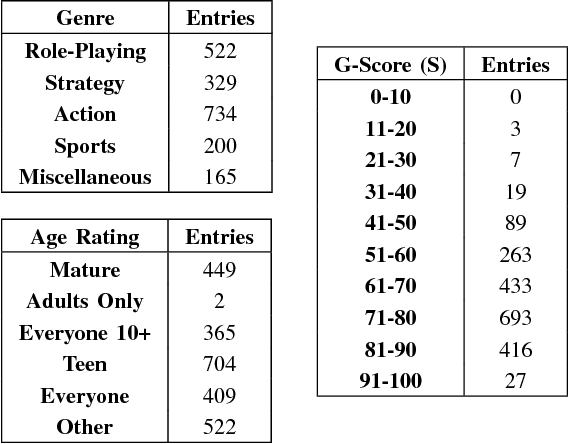
Video games have become an integral part of most people's lives in recent times. This led to an abundance of data related to video games being shared online. However, this comes with issues such as incorrect ratings, reviews or anything that is being shared. Recommendation systems are powerful tools that help users by providing them with meaningful recommendations. A straightforward approach would be to predict the scores of video games based on other information related to the game. It could be used as a means to validate user-submitted ratings as well as provide recommendations. This work provides a method to predict the G-Score, that defines how good a video game is, from its trailer (video) and summary (text). We first propose models to predict the G-Score based on the trailer alone (unimodal). Later on, we show that considering information from multiple modalities helps the models perform better compared to using information from videos alone. Since we couldn't find any suitable multimodal video game dataset, we created our own dataset named VGD (Video Game Dataset) and provide it along with this work. The approach mentioned here can be generalized to other multimodal datasets such as movie trailers and summaries etc. Towards the end, we talk about the shortcomings of the work and some methods to overcome them.
Context and Humor: Understanding Amul advertisements of India
Apr 15, 2018



Contextual knowledge is the most important element in understanding language. By contextual knowledge we mean both general knowledge and discourse knowledge i.e. knowledge of the situational context, background knowledge and the co-textual context [10]. In this paper, we will discuss the importance of contextual knowledge in understanding the humor present in the cartoon based Amul advertisements in India.In the process, we will analyze these advertisements and also see if humor is an effective tool for advertising and thereby, for marketing.These bilingual advertisements also expect the audience to have the appropriate linguistic knowledge which includes knowledge of English and Hindi vocabulary, morphology and syntax. Different techniques like punning, portmanteaus and parodies of popular proverbs, expressions, acronyms, famous dialogues, songs etc are employed to convey the message in a humorous way. The present study will concentrate on these linguistic cues and the required context for understanding wit and humor.
Experiments in Linear Template Combination using Genetic Algorithms
May 24, 2016Natural Language Generation systems typically have two parts - strategic ('what to say') and tactical ('how to say'). We present our experiments in building an unsupervised corpus-driven template based tactical NLG system. We consider templates as a sequence of words containing gaps. Our idea is based on the observation that templates are grammatical locally (within their textual span). We posit the construction of a sentence as a highly restricted sequence of such templates. This work is an attempt to explore the resulting search space using Genetic Algorithms to arrive at acceptable solutions. We present a baseline implementation of this approach which outputs gapped text.
Shallow Parsing Pipeline for Hindi-English Code-Mixed Social Media Text
Apr 11, 2016
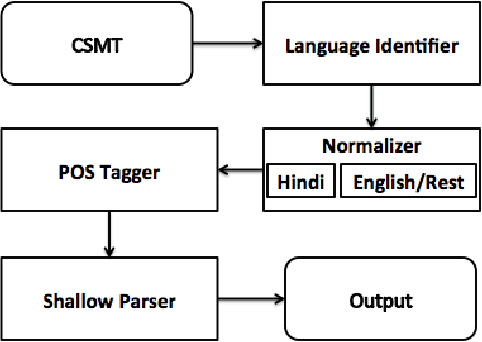
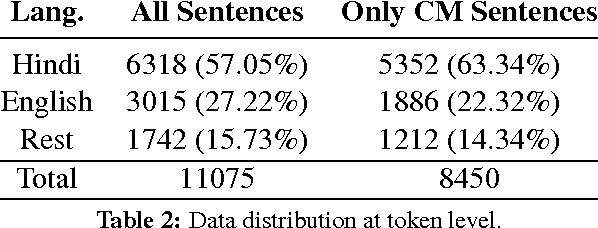
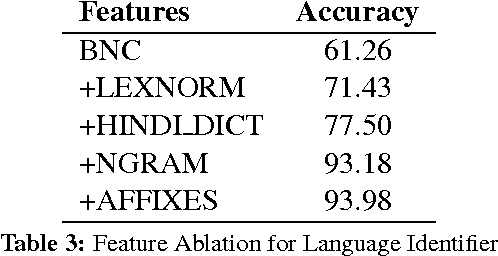
In this study, the problem of shallow parsing of Hindi-English code-mixed social media text (CSMT) has been addressed. We have annotated the data, developed a language identifier, a normalizer, a part-of-speech tagger and a shallow parser. To the best of our knowledge, we are the first to attempt shallow parsing on CSMT. The pipeline developed has been made available to the research community with the goal of enabling better text analysis of Hindi English CSMT. The pipeline is accessible at http://bit.ly/csmt-parser-api .