 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolish phonology and morphology through the lens of distributional semantics
Mar 31, 2026This study investigates the relationship between the phonological and morphological structure of Polish words and their meanings using Distributional Semantics. In the present analysis, we ask whether there is a relationship between the form properties of words containing consonant clusters and their meanings. Is the phonological and morphonological structure of complex words mirrored in semantic space? We address these questions for Polish, a language characterized by non-trivial morphology and an impressive inventory of morphologically-motivated consonant clusters. We use statistical and computational techniques, such as t-SNE, Linear Discriminant Analysis and Linear Discriminative Learning, and demonstrate that -- apart from encoding rich morphosyntactic information (e.g. tense, number, case) -- semantic vectors capture information on sub-lexical linguistic units such as phoneme strings. First, phonotactic complexity, morphotactic transparency, and a wide range of morphosyntactic categories available in Polish (case, gender, aspect, tense, number) can be predicted from embeddings without requiring any information about the forms of words. Second, we argue that computational modelling with the discriminative lexicon model using embeddings can provide highly accurate predictions for comprehension and production, exactly because of the existence of extensive information in semantic space that is to a considerable extent isomorphic with structure in the form space.
Analyzing Finnish Inflectional Classes through Discriminative Lexicon and Deep Learning Models
Sep 05, 2025Descriptions of complex nominal or verbal systems make use of inflectional classes. Inflectional classes bring together nouns which have similar stem changes and use similar exponents in their paradigms. Although inflectional classes can be very useful for language teaching as well as for setting up finite state morphological systems, it is unclear whether inflectional classes are cognitively real, in the sense that native speakers would need to discover these classes in order to learn how to properly inflect the nouns of their language. This study investigates whether the Discriminative Lexicon Model (DLM) can understand and produce Finnish inflected nouns without setting up inflectional classes, using a dataset with 55,271 inflected nouns of 2000 high-frequency Finnish nouns from 49 inflectional classes. Several DLM comprehension and production models were set up. Some models were not informed about frequency of use, and provide insight into learnability with infinite exposure (endstate learning). Other models were set up from a usage based perspective, and were trained with token frequencies being taken into consideration (frequency-informed learning). On training data, models performed with very high accuracies. For held-out test data, accuracies decreased, as expected, but remained acceptable. Across most models, performance increased for inflectional classes with more types, more lower-frequency words, and more hapax legomena, mirroring the productivity of the inflectional classes. The model struggles more with novel forms of unproductive and less productive classes, and performs far better for unseen forms belonging to productive classes. However, for usage-based production models, frequency was the dominant predictor of model performance, and correlations with measures of productivity were tenuous or absent.
The realization of tones in spontaneous spoken Taiwan Mandarin: a corpus-based survey and theory-driven computational modeling
Mar 29, 2025



A growing body of literature has demonstrated that semantics can co-determine fine phonetic detail. However, the complex interplay between phonetic realization and semantics remains understudied, particularly in pitch realization. The current study investigates the tonal realization of Mandarin disyllabic words with all 20 possible combinations of two tones, as found in a corpus of Taiwan Mandarin spontaneous speech. We made use of Generalized Additive Mixed Models (GAMs) to model f0 contours as a function of a series of predictors, including gender, tonal context, tone pattern, speech rate, word position, bigram probability, speaker and word. In the GAM analysis, word and sense emerged as crucial predictors of f0 contours, with effect sizes that exceed those of tone pattern. For each word token in our dataset, we then obtained a contextualized embedding by applying the GPT-2 large language model to the context of that token in the corpus. We show that the pitch contours of word tokens can be predicted to a considerable extent from these contextualized embeddings, which approximate token-specific meanings in contexts of use. The results of our corpus study show that meaning in context and phonetic realization are far more entangled than standard linguistic theory predicts.
Is deeper always better? Replacing linear mappings with deep learning networks in the Discriminative Lexicon Model
Oct 05, 2024



Recently, deep learning models have increasingly been used in cognitive modelling of language. This study asks whether deep learning can help us to better understand the learning problem that needs to be solved by speakers, above and beyond linear methods. We utilise the Discriminative Lexicon Model (DLM, Baayen et al., 2019), which models comprehension and production with mappings between numeric form and meaning vectors. While so far, these mappings have been linear (Linear Discriminative Learning, LDL), in the present study we replace them with deep dense neural networks (Deep Discriminative Learning, DDL). We find that DDL affords more accurate mappings for large and diverse datasets from English and Dutch, but not necessarily for Estonian and Taiwan Mandarin. DDL outperforms LDL in particular for words with pseudo-morphological structure such as slend+er. Applied to average reaction times, we find that DDL is outperformed by frequency-informed linear mappings (FIL). However, DDL trained in a frequency-informed way ('frequency-informed' deep learning, FIDDL) substantially outperforms FIL. Finally, while linear mappings can very effectively be updated from trial-to-trial to model incremental lexical learning (Heitmeier et al., 2023), deep mappings cannot do so as effectively. At present, both linear and deep mappings are informative for understanding language.
A corpus-based investigation of pitch contours of monosyllabic words in conversational Taiwan Mandarin
Sep 12, 2024



In Mandarin, the tonal contours of monosyllabic words produced in isolation or in careful speech are characterized by four lexical tones: a high-level tone (T1), a rising tone (T2), a dipping tone (T3) and a falling tone (T4). However, in spontaneous speech, the actual tonal realization of monosyllabic words can deviate significantly from these canonical tones due to intra-syllabic co-articulation and inter-syllabic co-articulation with adjacent tones. In addition, Chuang et al. (2024) recently reported that the tonal contours of disyllabic Mandarin words with T2-T4 tone pattern are co-determined by their meanings. Following up on their research, we present a corpus-based investigation of how the pitch contours of monosyllabic words are realized in spontaneous conversational Mandarin, focusing on the effects of contextual predictors on the one hand, and the way in words' meanings co-determine pitch contours on the other hand. We analyze the F0 contours of 3824 tokens of 63 different word types in a spontaneous Taiwan Mandarin corpus, using the generalized additive (mixed) model to decompose a given observed pitch contour into a set of component pitch contours. We show that the tonal context substantially modify a word's canonical tone. Once the effect of tonal context is controlled for, T2 and T3 emerge as low flat tones, contrasting with T1 as a high tone, and with T4 as a high-to-mid falling tone. The neutral tone (T0), which in standard descriptions, is realized based on the preceding tone, emerges as a low tone in its own right, modified by the other predictors in the same way as the standard tones T1, T2, T3, and T4. We also show that word, and even more so, word sense, co-determine words' F0 contours. Analyses of variable importance using random forests further supported the substantial effect of tonal context and an effect of word sense.
Form and meaning co-determine the realization of tone in Taiwan Mandarin spontaneous speech: the case of Tone 3 sandhi
Aug 28, 2024



In Standard Chinese, Tone 3 (the dipping tone) becomes Tone 2 (rising tone) when followed by another Tone 3. Previous studies have noted that this sandhi process may be incomplete, in the sense that the assimilated Tone 3 is still distinct from a true Tone 2. While Mandarin Tone 3 sandhi is widely studied using carefully controlled laboratory speech (Xu, 1997) and more formal registers of Beijing Mandarin (Yuan and Chen, 2014), less is known about its realization in spontaneous speech, and about the effect of contextual factors on tonal realization. The present study investigates the pitch contours of two-character words with T2-T3 and T3-T3 tone patterns in spontaneous Taiwan Mandarin conversations. Our analysis makes use of the Generative Additive Mixed Model (GAMM, Wood, 2017) to examine fundamental frequency (f0) contours as a function of normalized time. We consider various factors known to influence pitch contours, including gender, speaking rate, speaker, neighboring tones, word position, bigram probability, and also novel predictors, word and word sense (Chuang et al., 2024). Our analyses revealed that in spontaneous Taiwan Mandarin, T3-T3 words become indistinguishable from T2-T3 words, indicating complete sandhi, once the strong effect of word (or word sense) is taken into account. For our data, the shape of f0 contours is not co-determined by word frequency. In contrast, the effect of word meaning on f0 contours is robust, as strong as the effect of adjacent tones, and is present for both T2-T3 and T3-T3 words.
Word-specific tonal realizations in Mandarin
May 11, 2024



The pitch contours of Mandarin two-character words are generally understood as being shaped by the underlying tones of the constituent single-character words, in interaction with articulatory constraints imposed by factors such as speech rate, co-articulation with adjacent tones, segmental make-up, and predictability. This study shows that tonal realization is also partially determined by words' meanings. We first show, on the basis of a Taiwan corpus of spontaneous conversations, using the generalized additive regression model, and focusing on the rise-fall tone pattern, that after controlling for effects of speaker and context, word type is a stronger predictor of pitch realization than all the previously established word-form related predictors combined. Importantly, the addition of information about meaning in context improves prediction accuracy even further. We then proceed to show, using computational modeling with context-specific word embeddings, that token-specific pitch contours predict word type with 50% accuracy on held-out data, and that context-sensitive, token-specific embeddings can predict the shape of pitch contours with 30% accuracy. These accuracies, which are an order of magnitude above chance level, suggest that the relation between words' pitch contours and their meanings are sufficiently strong to be functional for language users. The theoretical implications of these empirical findings are discussed.
Frequency effects in Linear Discriminative Learning
Jun 19, 2023



Word frequency is a strong predictor in most lexical processing tasks. Thus, any model of word recognition needs to account for how word frequency effects arise. The Discriminative Lexicon Model (DLM; Baayen et al., 2018a, 2019) models lexical processing with linear mappings between words' forms and their meanings. So far, the mappings can either be obtained incrementally via error-driven learning, a computationally expensive process able to capture frequency effects, or in an efficient, but frequency-agnostic closed-form solution modelling the theoretical endstate of learning (EL) where all words are learned optimally. In this study we show how an efficient, yet frequency-informed mapping between form and meaning can be obtained (Frequency-informed learning; FIL). We find that FIL well approximates an incremental solution while being computationally much cheaper. FIL shows a relatively low type- and high token-accuracy, demonstrating that the model is able to process most word tokens encountered by speakers in daily life correctly. We use FIL to model reaction times in the Dutch Lexicon Project (Keuleers et al., 2010) and find that FIL predicts well the S-shaped relationship between frequency and the mean of reaction times but underestimates the variance of reaction times for low frequency words. FIL is also better able to account for priming effects in an auditory lexical decision task in Mandarin Chinese (Lee, 2007), compared to EL. Finally, we used ordered data from CHILDES (Brown, 1973; Demuth et al., 2006) to compare mappings obtained with FIL and incremental learning. The mappings are highly correlated, but with FIL some nuances based on word ordering effects are lost. Our results show how frequency effects in a learning model can be simulated efficiently by means of a closed-form solution, and raise questions about how to best account for low-frequency words in cognitive models.
Visual Grounding of Inter-lingual Word-Embeddings
Sep 08, 2022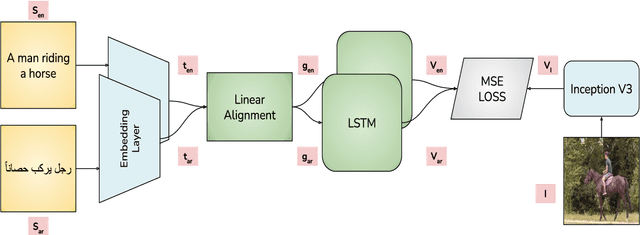
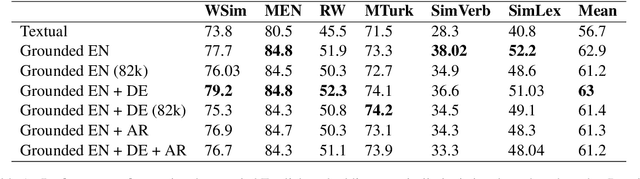
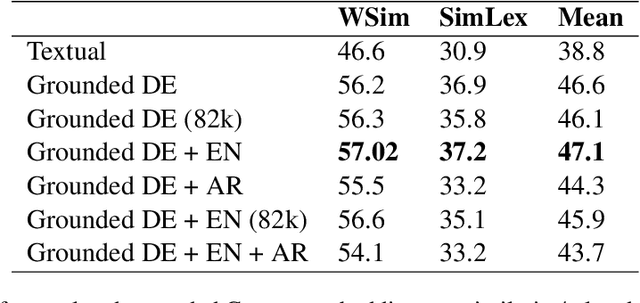
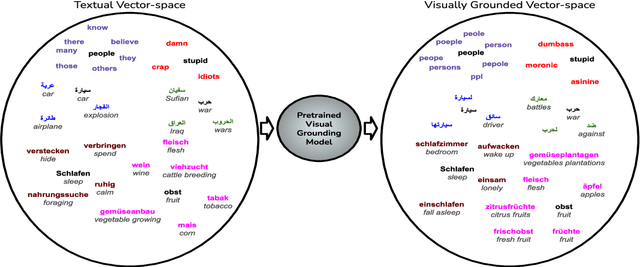
Visual grounding of Language aims at enriching textual representations of language with multiple sources of visual knowledge such as images and videos. Although visual grounding is an area of intense research, inter-lingual aspects of visual grounding have not received much attention. The present study investigates the inter-lingual visual grounding of word embeddings. We propose an implicit alignment technique between the two spaces of vision and language in which inter-lingual textual information interacts in order to enrich pre-trained textual word embeddings. We focus on three languages in our experiments, namely, English, Arabic, and German. We obtained visually grounded vector representations for these languages and studied whether visual grounding on one or multiple languages improved the performance of embeddings on word similarity and categorization benchmarks. Our experiments suggest that inter-lingual knowledge improves the performance of grounded embeddings in similar languages such as German and English. However, inter-lingual grounding of German or English with Arabic led to a slight degradation in performance on word similarity benchmarks. On the other hand, we observed an opposite trend on categorization benchmarks where Arabic had the most improvement on English. In the discussion section, several reasons for those findings are laid out. We hope that our experiments provide a baseline for further research on inter-lingual visual grounding.
Making sense of spoken plurals
Jul 05, 2022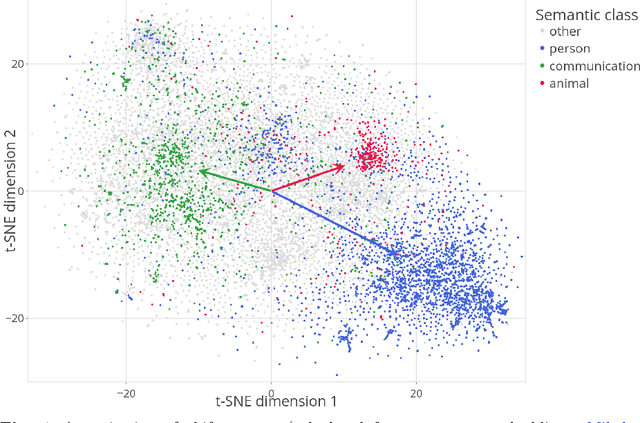
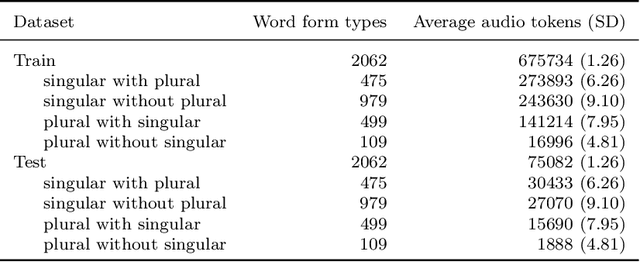

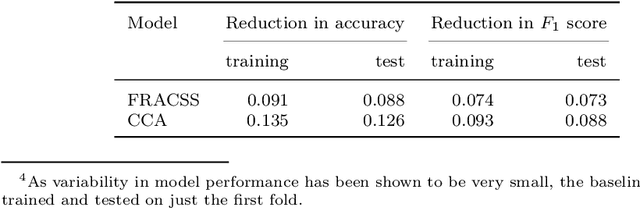
Distributional semantics offers new ways to study the semantics of morphology. This study focuses on the semantics of noun singulars and their plural inflectional variants in English. Our goal is to compare two models for the conceptualization of plurality. One model (FRACSS) proposes that all singular-plural pairs should be taken into account when predicting plural semantics from singular semantics. The other model (CCA) argues that conceptualization for plurality depends primarily on the semantic class of the base word. We compare the two models on the basis of how well the speech signal of plural tokens in a large corpus of spoken American English aligns with the semantic vectors predicted by the two models. Two measures are employed: the performance of a form-to-meaning mapping and the correlations between form distances and meaning distances. Results converge on a superior alignment for CCA. Our results suggest that usage-based approaches to pluralization in which a given word's own semantic neighborhood is given priority outperform theories according to which pluralization is conceptualized as a process building on high-level abstraction. We see that what has often been conceived of as a highly abstract concept, [+plural], is better captured via a family of mid-level partial generalizations.