 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Conversational Humor Analysis and Design
Feb 28, 2021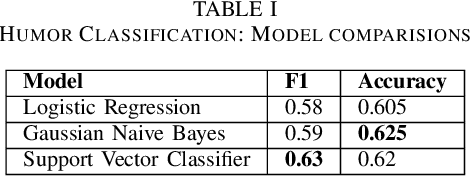

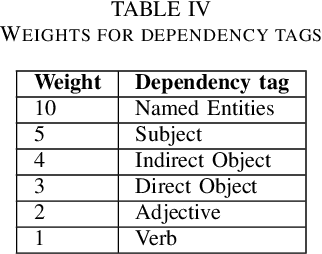
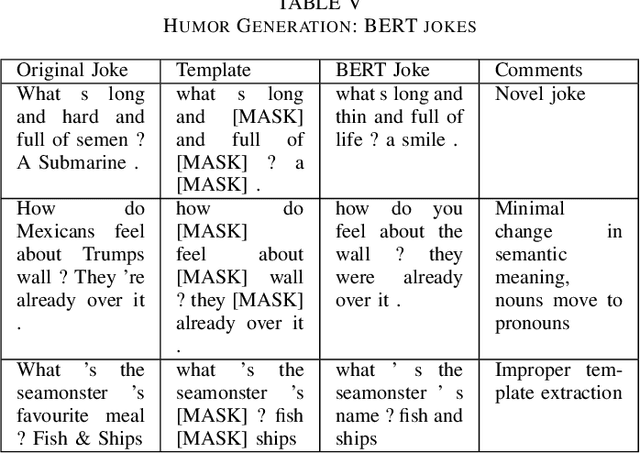
Well-defined jokes can be divided neatly into a setup and a punchline. While most works on humor today talk about a joke as a whole, the idea of generating punchlines to a setup has applications in conversational humor, where funny remarks usually occur with a non-funny context. Thus, this paper is based around two core concepts: Classification and the Generation of a punchline from a particular setup based on the Incongruity Theory. We first implement a feature-based machine learning model to classify humor. For humor generation, we use a neural model, and then merge the classical rule-based approaches with the neural approach to create a hybrid model. The idea behind being: combining insights gained from other tasks with the setup-punchline model and thus applying it to existing text generation approaches. We then use and compare our model with human written jokes with the help of human evaluators in a double-blind study.
Hopeful_Men@LT-EDI-EACL2021: Hope Speech Detection Using Indic Transliteration and Transformers
Feb 25, 2021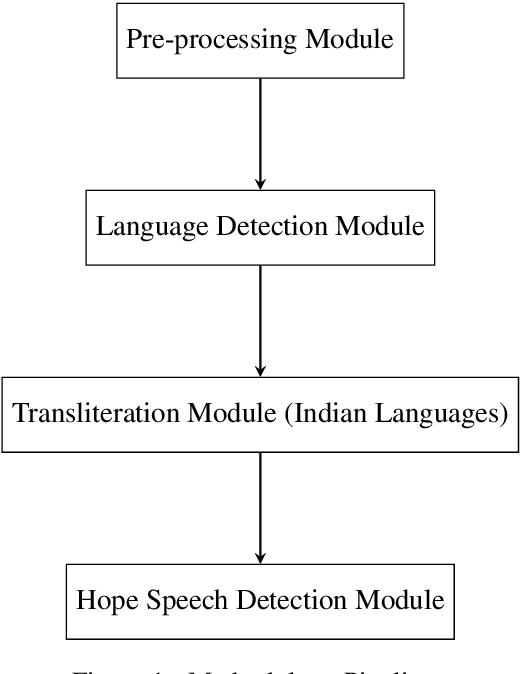
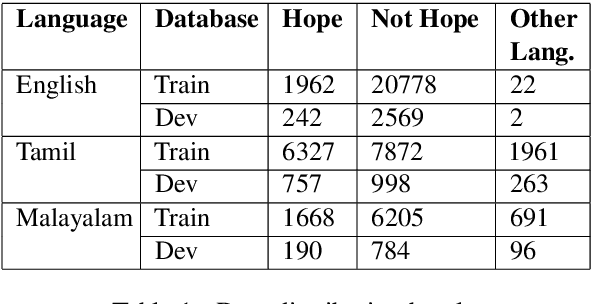
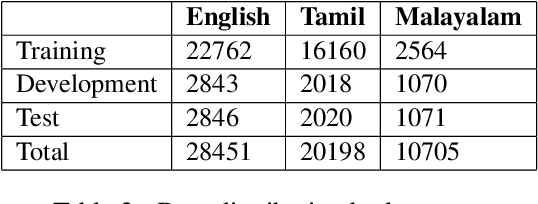
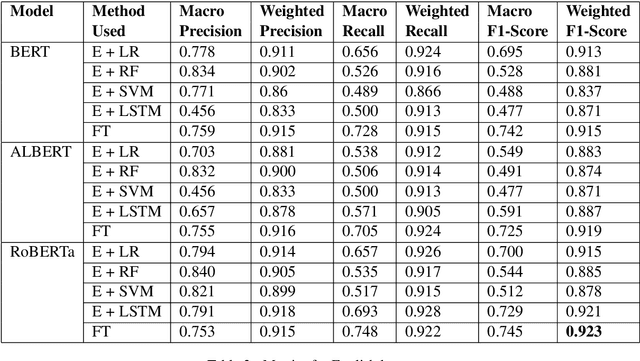
This paper aims to describe the approach we used to detect hope speech in the HopeEDI dataset. We experimented with two approaches. In the first approach, we used contextual embeddings to train classifiers using logistic regression, random forest, SVM, and LSTM based models.The second approach involved using a majority voting ensemble of 11 models which were obtained by fine-tuning pre-trained transformer models (BERT, ALBERT, RoBERTa, IndicBERT) after adding an output layer. We found that the second approach was superior for English, Tamil and Malayalam. Our solution got a weighted F1 score of 0.93, 0.75 and 0.49 for English,Malayalam and Tamil respectively. Our solution ranked first in English, eighth in Malayalam and eleventh in Tamil.
Multichannel LSTM-CNN for Telugu Technical Domain Identification
Feb 24, 2021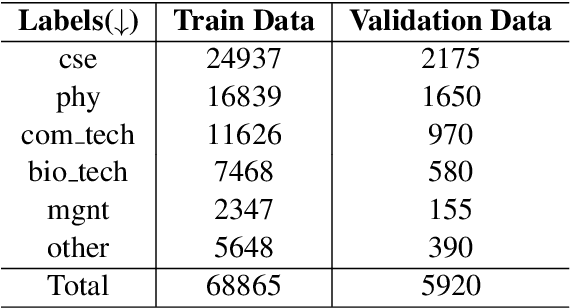
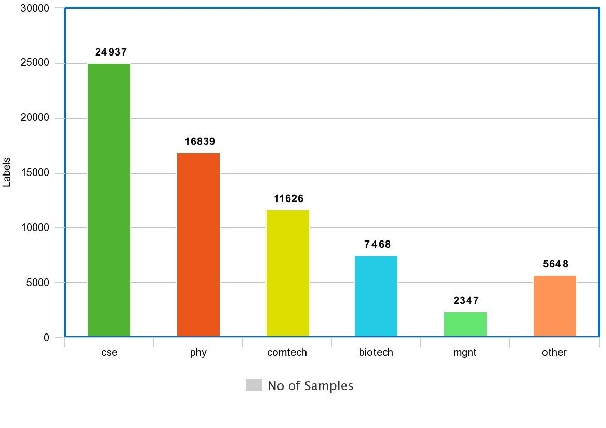
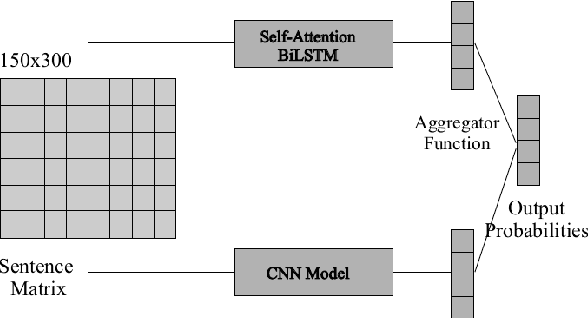
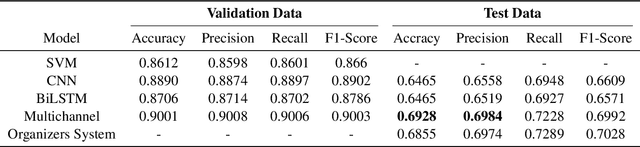
With the instantaneous growth of text information, retrieving domain-oriented information from the text data has a broad range of applications in Information Retrieval and Natural language Processing. Thematic keywords give a compressed representation of the text. Usually, Domain Identification plays a significant role in Machine Translation, Text Summarization, Question Answering, Information Extraction, and Sentiment Analysis. In this paper, we proposed the Multichannel LSTM-CNN methodology for Technical Domain Identification for Telugu. This architecture was used and evaluated in the context of the ICON shared task TechDOfication 2020 (task h), and our system got 69.9% of the F1 score on the test dataset and 90.01% on the validation set.
Unsupervised Technical Domain Terms Extraction using Term Extractor
Jan 22, 2021
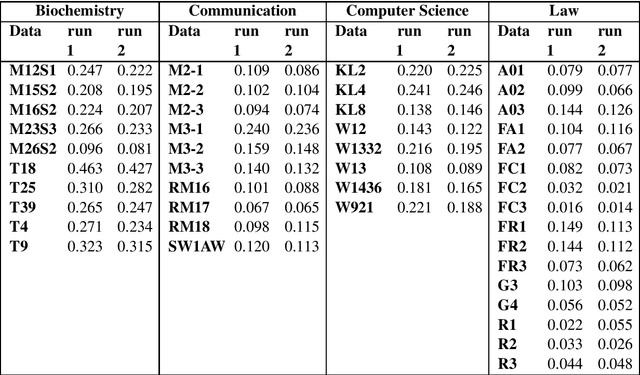

Terminology extraction, also known as term extraction, is a subtask of information extraction. The goal of terminology extraction is to extract relevant words or phrases from a given corpus automatically. This paper focuses on the unsupervised automated domain term extraction method that considers chunking, preprocessing, and ranking domain-specific terms using relevance and cohesion functions for ICON 2020 shared task 2: TermTraction.
Multilingual Pre-Trained Transformers and Convolutional NN Classification Models for Technical Domain Identification
Jan 22, 2021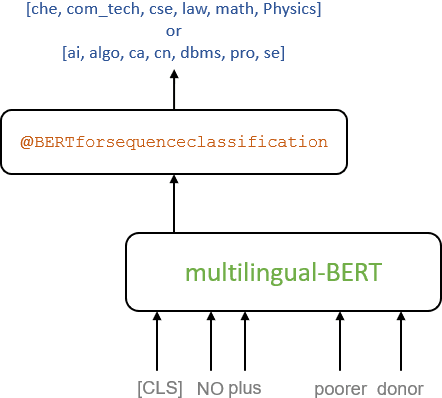
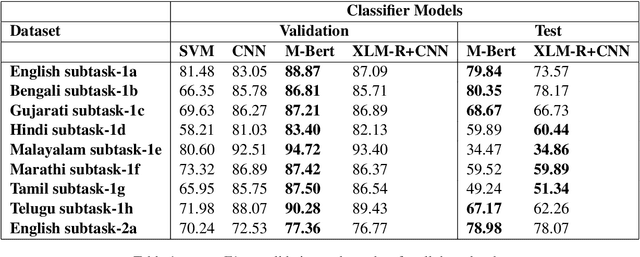
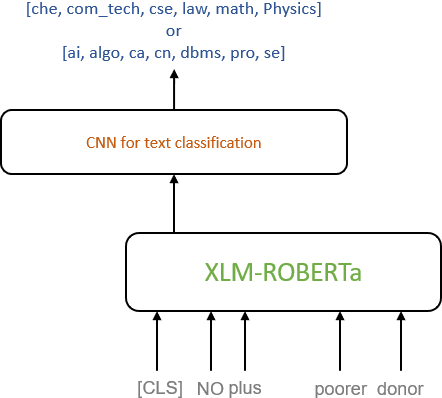
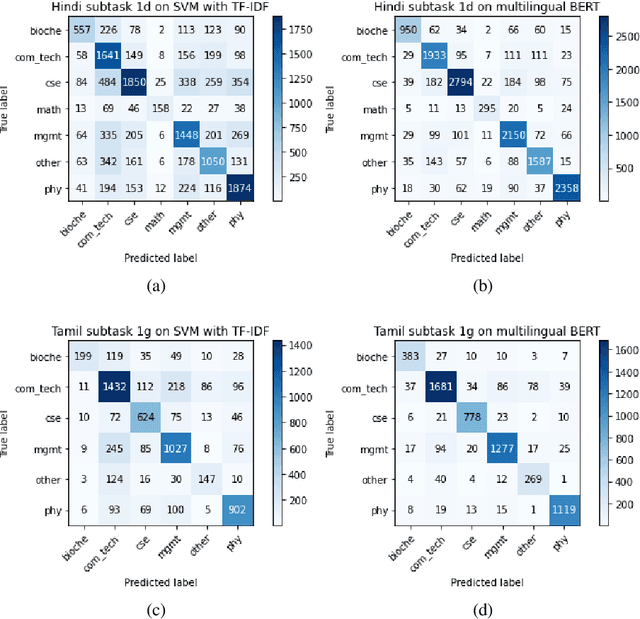
In this paper, we present a transfer learning system to perform technical domain identification on multilingual text data. We have submitted two runs, one uses the transformer model BERT, and the other uses XLM-ROBERTa with the CNN model for text classification. These models allowed us to identify the domain of the given sentences for the ICON 2020 shared Task, TechDOfication: Technical Domain Identification. Our system ranked the best for the subtasks 1d, 1g for the given TechDOfication dataset.
Does a Hybrid Neural Network based Feature Selection Model Improve Text Classification?
Jan 22, 2021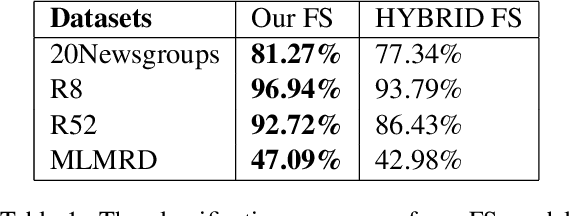
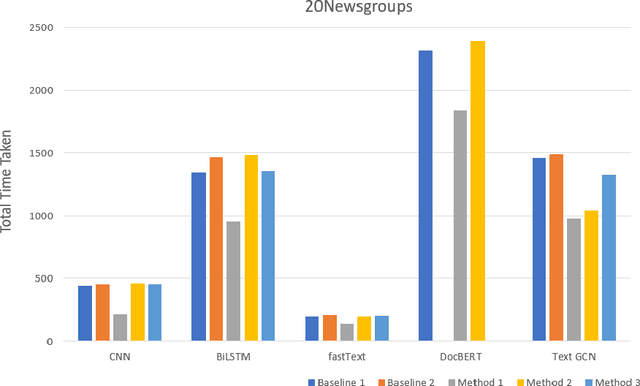

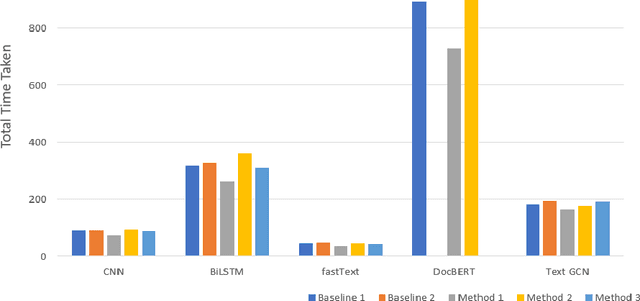
Text classification is a fundamental problem in the field of natural language processing. Text classification mainly focuses on giving more importance to all the relevant features that help classify the textual data. Apart from these, the text can have redundant or highly correlated features. These features increase the complexity of the classification algorithm. Thus, many dimensionality reduction methods were proposed with the traditional machine learning classifiers. The use of dimensionality reduction methods with machine learning classifiers has achieved good results. In this paper, we propose a hybrid feature selection method for obtaining relevant features by combining various filter-based feature selection methods and fastText classifier. We then present three ways of implementing a feature selection and neural network pipeline. We observed a reduction in training time when feature selection methods are used along with neural networks. We also observed a slight increase in accuracy on some datasets.
HASOCOne@FIRE-HASOC2020: Using BERT and Multilingual BERT models for Hate Speech Detection
Jan 22, 2021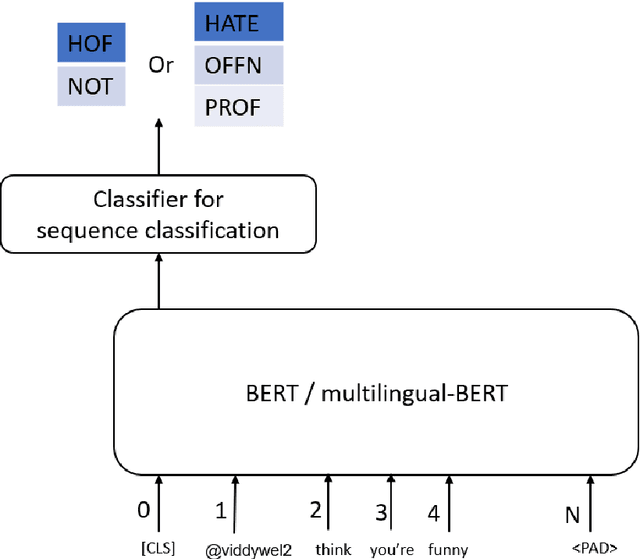
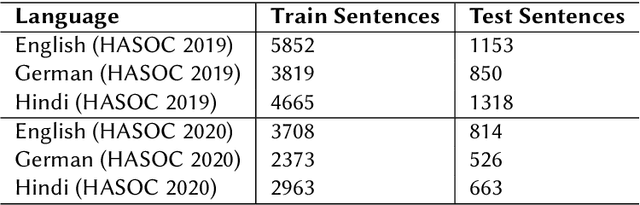
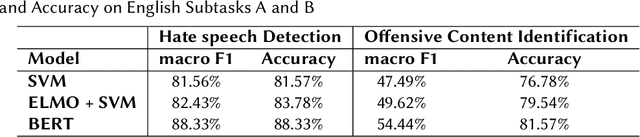
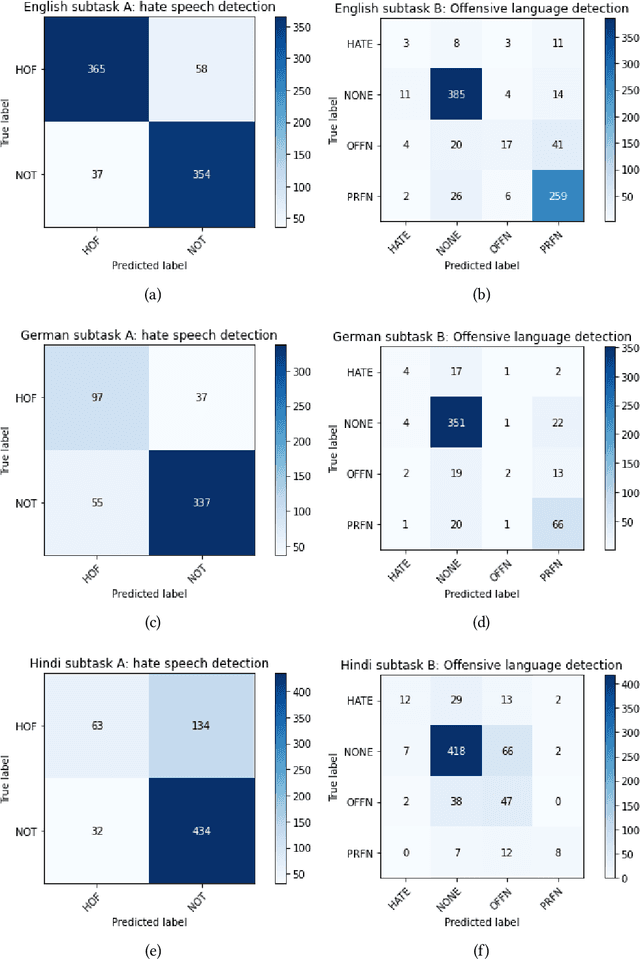
Hateful and Toxic content has become a significant concern in today's world due to an exponential rise in social media. The increase in hate speech and harmful content motivated researchers to dedicate substantial efforts to the challenging direction of hateful content identification. In this task, we propose an approach to automatically classify hate speech and offensive content. We have used the datasets obtained from FIRE 2019 and 2020 shared tasks. We perform experiments by taking advantage of transfer learning models. We observed that the pre-trained BERT model and the multilingual-BERT model gave the best results. The code is made publically available at https://github.com/suman101112/hasoc-fire-2020.
CMSAOne@Dravidian-CodeMix-FIRE2020: A Meta Embedding and Transformer model for Code-Mixed Sentiment Analysis on Social Media Text
Jan 22, 2021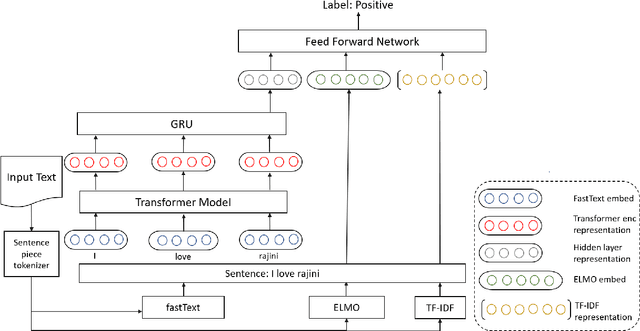


Code-mixing(CM) is a frequently observed phenomenon that uses multiple languages in an utterance or sentence. CM is mostly practiced on various social media platforms and in informal conversations. Sentiment analysis (SA) is a fundamental step in NLP and is well studied in the monolingual text. Code-mixing adds a challenge to sentiment analysis due to its non-standard representations. This paper proposes a meta embedding with a transformer method for sentiment analysis on the Dravidian code-mixed dataset. In our method, we used meta embeddings to capture rich text representations. We used the proposed method for the Task: "Sentiment Analysis for Dravidian Languages in Code-Mixed Text", and it achieved an F1 score of $0.58$ and $0.66$ for the given Dravidian code mixed data sets. The code is provided in the Github https://github.com/suman101112/fire-2020-Dravidian-CodeMix.
Transformer based Automatic COVID-19 Fake News Detection System
Jan 21, 2021

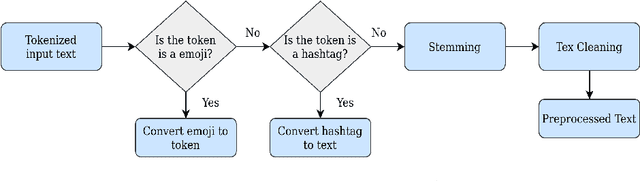

Recent rapid technological advancements in online social networks such as Twitter have led to a great incline in spreading false information and fake news. Misinformation is especially prevalent in the ongoing coronavirus disease (COVID-19) pandemic, leading to individuals accepting bogus and potentially deleterious claims and articles. Quick detection of fake news can reduce the spread of panic and confusion among the public. For our analysis in this paper, we report a methodology to analyze the reliability of information shared on social media pertaining to the COVID-19 pandemic. Our best approach is based on an ensemble of three transformer models (BERT, ALBERT, and XLNET) to detecting fake news. This model was trained and evaluated in the context of the ConstraintAI 2021 shared task COVID19 Fake News Detection in English. Our system obtained 0.9855 f1-score on testset and ranked 5th among 160 teams.
Word Level Language Identification in English Telugu Code Mixed Data
Oct 09, 2020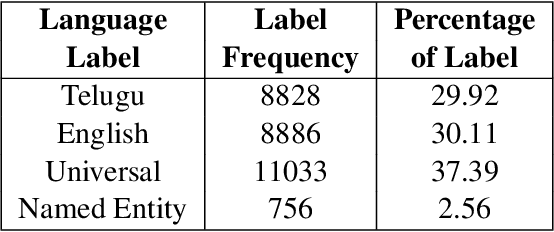
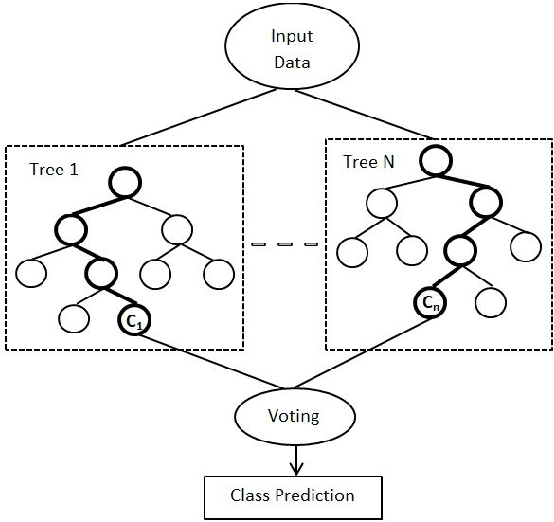
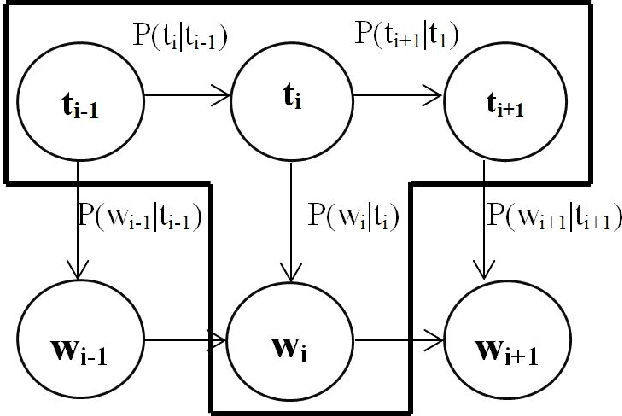
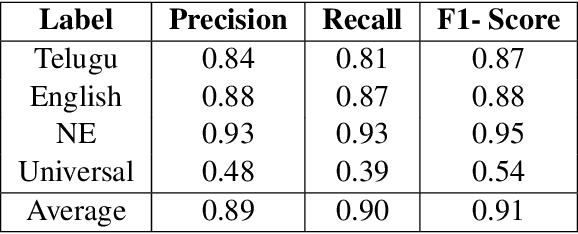
In a multilingual or sociolingual configuration Intra-sentential Code Switching (ICS) or Code Mixing (CM) is frequently observed nowadays. In the world, most of the people know more than one language. CM usage is especially apparent in social media platforms. Moreover, ICS is particularly significant in the context of technology, health, and law where conveying the upcoming developments are difficult in one's native language. In applications like dialog systems, machine translation, semantic parsing, shallow parsing, etc. CM and Code Switching pose serious challenges. To do any further advancement in code-mixed data, the necessary step is Language Identification. In this paper, we present a study of various models - Nave Bayes Classifier, Random Forest Classifier, Conditional Random Field (CRF), and Hidden Markov Model (HMM) for Language Identification in English - Telugu Code Mixed Data. Considering the paucity of resources in code mixed languages, we proposed the CRF model and HMM model for word level language identification. Our best performing system is CRF-based with an f1-score of 0.91.