 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-based Capacity Prediction for Lithium-ion Batteries with Data Augmentation
Jul 22, 2024Lithium-ion batteries are pivotal to technological advancements in transportation, electronics, and clean energy storage. The optimal operation and safety of these batteries require proper and reliable estimation of battery capacities to monitor the state of health. Current methods for estimating the capacities fail to adequately account for long-term temporal dependencies of key variables (e.g., voltage, current, and temperature) associated with battery aging and degradation. In this study, we explore the usage of transformer networks to enhance the estimation of battery capacity. We develop a transformer-based battery capacity prediction model that accounts for both long-term and short-term patterns in battery data. Further, to tackle the data scarcity issue, data augmentation is used to increase the data size, which helps to improve the performance of the model. Our proposed method is validated with benchmark datasets. Simulation results show the effectiveness of data augmentation and the transformer network in improving the accuracy and robustness of battery capacity prediction.
Improving Convolutional Neural Networks for Fault Diagnosis by Assimilating Global Features
Oct 03, 2022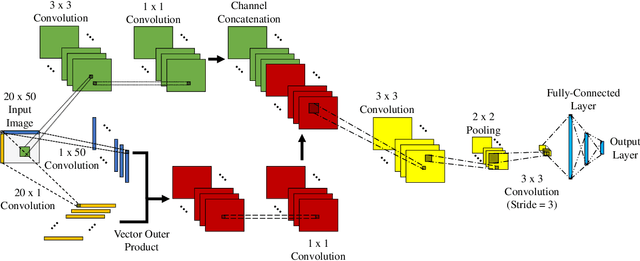
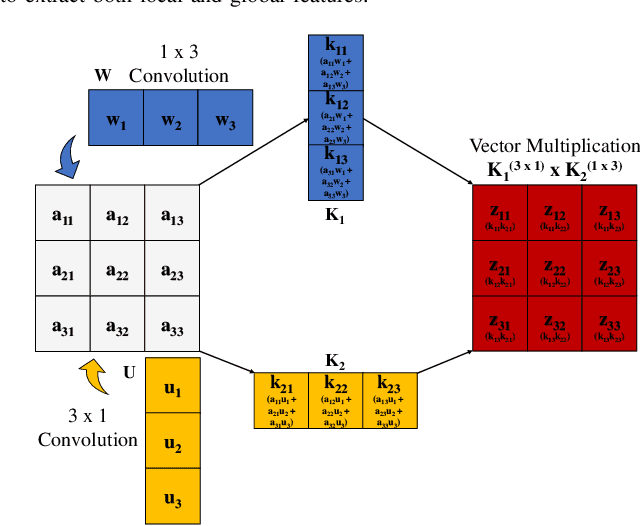
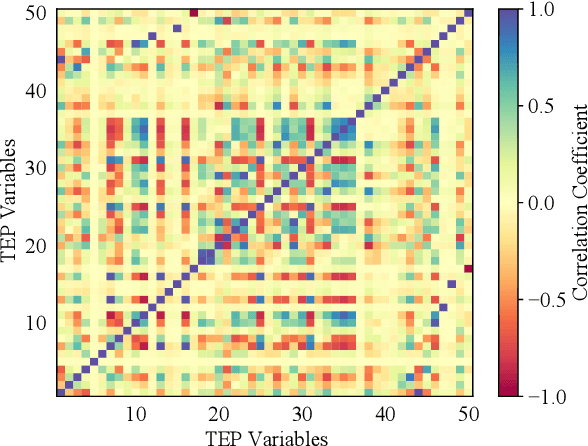
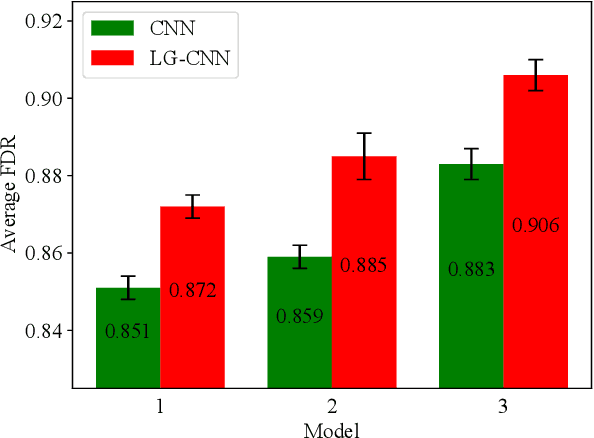
Deep learning techniques have become prominent in modern fault diagnosis for complex processes. In particular, convolutional neural networks (CNNs) have shown an appealing capacity to deal with multivariate time-series data by converting them into images. However, existing CNN techniques mainly focus on capturing local or multi-scale features from input images. A deep CNN is often required to indirectly extract global features, which are critical to describe the images converted from multivariate dynamical data. This paper proposes a novel local-global CNN (LG-CNN) architecture that directly accounts for both local and global features for fault diagnosis. Specifically, the local features are acquired by traditional local kernels whereas global features are extracted by using 1D tall and fat kernels that span the entire height and width of the image. Both local and global features are then merged for classification using fully-connected layers. The proposed LG-CNN is validated on the benchmark Tennessee Eastman process (TEP) dataset. Comparison with traditional CNN shows that the proposed LG-CNN can greatly improve the fault diagnosis performance without significantly increasing the model complexity. This is attributed to the much wider local receptive field created by the LG-CNN than that by CNN. The proposed LG-CNN architecture can be easily extended to other image processing and computer vision tasks.
Unifying Theorems for Subspace Identification and Dynamic Mode Decomposition
Mar 16, 2020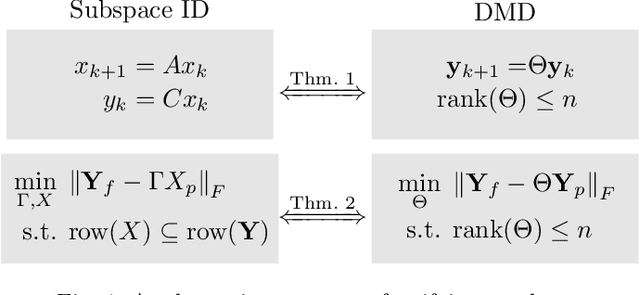
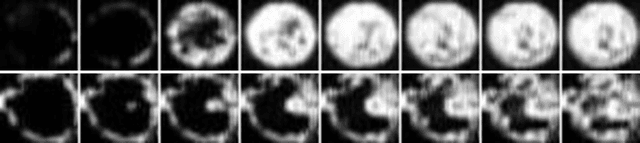
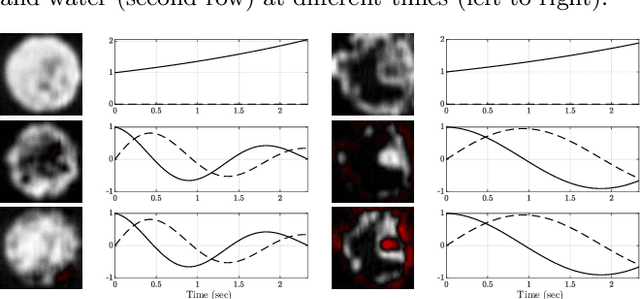
This paper presents unifying results for subspace identification (SID) and dynamic mode decomposition (DMD) for autonomous dynamical systems. We observe that SID seeks to solve an optimization problem to estimate an extended observability matrix and a state sequence that minimizes the prediction error for the state-space model. Moreover, we observe that DMD seeks to solve a rank-constrained matrix regression problem that minimizes the prediction error of an extended autoregressive model. We prove that existence conditions for perfect (error-free) state-space and low-rank extended autoregressive models are equivalent and that the SID and DMD optimization problems are equivalent. We exploit these results to propose a SID-DMD algorithm that delivers a provably optimal model and that is easy to implement. We demonstrate our developments using a case study that aims to build dynamical models directly from video data.