 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixability made efficient: Fast online multiclass logistic regression
Oct 08, 2021
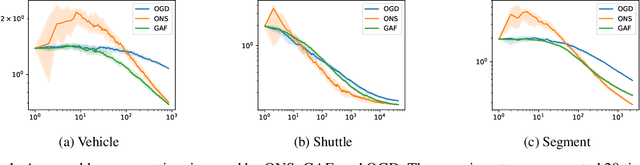
Mixability has been shown to be a powerful tool to obtain algorithms with optimal regret. However, the resulting methods often suffer from high computational complexity which has reduced their practical applicability. For example, in the case of multiclass logistic regression, the aggregating forecaster (Foster et al. (2018)) achieves a regret of $O(\log(Bn))$ whereas Online Newton Step achieves $O(e^B\log(n))$ obtaining a double exponential gain in $B$ (a bound on the norm of comparative functions). However, this high statistical performance is at the price of a prohibitive computational complexity $O(n^{37})$.
Efficient improper learning for online logistic regression
Mar 20, 2020
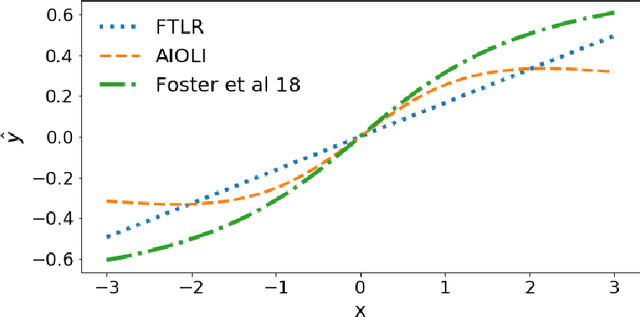
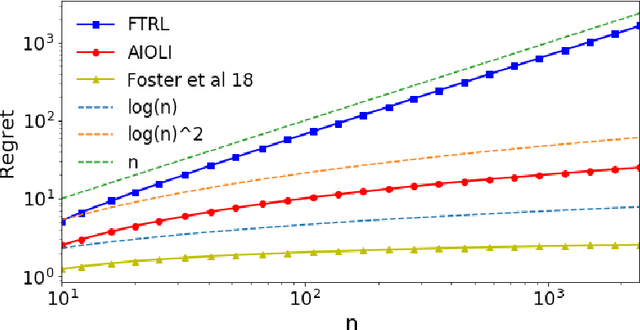
We consider the setting of online logistic regression and consider the regret with respect to the 2-ball of radius B. It is known (see [Hazan et al., 2014]) that any proper algorithm which has logarithmic regret in the number of samples (denoted n) necessarily suffers an exponential multiplicative constant in B. In this work, we design an efficient improper algorithm that avoids this exponential constant while preserving a logarithmic regret. Indeed, [Foster et al., 2018] showed that the lower bound does not apply to improper algorithms and proposed a strategy based on exponential weights with prohibitive computational complexity. Our new algorithm based on regularized empirical risk minimization with surrogate losses satisfies a regret scaling as O(B log(Bn)) with a per-round time-complexity of order O(d^2).
Efficient online learning with kernels for adversarial large scale problems
Feb 26, 2019
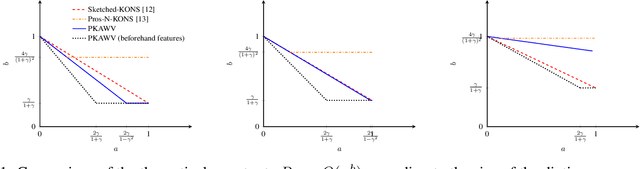
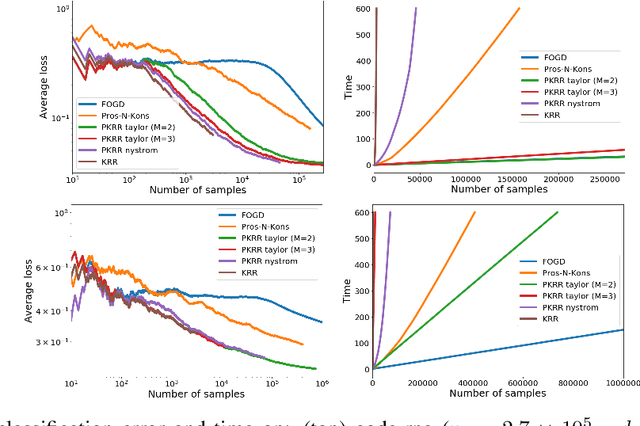
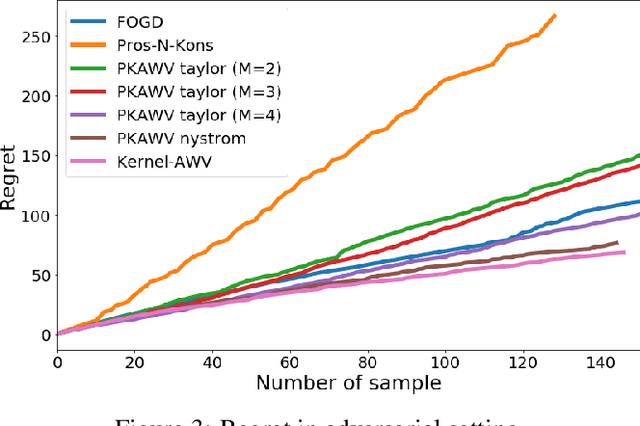
We are interested in a framework of online learning with kernels for low-dimensional but large-scale and potentially adversarial datasets. Considering the Gaussian kernel, we study the computational and theoretical performance of online variations of kernel Ridge regression. The resulting algorithm is based on approximations of the Gaussian kernel through Taylor expansion. It achieves for $d$-dimensional inputs a (close to) optimal regret of order $O((\log n)^{d+1})$ with per-round time complexity and space complexity $O((\log n)^{2d})$. This makes the algorithm a suitable choice as soon as $n \gg e^d$ which is likely to happen in a scenario with small dimensional and large-scale dataset.