 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization Guarantees for a Binary Classification Framework for Two-Stage Multiple Kernel Learning
Feb 02, 2013We present generalization bounds for the TS-MKL framework for two stage multiple kernel learning. We also present bounds for sparse kernel learning formulations within the TS-MKL framework.
Supervised Learning with Similarity Functions
Oct 22, 2012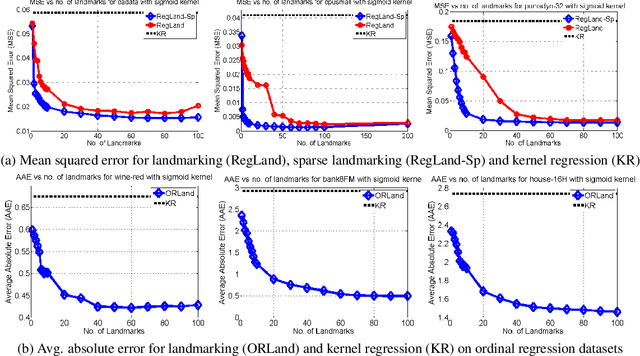
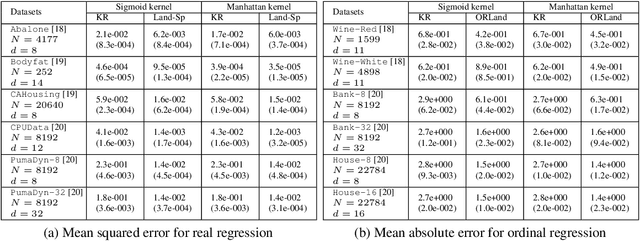
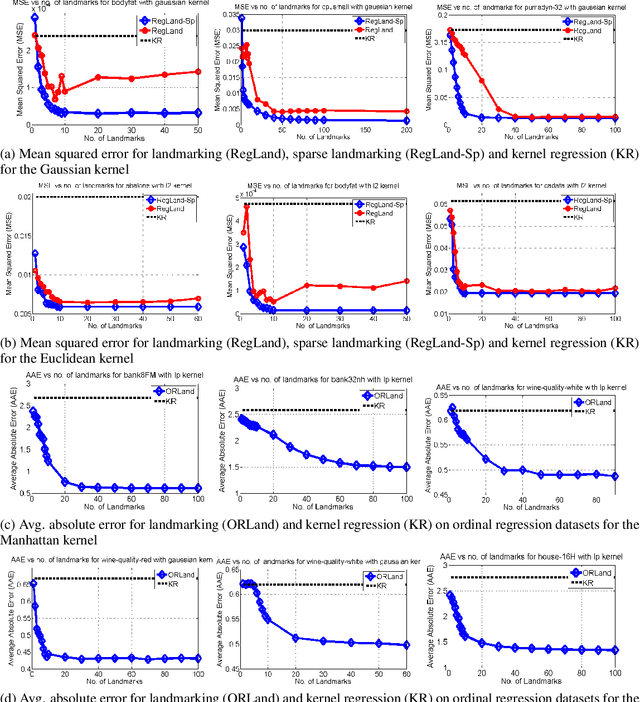
We address the problem of general supervised learning when data can only be accessed through an (indefinite) similarity function between data points. Existing work on learning with indefinite kernels has concentrated solely on binary/multi-class classification problems. We propose a model that is generic enough to handle any supervised learning task and also subsumes the model previously proposed for classification. We give a "goodness" criterion for similarity functions w.r.t. a given supervised learning task and then adapt a well-known landmarking technique to provide efficient algorithms for supervised learning using "good" similarity functions. We demonstrate the effectiveness of our model on three important super-vised learning problems: a) real-valued regression, b) ordinal regression and c) ranking where we show that our method guarantees bounded generalization error. Furthermore, for the case of real-valued regression, we give a natural goodness definition that, when used in conjunction with a recent result in sparse vector recovery, guarantees a sparse predictor with bounded generalization error. Finally, we report results of our learning algorithms on regression and ordinal regression tasks using non-PSD similarity functions and demonstrate the effectiveness of our algorithms, especially that of the sparse landmark selection algorithm that achieves significantly higher accuracies than the baseline methods while offering reduced computational costs.
Random Feature Maps for Dot Product Kernels
Mar 26, 2012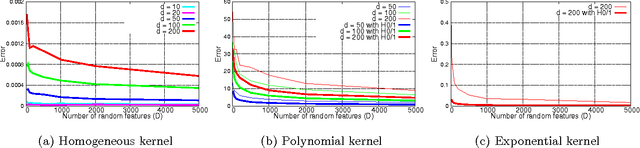
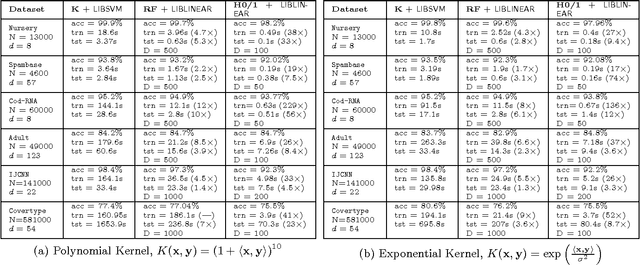
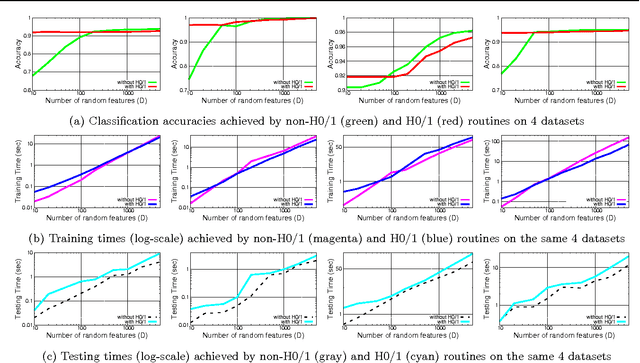
Approximating non-linear kernels using feature maps has gained a lot of interest in recent years due to applications in reducing training and testing times of SVM classifiers and other kernel based learning algorithms. We extend this line of work and present low distortion embeddings for dot product kernels into linear Euclidean spaces. We base our results on a classical result in harmonic analysis characterizing all dot product kernels and use it to define randomized feature maps into explicit low dimensional Euclidean spaces in which the native dot product provides an approximation to the dot product kernel with high confidence.
* To appear in the proceedings of the 15th International Conference on Artificial Intelligence and Statistics (AISTATS 2012). This version corrects a minor error with Lemma 10. Acknowledgements : Devanshu Bhimwal
Similarity-based Learning via Data Driven Embeddings
Dec 22, 2011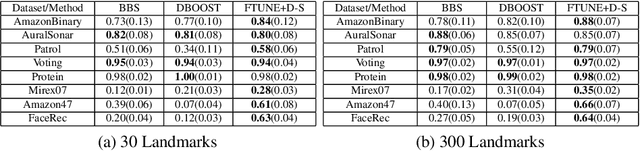

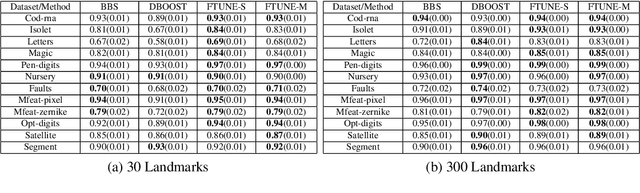

We consider the problem of classification using similarity/distance functions over data. Specifically, we propose a framework for defining the goodness of a (dis)similarity function with respect to a given learning task and propose algorithms that have guaranteed generalization properties when working with such good functions. Our framework unifies and generalizes the frameworks proposed by [Balcan-Blum ICML 2006] and [Wang et al ICML 2007]. An attractive feature of our framework is its adaptability to data - we do not promote a fixed notion of goodness but rather let data dictate it. We show, by giving theoretical guarantees that the goodness criterion best suited to a problem can itself be learned which makes our approach applicable to a variety of domains and problems. We propose a landmarking-based approach to obtaining a classifier from such learned goodness criteria. We then provide a novel diversity based heuristic to perform task-driven selection of landmark points instead of random selection. We demonstrate the effectiveness of our goodness criteria learning method as well as the landmark selection heuristic on a variety of similarity-based learning datasets and benchmark UCI datasets on which our method consistently outperforms existing approaches by a significant margin.
Random Projection Trees Revisited
Oct 20, 2010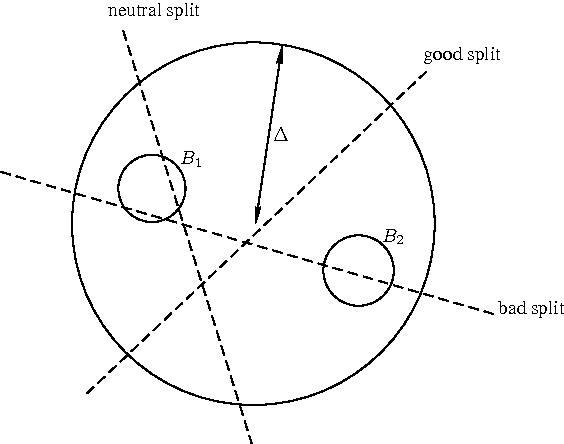
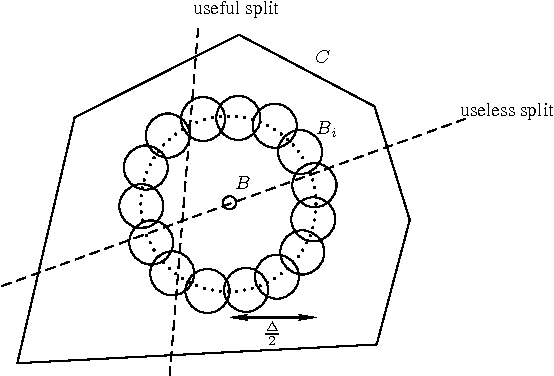
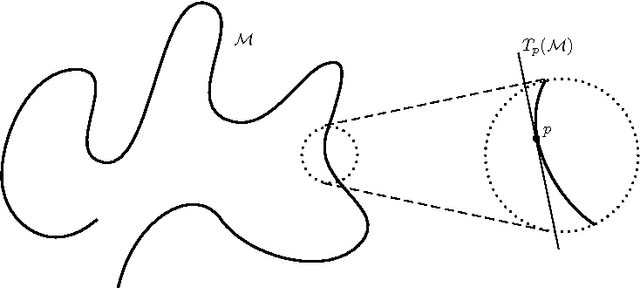
The Random Projection Tree structures proposed in [Freund-Dasgupta STOC08] are space partitioning data structures that automatically adapt to various notions of intrinsic dimensionality of data. We prove new results for both the RPTreeMax and the RPTreeMean data structures. Our result for RPTreeMax gives a near-optimal bound on the number of levels required by this data structure to reduce the size of its cells by a factor $s \geq 2$. We also prove a packing lemma for this data structure. Our final result shows that low-dimensional manifolds have bounded Local Covariance Dimension. As a consequence we show that RPTreeMean adapts to manifold dimension as well.