 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatically Finding and Validating Unexpected Side-Effects of Interventions on Language Models
May 06, 2026We present an automated, contrastive evaluation pipeline for auditing the behavioral impact of interventions on large language models. Given a base model $M_1$ and an intervention model $M_2$, our method compares their free-form, multi-token generations across aligned prompt contexts and produces human-readable, statistically validated natural-language hypotheses describing how the models differ, along with recurring themes that summarize patterns across validated hypotheses. We evaluate the approach in synthetic setting by injecting known behavioral changes and showing that the pipeline reliably recovers them. We then apply it to three real-world interventions, reasoning distillation, knowledge editing and unlearning, demonstrating that the method surfaces both intended and unexpected behavioral shifts, distinguishes large from subtle interventions, and does not hallucinate differences when effects are absent or misaligned with the prompt bank. Overall, the pipeline provides a statistically grounded and interpretable tool for post-hoc auditing of intervention-induced changes in model behavior.
Neural Networks Learn Statistics of Increasing Complexity
Feb 13, 2024



The distributional simplicity bias (DSB) posits that neural networks learn low-order moments of the data distribution first, before moving on to higher-order correlations. In this work, we present compelling new evidence for the DSB by showing that networks automatically learn to perform well on maximum-entropy distributions whose low-order statistics match those of the training set early in training, then lose this ability later. We also extend the DSB to discrete domains by proving an equivalence between token $n$-gram frequencies and the moments of embedding vectors, and by finding empirical evidence for the bias in LLMs. Finally we use optimal transport methods to surgically edit the low-order statistics of one class to match those of another, and show that early-training networks treat the edited samples as if they were drawn from the target class. Code is available at https://github.com/EleutherAI/features-across-time.
Text Counterfactuals via Latent Optimization and Shapley-Guided Search
Oct 22, 2021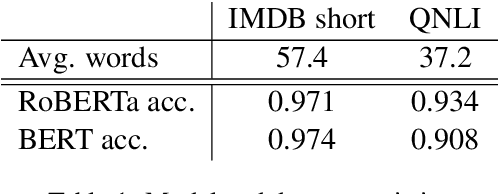
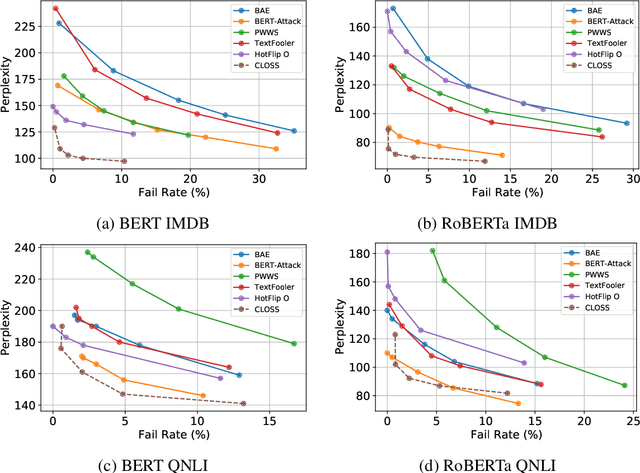
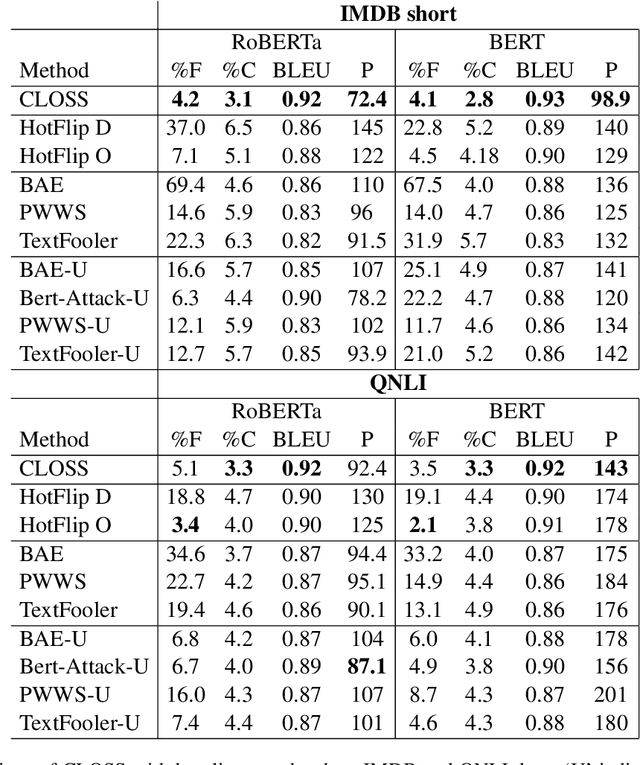
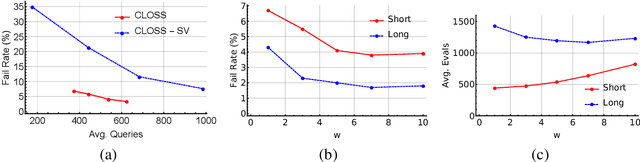
We study the problem of generating counterfactual text for a classifier as a means for understanding and debugging classification. Given a textual input and a classification model, we aim to minimally alter the text to change the model's prediction. White-box approaches have been successfully applied to similar problems in vision where one can directly optimize the continuous input. Optimization-based approaches become difficult in the language domain due to the discrete nature of text. We bypass this issue by directly optimizing in the latent space and leveraging a language model to generate candidate modifications from optimized latent representations. We additionally use Shapley values to estimate the combinatoric effect of multiple changes. We then use these estimates to guide a beam search for the final counterfactual text. We achieve favorable performance compared to recent white-box and black-box baselines using human and automatic evaluations. Ablation studies show that both latent optimization and the use of Shapley values improve success rate and the quality of the generated counterfactuals.