 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgegundapusunil at SemEval-2020 Task 8: Multimodal Memotion Analysis
Oct 09, 2020
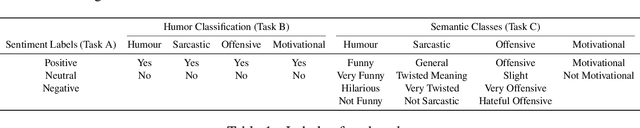
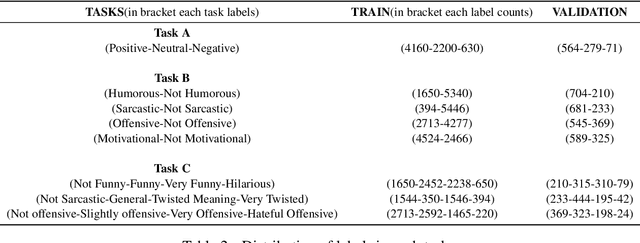
Recent technological advancements in the Internet and Social media usage have resulted in the evolution of faster and efficient platforms of communication. These platforms include visual, textual and speech mediums and have brought a unique social phenomenon called Internet memes. Internet memes are in the form of images with witty, catchy, or sarcastic text descriptions. In this paper, we present a multi-modal sentiment analysis system using deep neural networks combining Computer Vision and Natural Language Processing. Our aim is different than the normal sentiment analysis goal of predicting whether a text expresses positive or negative sentiment; instead, we aim to classify the Internet meme as a positive, negative, or neutral, identify the type of humor expressed and quantify the extent to which a particular effect is being expressed. Our system has been developed using CNN and LSTM and outperformed the baseline score.
gundapusunil at SemEval-2020 Task 9: Syntactic Semantic LSTM Architecture for SENTIment Analysis of Code-MIXed Data
Oct 09, 2020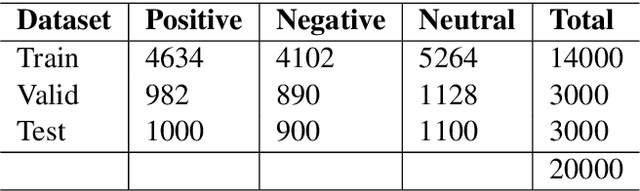
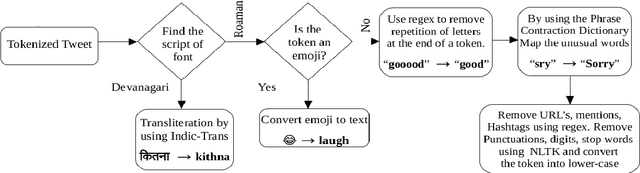
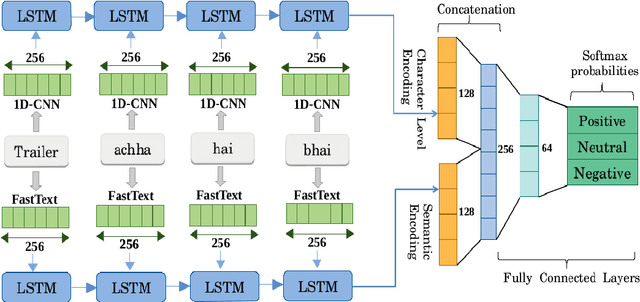
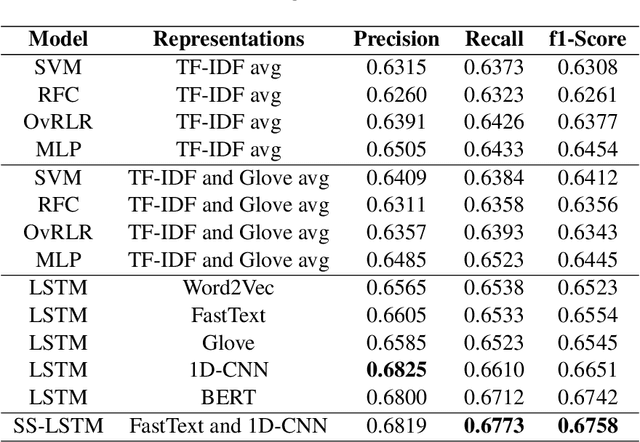
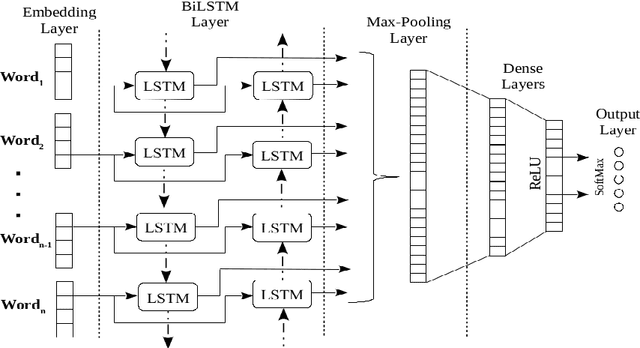
The phenomenon of mixing the vocabulary and syntax of multiple languages within the same utterance is called Code-Mixing. This is more evident in multilingual societies. In this paper, we have developed a system for SemEval 2020: Task 9 on Sentiment Analysis for Code-Mixed Social Media Text. Our system first generates two types of embeddings for the social media text. In those, the first one is character level embeddings to encode the character level information and to handle the out-of-vocabulary entries and the second one is FastText word embeddings for capturing morphology and semantics. These two embeddings were passed to the LSTM network and the system outperformed the baseline model.
BERT-based Ensembles for Modeling Disclosure and Support in Conversational Social Media Text
Jun 01, 2020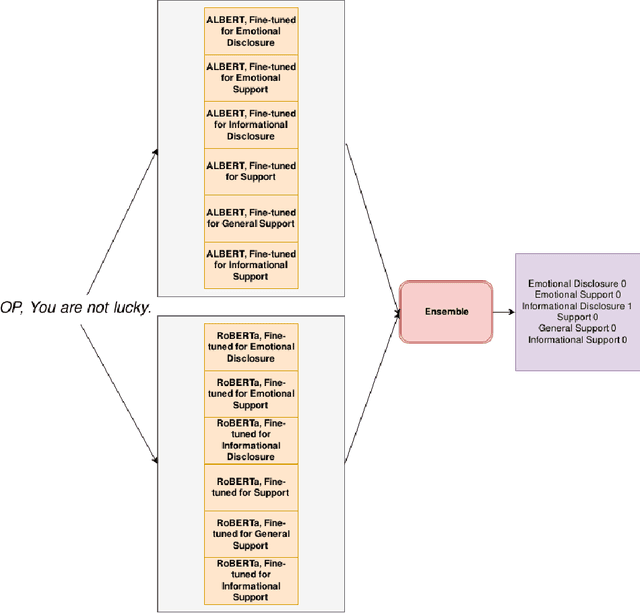
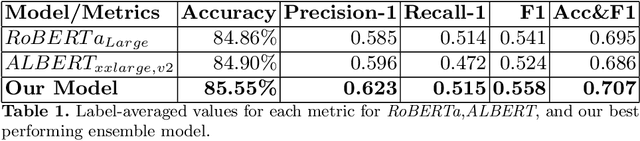
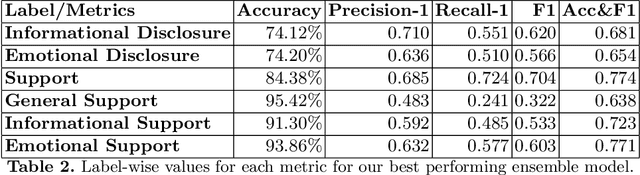
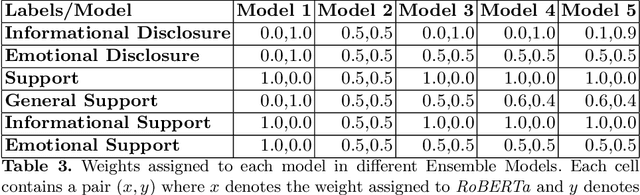
There is a growing interest in understanding how humans initiate and hold conversations. The affective understanding of conversations focuses on the problem of how speakers use emotions to react to a situation and to each other. In the CL-Aff Shared Task, the organizers released Get it #OffMyChest dataset, which contains Reddit comments from casual and confessional conversations, labeled for their disclosure and supportiveness characteristics. In this paper, we introduce a predictive ensemble model exploiting the finetuned contextualized word embeddings, RoBERTa and ALBERT. We show that our model outperforms the base models in all considered metrics, achieving an improvement of $3\%$ in the F1 score. We further conduct statistical analysis and outline deeper insights into the given dataset while providing a new characterization of impact for the dataset.
A SentiWordNet Strategy for Curriculum Learning in Sentiment Analysis
May 10, 2020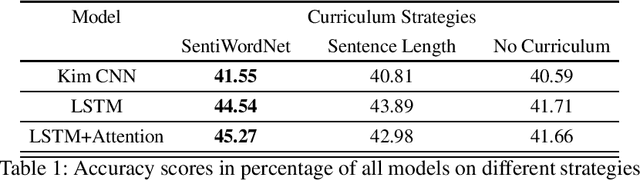
Curriculum Learning (CL) is the idea that learning on a training set sequenced or ordered in a manner where samples range from easy to difficult, results in an increment in performance over otherwise random ordering. The idea parallels cognitive science's theory of how human brains learn, and that learning a difficult task can be made easier by phrasing it as a sequence of easy to difficult tasks. This idea has gained a lot of traction in machine learning and image processing for a while and recently in Natural Language Processing (NLP). In this paper, we apply the ideas of curriculum learning, driven by SentiWordNet in a sentiment analysis setting. In this setting, given a text segment, our aim is to extract its sentiment or polarity. SentiWordNet is a lexical resource with sentiment polarity annotations. By comparing performance with other curriculum strategies and with no curriculum, the effectiveness of the proposed strategy is presented. Convolutional, Recurrence, and Attention-based architectures are employed to assess this improvement. The models are evaluated on a standard sentiment dataset, Stanford Sentiment Treebank.
Towards Detection of Subjective Bias using Contextualized Word Embeddings
Feb 16, 2020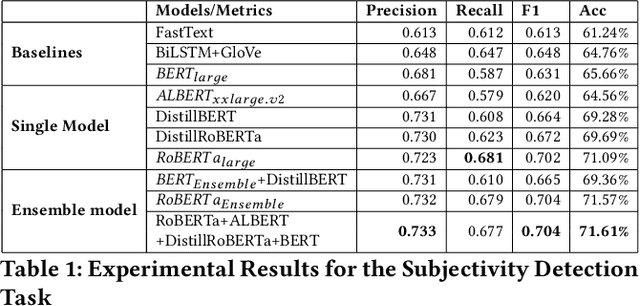
Subjective bias detection is critical for applications like propaganda detection, content recommendation, sentiment analysis, and bias neutralization. This bias is introduced in natural language via inflammatory words and phrases, casting doubt over facts, and presupposing the truth. In this work, we perform comprehensive experiments for detecting subjective bias using BERT-based models on the Wiki Neutrality Corpus(WNC). The dataset consists of $360k$ labeled instances, from Wikipedia edits that remove various instances of the bias. We further propose BERT-based ensembles that outperform state-of-the-art methods like $BERT_{large}$ by a margin of $5.6$ F1 score.
Conversational implicatures in English dialogue: Annotated dataset
Nov 25, 2019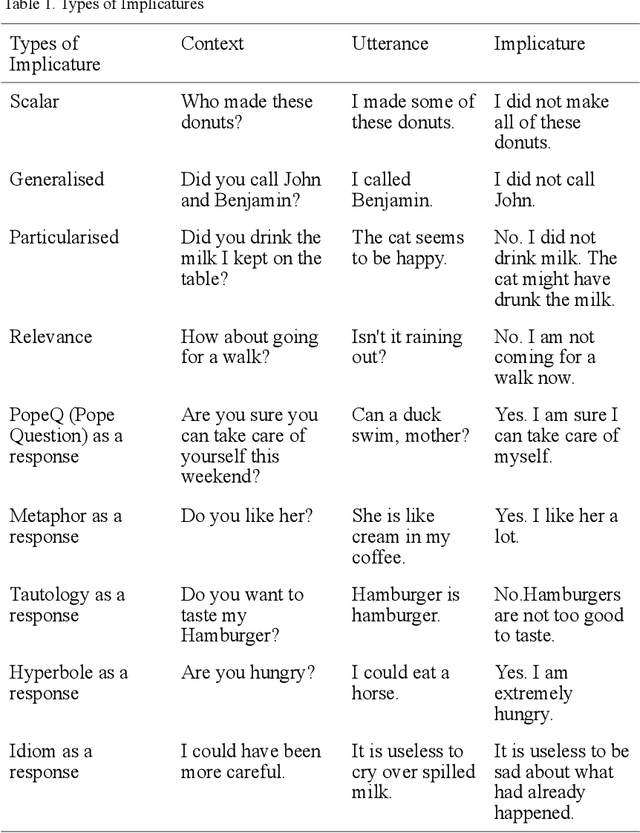
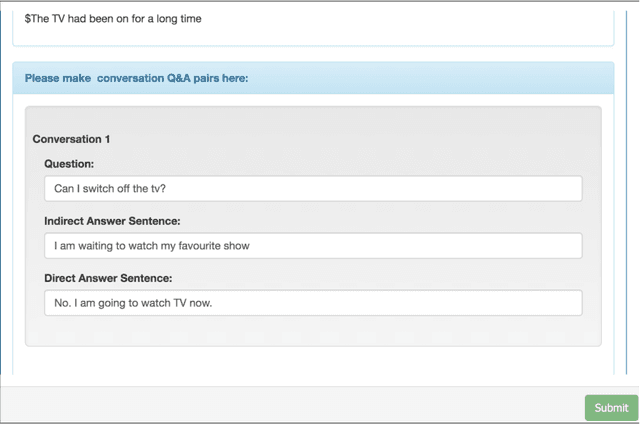
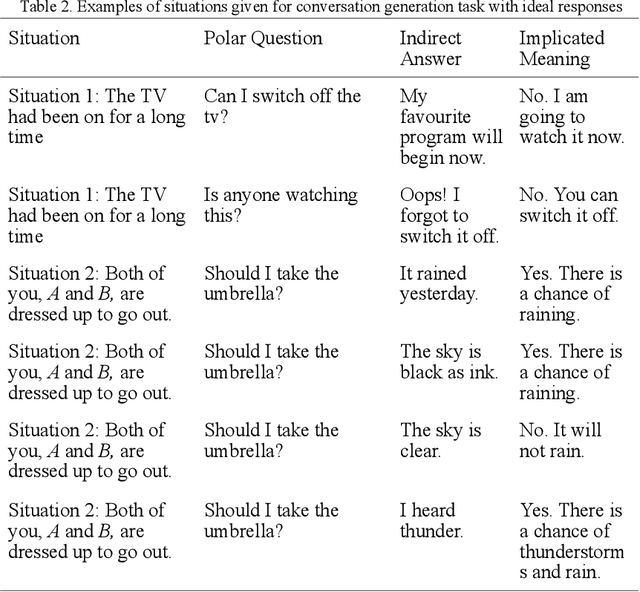

Human dialogue often contains utterances having meanings entirely different from the sentences used and are clearly understood by the interlocutors. But in human-computer interactions, the machine fails to understand the implicated meaning unless it is trained with a dataset containing the implicated meaning of an utterance along with the utterance and the context in which it is uttered. In linguistic terms, conversational implicatures are the meanings of the speaker's utterance that are not part of what is explicitly said. In this paper, we introduce a dataset of dialogue snippets with three constituents, which are the context, the utterance, and the implicated meanings. These implicated meanings are the conversational implicatures. The utterances are collected by transcribing from listening comprehension sections of English tests like TOEFL (Test of English as a Foreign Language) as well as scraping dialogues from movie scripts available on IMSDb (Internet Movie Script Database). The utterances are manually annotated with implicatures.
Anaphora Resolution in Dialogue Systems for South Asian Languages
Nov 22, 2019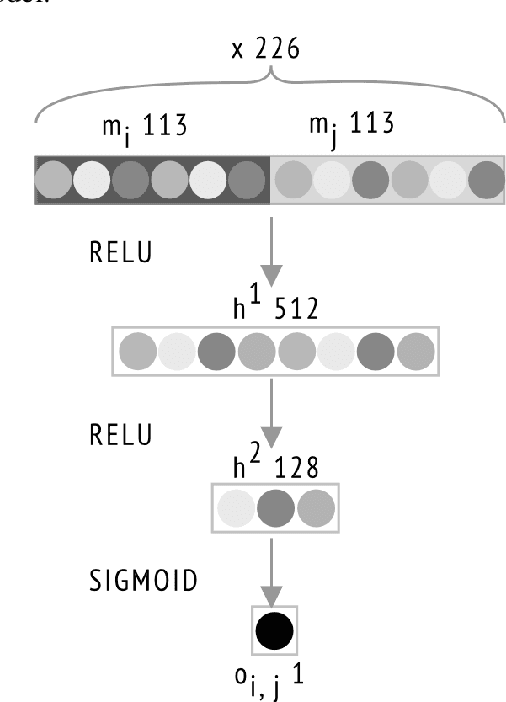
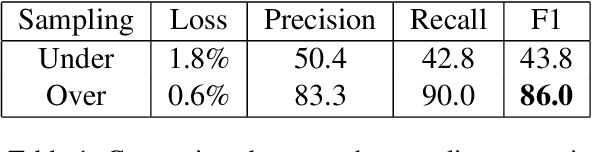
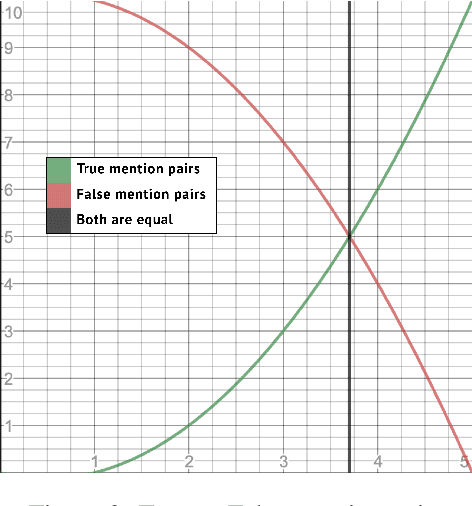
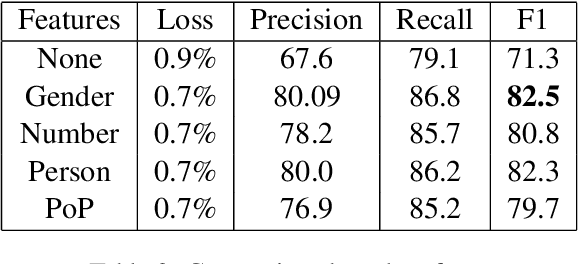
Anaphora resolution is a challenging task which has been the interest of NLP researchers for a long time. Traditional resolution techniques like eliminative constraints and weighted preferences were successful in many languages. However, they are ineffective in free word order languages like most SouthAsian languages.Heuristic and rule-based techniques were typical in these languages, which are constrained to context and domain.In this paper, we venture a new strategy us-ing neural networks for resolving anaphora in human-human dialogues. The architecture chiefly consists of three components, a shallow parser for extracting features, a feature vector generator which produces the word embed-dings, and a neural network model which will predict the antecedent mention of an anaphora.The system has been trained and tested on Telugu conversation corpus we generated. Given the advantage of the semantic information in word embeddings and appending actor, gender, number, person and part of plural features the model has reached an F1-score of 86.
Towards Computing Inferences from English News Headlines
Oct 18, 2019
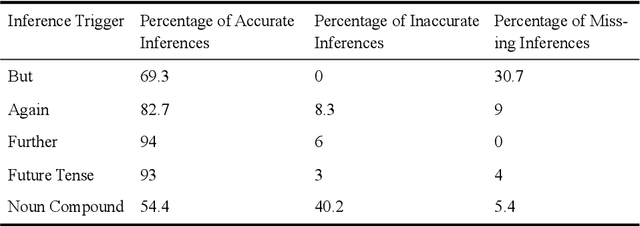


Newspapers are a popular form of written discourse, read by many people, thanks to the novelty of the information provided by the news content in it. A headline is the most widely read part of any newspaper due to its appearance in a bigger font and sometimes in colour print. In this paper, we suggest and implement a method for computing inferences from English news headlines, excluding the information from the context in which the headlines appear. This method attempts to generate the possible assumptions a reader formulates in mind upon reading a fresh headline. The generated inferences could be useful for assessing the impact of the news headline on readers including children. The understandability of the current state of social affairs depends greatly on the assimilation of the headlines. As the inferences that are independent of the context depend mainly on the syntax of the headline, dependency trees of headlines are used in this approach, to find the syntactical structure of the headlines and to compute inferences out of them.
SmokEng: Towards Fine-grained Classification of Tobacco-related Social Media Text
Oct 12, 2019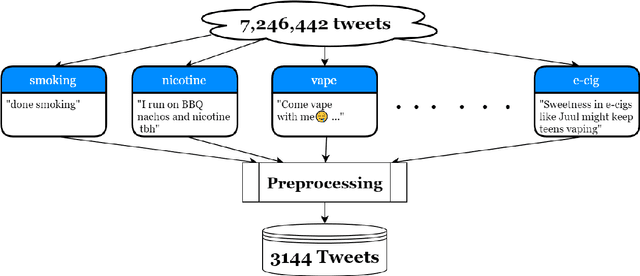
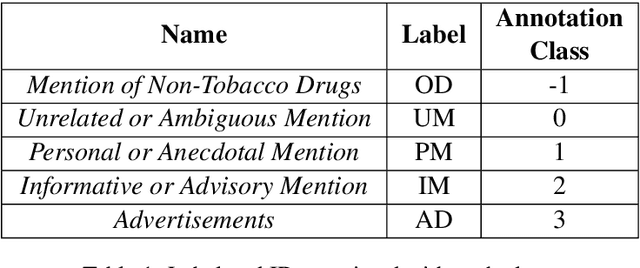

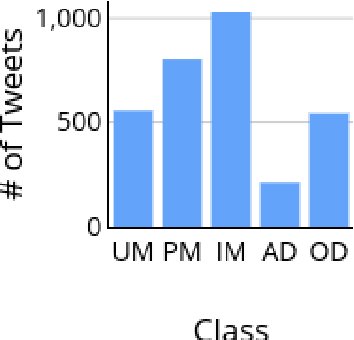
Contemporary datasets on tobacco consumption focus on one of two topics, either public health mentions and disease surveillance, or sentiment analysis on topical tobacco products and services. However, two primary considerations are not accounted for, the language of the demographic affected and a combination of the topics mentioned above in a fine-grained classification mechanism. In this paper, we create a dataset of 3144 tweets, which are selected based on the presence of colloquial slang related to smoking and analyze it based on the semantics of the tweet. Each class is created and annotated based on the content of the tweets such that further hierarchical methods can be easily applied. Further, we prove the efficacy of standard text classification methods on this dataset, by designing experiments which do both binary as well as multi-class classification. Our experiments tackle the identification of either a specific topic (such as tobacco product promotion), a general mention (cigarettes and related products) or a more fine-grained classification. This methodology paves the way for further analysis, such as understanding sentiment or style, which makes this dataset a vital contribution to both disease surveillance and tobacco use research.
Hindi Question Generation Using Dependency Structures
Jun 20, 2019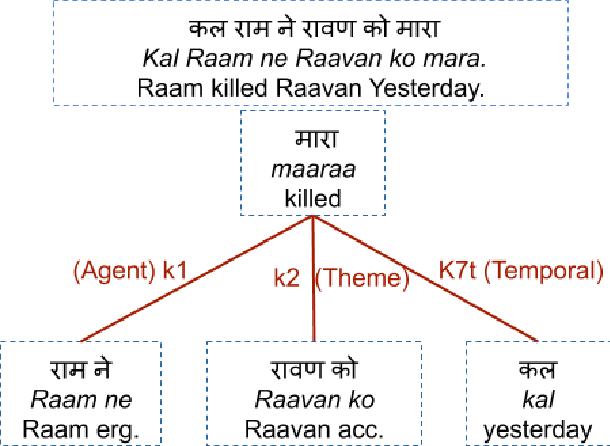

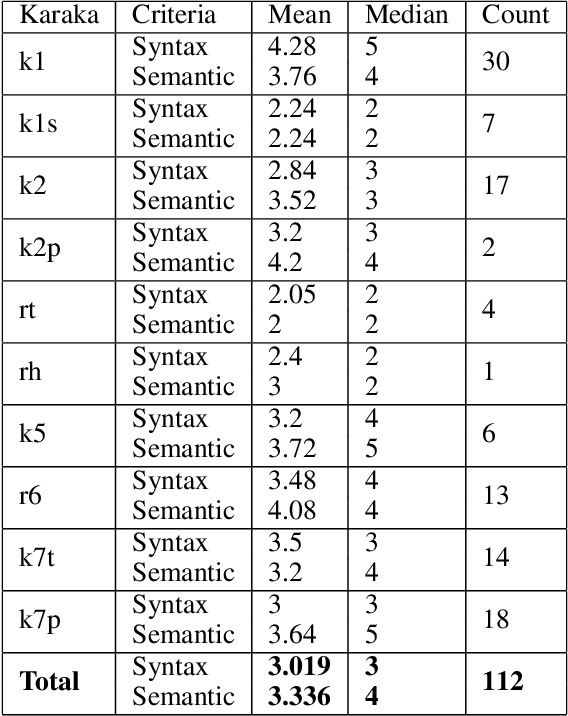
Hindi question answering systems suffer from a lack of data. To address the same, this paper presents an approach towards automatic question generation. We present a rule-based system for question generation in Hindi by formalizing question transformation methods based on karaka-dependency theory. We use a Hindi dependency parser to mark the karaka roles and use IndoWordNet a Hindi ontology to detect the semantic category of the karaka role heads to generate the interrogatives. We analyze how one sentence can have multiple generations from the same karaka role's rule. The generations are manually annotated by multiple annotators on a semantic and syntactic scale for evaluation. Further, we constrain our generation with the help of various semantic and syntactic filters so as to improve the generation quality. Using these methods, we are able to generate diverse questions, significantly more than number of sentences fed to the system.