 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-objective optimization and quantum hybridization of equivariant deep learning interatomic potentials on organic and inorganic compounds
Feb 18, 2026Allegro is a machine learning interatomic potential (MLIP) model designed to predict atomic properties in molecules using E(3) equivariant neural networks. When training this model, there tends to be a trade-off between accuracy and inference time. For this reason we apply multi-objective hyperparameter optimization to the two objectives. Additionally, we experiment with modified architectures by making variants of Allegro some by adding strictly classical multi-layer perceptron (MLP) layers and some by adding quantum-classical hybrid layers. We compare the results from QM9, rMD17-aspirin, rMD17-benzene and our own proprietary dataset consisting of copper and lithium atoms. As results, we have a list of variants that surpass the Allegro in accuracy and also results which demonstrate the trade-off with inference times.
TQCompressor: improving tensor decomposition methods in neural networks via permutations
Jan 29, 2024
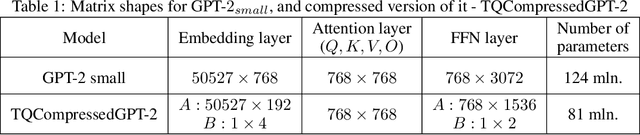
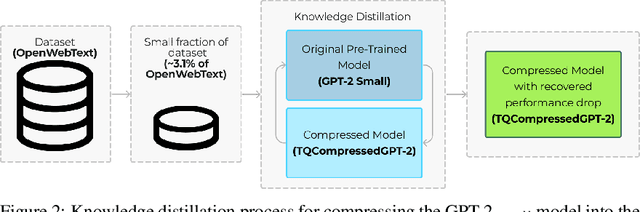

We introduce TQCompressor, a novel method for neural network model compression with improved tensor decompositions. We explore the challenges posed by the computational and storage demands of pre-trained language models in NLP tasks and propose a permutation-based enhancement to Kronecker decomposition. This enhancement makes it possible to reduce loss in model expressivity which is usually associated with factorization. We demonstrate this method applied to the GPT-2$_{small}$. The result of the compression is TQCompressedGPT-2 model, featuring 81 mln. parameters compared to 124 mln. in the GPT-2$_{small}$. We make TQCompressedGPT-2 publicly available. We further enhance the performance of the TQCompressedGPT-2 through a training strategy involving multi-step knowledge distillation, using only a 3.1% of the OpenWebText. TQCompressedGPT-2 surpasses DistilGPT-2 and KnGPT-2 in comparative evaluations, marking an advancement in the efficient and effective deployment of models in resource-constrained environments.