 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational Weight Priors in Neural Networks for Abstract Pattern Learning and Language Modelling
Mar 10, 2021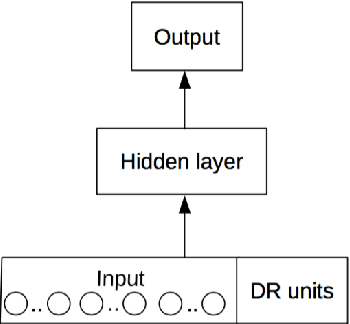
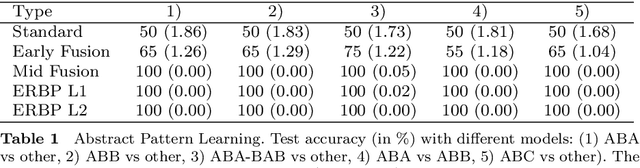
Deep neural networks have become the dominant approach in natural language processing (NLP). However, in recent years, it has become apparent that there are shortcomings in systematicity that limit the performance and data efficiency of deep learning in NLP. These shortcomings can be clearly shown in lower-level artificial tasks, mostly on synthetic data. Abstract patterns are the best known examples of a hard problem for neural networks in terms of generalisation to unseen data. They are defined by relations between items, such as equality, rather than their values. It has been argued that these low-level problems demonstrate the inability of neural networks to learn systematically. In this study, we propose Embedded Relation Based Patterns (ERBP) as a novel way to create a relational inductive bias that encourages learning equality and distance-based relations for abstract patterns. ERBP is based on Relation Based Patterns (RBP), but modelled as a Bayesian prior on network weights and implemented as a regularisation term in otherwise standard network learning. ERBP is is easy to integrate into standard neural networks and does not affect their learning capacity. In our experiments, ERBP priors lead to almost perfect generalisation when learning abstract patterns from synthetic noise-free sequences. ERBP also improves natural language models on the word and character level and pitch prediction in melodies with RNN, GRU and LSTM networks. We also find improvements in in the more complex tasks of learning of graph edit distance and compositional sentence entailment. ERBP consistently improves over RBP and over standard networks, showing that it enables abstract pattern learning which contributes to performance in natural language tasks.
Factors for the Generalisation of Identity Relations by Neural Networks
Jun 13, 2019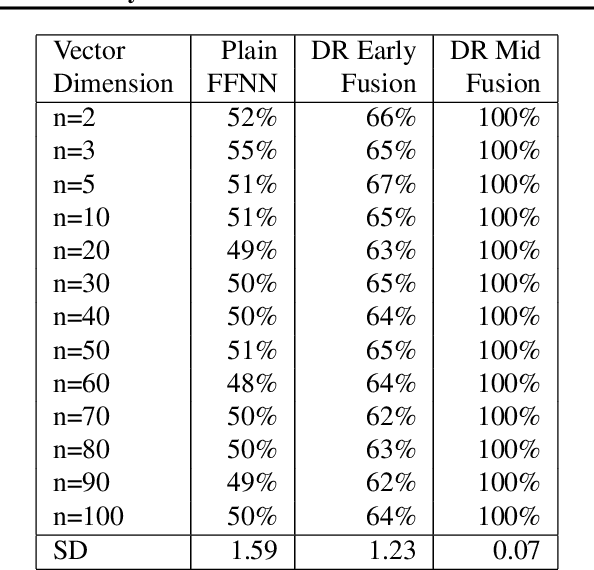
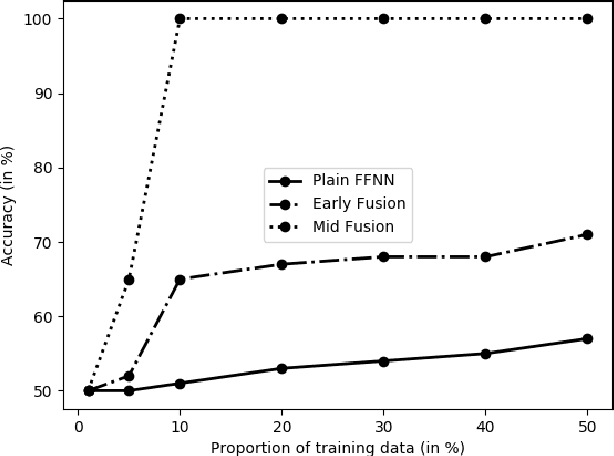
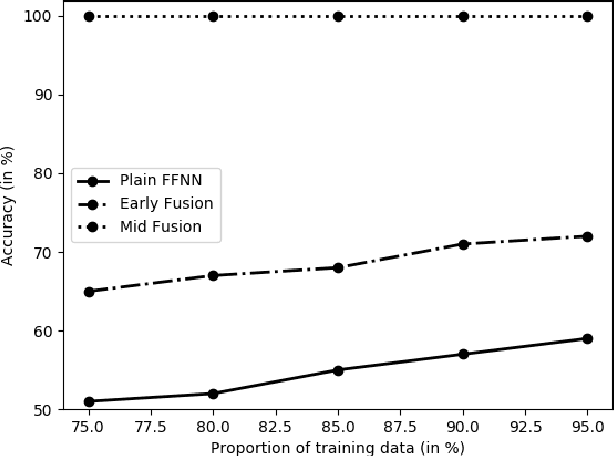
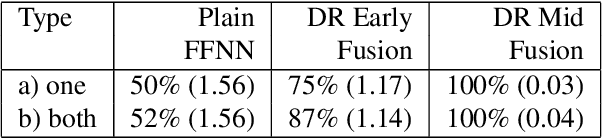
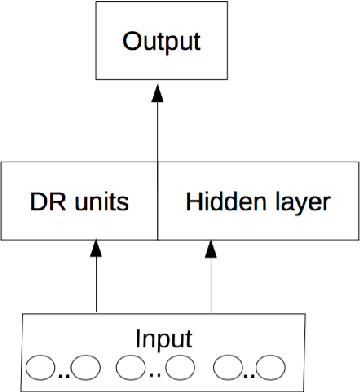
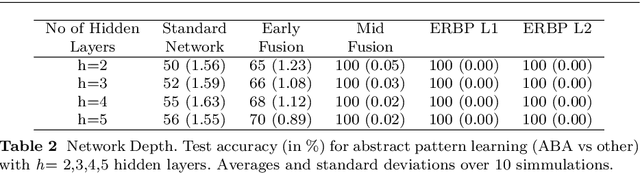
Many researchers implicitly assume that neural networks learn relations and generalise them to new unseen data. It has been shown recently, however, that the generalisation of feed-forward networks fails for identity relations.The proposed solution for this problem is to create an inductive bias with Differential Rectifier (DR) units. In this work we explore various factors in the neural network architecture and learning process whether they make a difference to the generalisation on equality detection of Neural Networks without and and with DR units in early and mid fusion architectures. We find in experiments with synthetic data effects of the number of hidden layers, the activation function and the data representation. The training set size in relation to the total possible set of vectors also makes a difference. However, the accuracy never exceeds 61% without DR units at 50% chance level. DR units improve generalisation in all tasks and lead to almost perfect test accuracy in the Mid Fusion setting. Thus, DR units seem to be a promising approach for creating generalisation abilities that standard networks lack.