 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Selective Masking as a Bridge between Pre-training and Fine-tuning
Nov 24, 2022Pre-training a language model and then fine-tuning it for downstream tasks has demonstrated state-of-the-art results for various NLP tasks. Pre-training is usually independent of the downstream task, and previous works have shown that this pre-training alone might not be sufficient to capture the task-specific nuances. We propose a way to tailor a pre-trained BERT model for the downstream task via task-specific masking before the standard supervised fine-tuning. For this, a word list is first collected specific to the task. For example, if the task is sentiment classification, we collect a small sample of words representing both positive and negative sentiments. Next, a word's importance for the task, called the word's task score, is measured using the word list. Each word is then assigned a probability of masking based on its task score. We experiment with different masking functions that assign the probability of masking based on the word's task score. The BERT model is further trained on MLM objective, where masking is done using the above strategy. Following this standard supervised fine-tuning is done for different downstream tasks. Results on these tasks show that the selective masking strategy outperforms random masking, indicating its effectiveness.
CMNEROne at SemEval-2022 Task 11: Code-Mixed Named Entity Recognition by leveraging multilingual data
Jun 15, 2022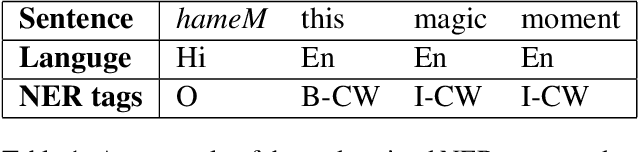
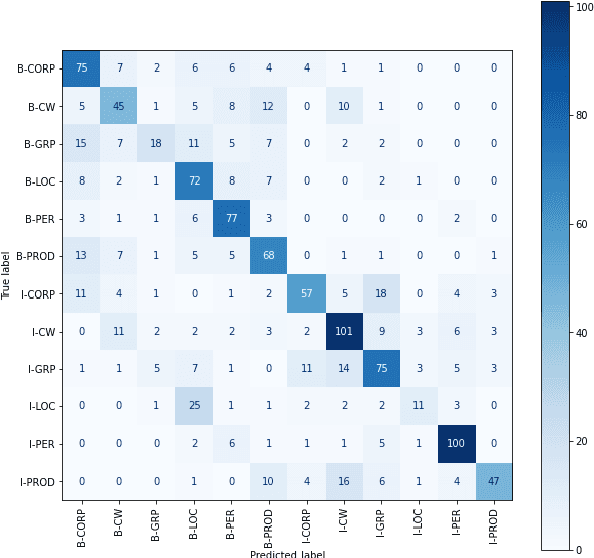
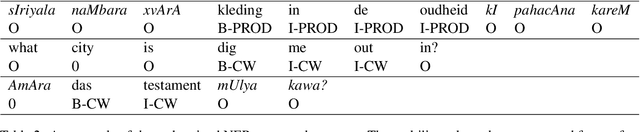
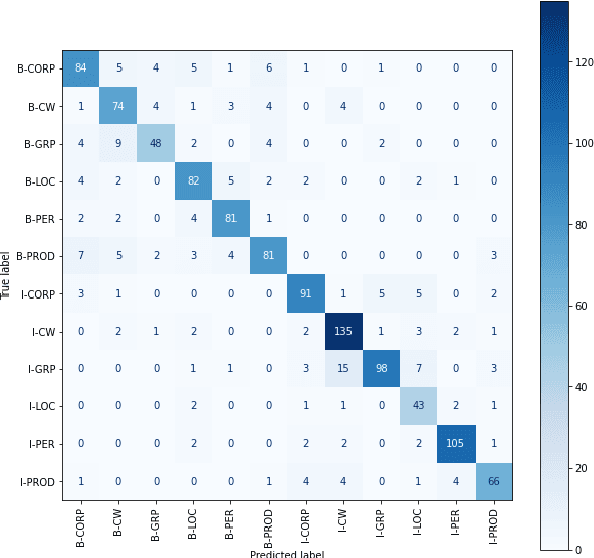
Identifying named entities is, in general, a practical and challenging task in the field of Natural Language Processing. Named Entity Recognition on the code-mixed text is further challenging due to the linguistic complexity resulting from the nature of the mixing. This paper addresses the submission of team CMNEROne to the SEMEVAL 2022 shared task 11 MultiCoNER. The Code-mixed NER task aimed to identify named entities on the code-mixed dataset. Our work consists of Named Entity Recognition (NER) on the code-mixed dataset by leveraging the multilingual data. We achieved a weighted average F1 score of 0.7044, i.e., 6% greater than the baseline.
cViL: Cross-Lingual Training of Vision-Language Models using Knowledge Distillation
Jun 09, 2022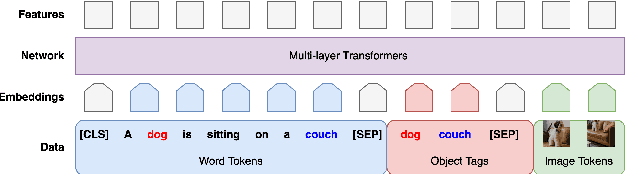
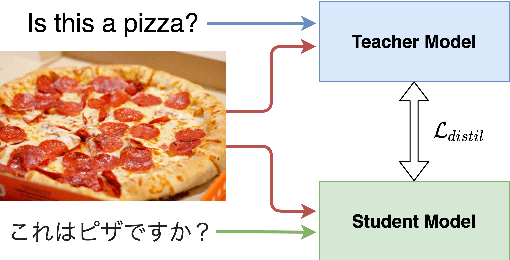

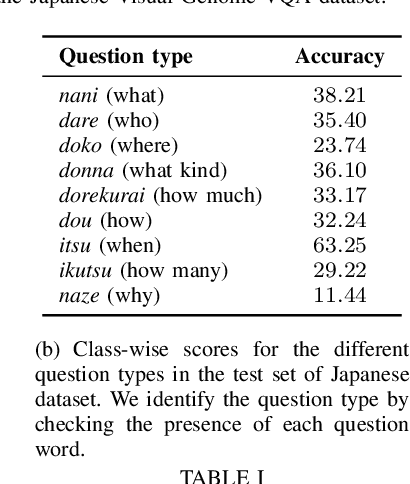
Vision-and-language tasks are gaining popularity in the research community, but the focus is still mainly on English. We propose a pipeline that utilizes English-only vision-language models to train a monolingual model for a target language. We propose to extend OSCAR+, a model which leverages object tags as anchor points for learning image-text alignments, to train on visual question answering datasets in different languages. We propose a novel approach to knowledge distillation to train the model in other languages using parallel sentences. Compared to other models that use the target language in the pretraining corpora, we can leverage an existing English model to transfer the knowledge to the target language using significantly lesser resources. We also release a large-scale visual question answering dataset in Japanese and Hindi language. Though we restrict our work to visual question answering, our model can be extended to any sequence-level classification task, and it can be extended to other languages as well. This paper focuses on two languages for the visual question answering task - Japanese and Hindi. Our pipeline outperforms the current state-of-the-art models by a relative increase of 4.4% and 13.4% respectively in accuracy.
Detection of Propaganda Techniques in Visuo-Lingual Metaphor in Memes
May 03, 2022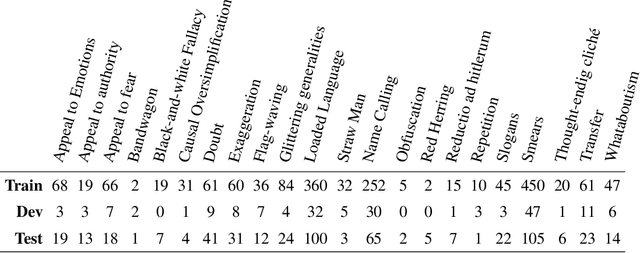
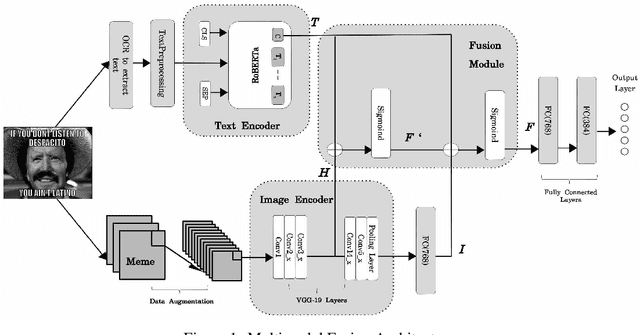
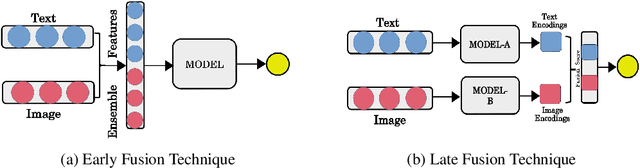
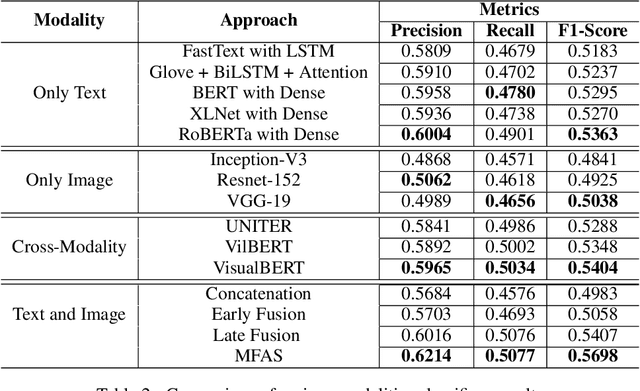
The exponential rise of social media networks has allowed the production, distribution, and consumption of data at a phenomenal rate. Moreover, the social media revolution has brought a unique phenomenon to social media platforms called Internet memes. Internet memes are one of the most popular contents used on social media, and they can be in the form of images with a witty, catchy, or satirical text description. In this paper, we are dealing with propaganda that is often seen in Internet memes in recent times. Propaganda is communication, which frequently includes psychological and rhetorical techniques to manipulate or influence an audience to act or respond as the propagandist wants. To detect propaganda in Internet memes, we propose a multimodal deep learning fusion system that fuses the text and image feature representations and outperforms individual models based solely on either text or image modalities.
Multi-Task Text Classification using Graph Convolutional Networks for Large-Scale Low Resource Language
May 02, 2022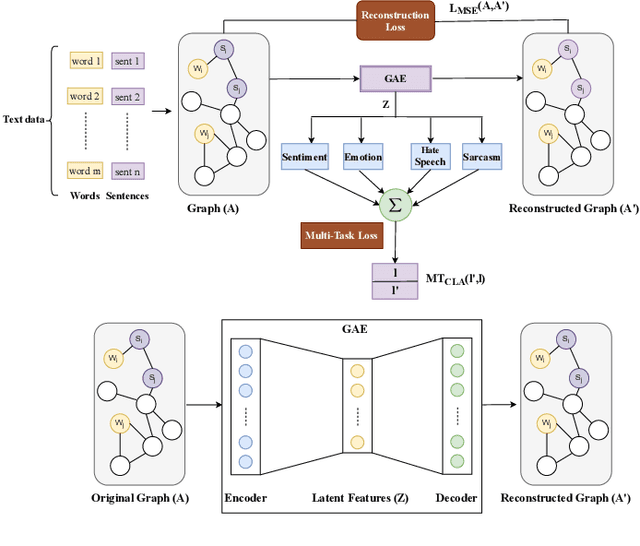
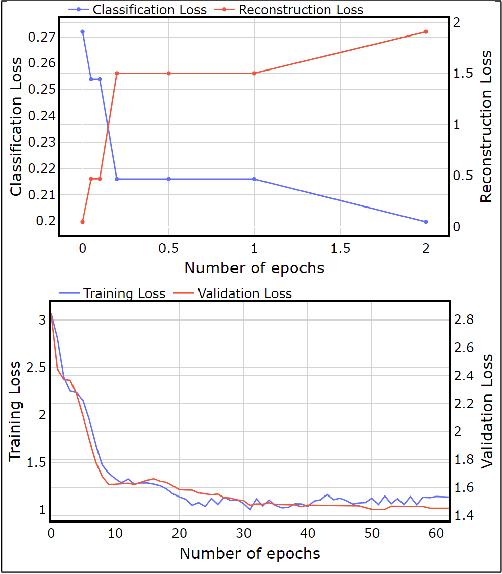

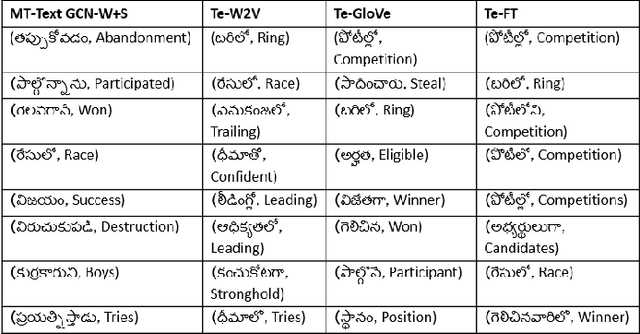
Graph Convolutional Networks (GCN) have achieved state-of-art results on single text classification tasks like sentiment analysis, emotion detection, etc. However, the performance is achieved by testing and reporting on resource-rich languages like English. Applying GCN for multi-task text classification is an unexplored area. Moreover, training a GCN or adopting an English GCN for Indian languages is often limited by data availability, rich morphological variation, syntax, and semantic differences. In this paper, we study the use of GCN for the Telugu language in single and multi-task settings for four natural language processing (NLP) tasks, viz. sentiment analysis (SA), emotion identification (EI), hate-speech (HS), and sarcasm detection (SAR). In order to evaluate the performance of GCN with one of the Indian languages, Telugu, we analyze the GCN based models with extensive experiments on four downstream tasks. In addition, we created an annotated Telugu dataset, TEL-NLP, for the four NLP tasks. Further, we propose a supervised graph reconstruction method, Multi-Task Text GCN (MT-Text GCN) on the Telugu that leverages to simultaneously (i) learn the low-dimensional word and sentence graph embeddings from word-sentence graph reconstruction using graph autoencoder (GAE) and (ii) perform multi-task text classification using these latent sentence graph embeddings. We argue that our proposed MT-Text GCN achieves significant improvements on TEL-NLP over existing Telugu pretrained word embeddings, and multilingual pretrained Transformer models: mBERT, and XLM-R. On TEL-NLP, we achieve a high F1-score for four NLP tasks: SA (0.84), EI (0.55), HS (0.83) and SAR (0.66). Finally, we show our model's quantitative and qualitative analysis on the four NLP tasks in Telugu.
On the Importance of Karaka Framework in Multi-modal Grounding
Apr 09, 2022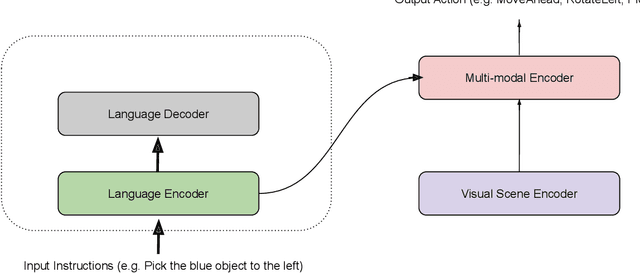
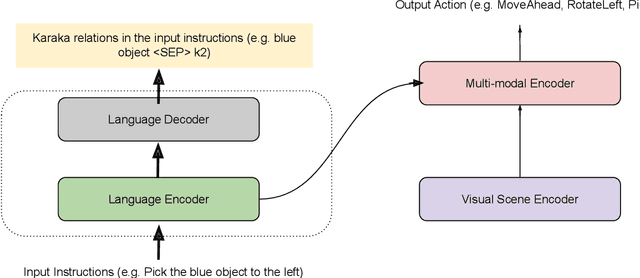
Computational Paninian Grammar model helps in decoding a natural language expression as a series of modifier-modified relations and therefore facilitates in identifying dependency relations closer to language (context) semantics compared to the usual Stanford dependency relations. However, the importance of this CPG dependency scheme has not been studied in the context of multi-modal vision and language applications. At IIIT Hyderabad, we plan to perform a novel study to explore the potential advantages and disadvantages of CPG framework in a vision-language navigation task setting, a popular and challenging multi-modal grounding task.
ViTA: Visual-Linguistic Translation by Aligning Object Tags
Jun 08, 2021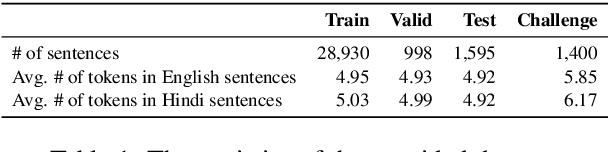
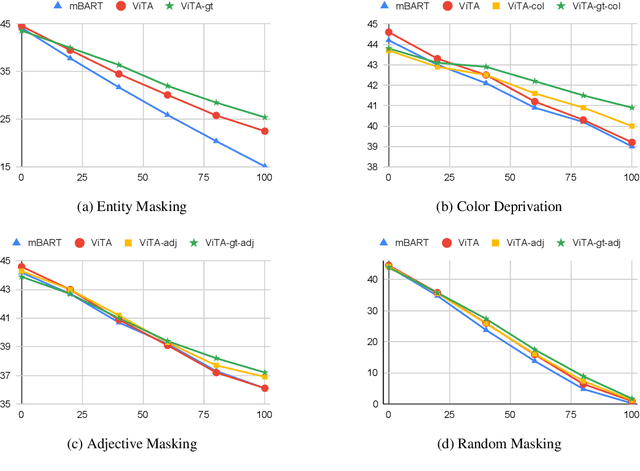
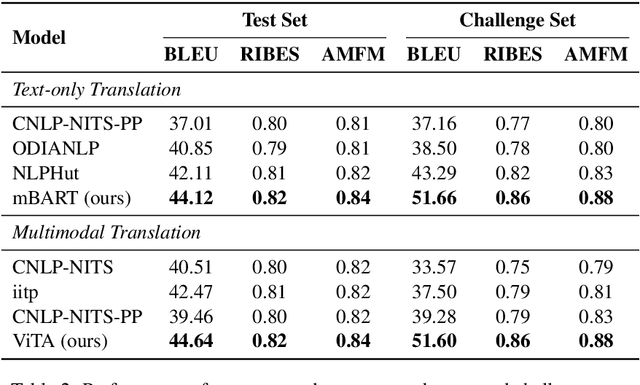

Multimodal Machine Translation (MMT) enriches the source text with visual information for translation. It has gained popularity in recent years, and several pipelines have been proposed in the same direction. Yet, the task lacks quality datasets to illustrate the contribution of visual modality in the translation systems. In this paper, we propose our system under the team name Volta for the Multimodal Translation Task of WAT 2021 from English to Hindi. We also participate in the textual-only subtask of the same language pair for which we use mBART, a pretrained multilingual sequence-to-sequence model. For multimodal translation, we propose to enhance the textual input by bringing the visual information to a textual domain by extracting object tags from the image. We also explore the robustness of our system by systematically degrading the source text. Finally, we achieve a BLEU score of 44.6 and 51.6 on the test set and challenge set of the multimodal task.
Volta at SemEval-2021 Task 6: Towards Detecting Persuasive Texts and Images using Textual and Multimodal Ensemble
Jun 01, 2021
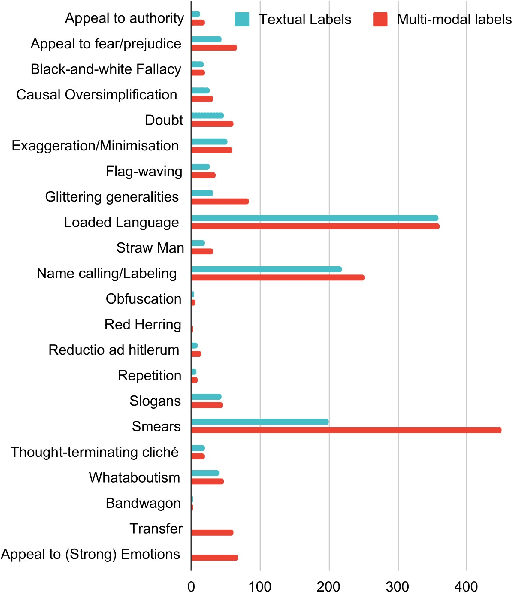
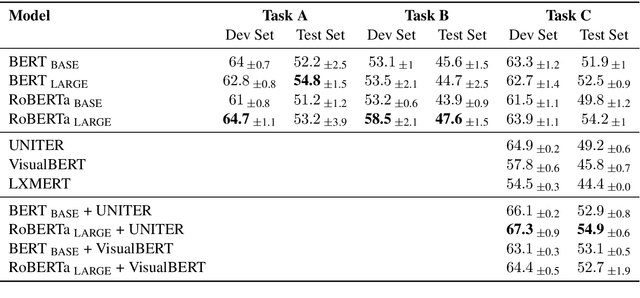
Memes are one of the most popular types of content used to spread information online. They can influence a large number of people through rhetorical and psychological techniques. The task, Detection of Persuasion Techniques in Texts and Images, is to detect these persuasive techniques in memes. It consists of three subtasks: (A) Multi-label classification using textual content, (B) Multi-label classification and span identification using textual content, and (C) Multi-label classification using visual and textual content. In this paper, we propose a transfer learning approach to fine-tune BERT-based models in different modalities. We also explore the effectiveness of ensembles of models trained in different modalities. We achieve an F1-score of 57.0, 48.2, and 52.1 in the corresponding subtasks.
Detection of Fake Users in SMPs Using NLP and Graph Embeddings
Apr 27, 2021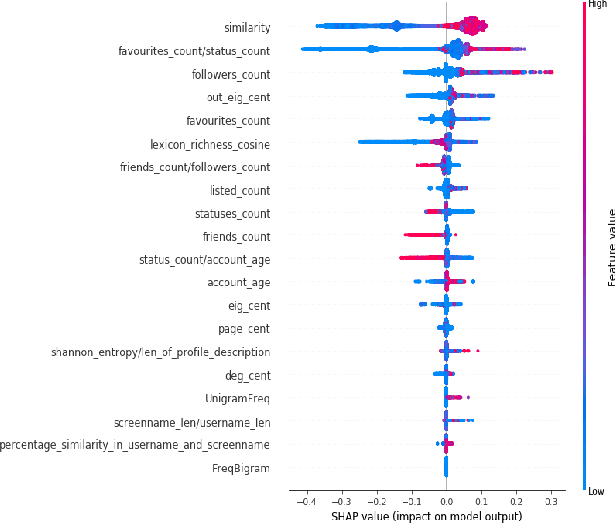
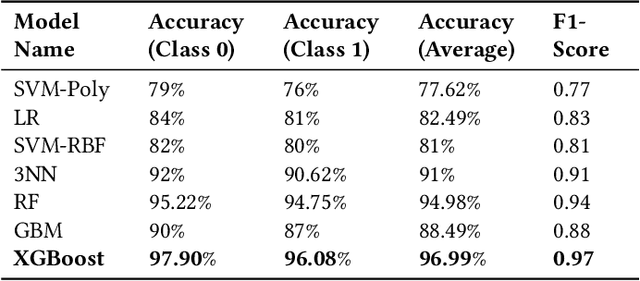
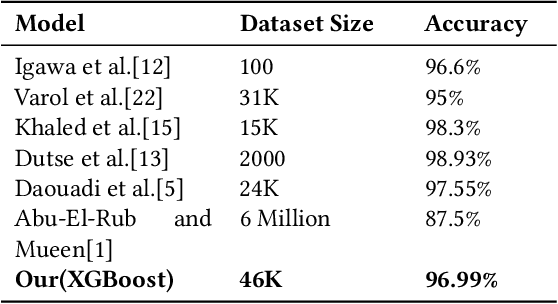
Social Media Platforms (SMPs) like Facebook, Twitter, Instagram etc. have large user base all around the world that generates huge amount of data every second. This includes a lot of posts by fake and spam users, typically used by many organisations around the globe to have competitive edge over others. In this work, we aim at detecting such user accounts in Twitter using a novel approach. We show how to distinguish between Genuine and Spam accounts in Twitter using a combination of Graph Representation Learning and Natural Language Processing techniques.
Analyzing Curriculum Learning for Sentiment Analysis along Task Difficulty, Pacing and Visualization Axes
Mar 03, 2021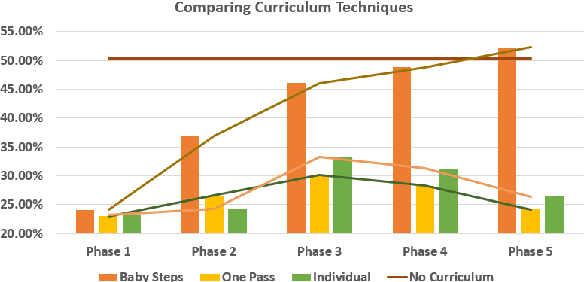
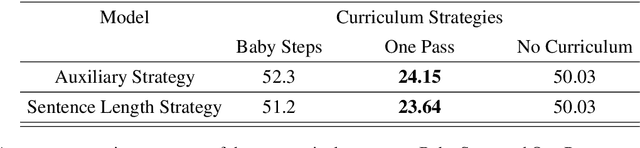
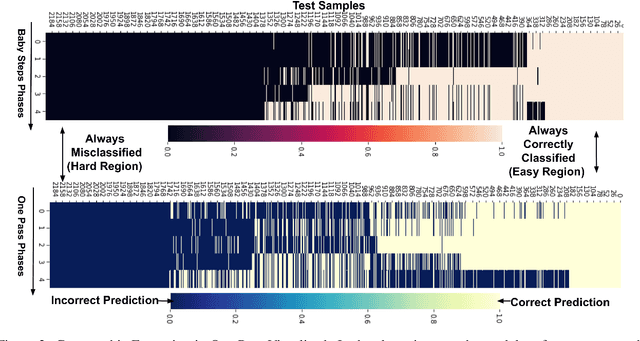
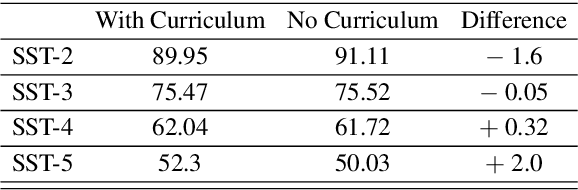
While Curriculum Learning (CL) has recently gained traction in Natural language Processing Tasks, it is still not adequately analyzed. Previous works only show their effectiveness but fail short to explain and interpret the internal workings fully. In this paper, we analyze curriculum learning in sentiment analysis along multiple axes. Some of these axes have been proposed by earlier works that need more in-depth study. Such analysis requires understanding where curriculum learning works and where it does not. Our axes of analysis include Task difficulty on CL, comparing CL pacing techniques, and qualitative analysis by visualizing the movement of attention scores in the model as curriculum phases progress. We find that curriculum learning works best for difficult tasks and may even lead to a decrement in performance for tasks with higher performance without curriculum learning. We see that One-Pass curriculum strategies suffer from catastrophic forgetting and attention movement visualization within curriculum pacing. This shows that curriculum learning breaks down the challenging main task into easier sub-tasks solved sequentially.