 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow benign is benign overfitting?
Jul 08, 2020
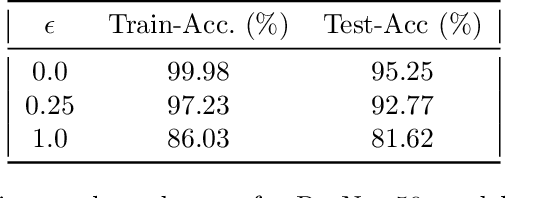
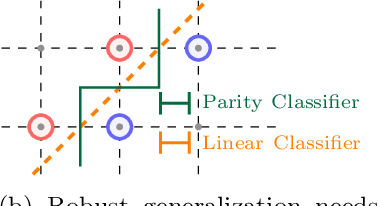
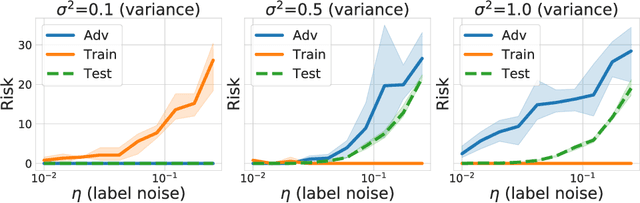
We investigate two causes for adversarial vulnerability in deep neural networks: bad data and (poorly) trained models. When trained with SGD, deep neural networks essentially achieve zero training error, even in the presence of label noise, while also exhibiting good generalization on natural test data, something referred to as benign overfitting [2, 10]. However, these models are vulnerable to adversarial attacks. We identify label noise as one of the causes for adversarial vulnerability, and provide theoretical and empirical evidence in support of this. Surprisingly, we find several instances of label noise in datasets such as MNIST and CIFAR, and that robustly trained models incur training error on some of these, i.e. they don't fit the noise. However, removing noisy labels alone does not suffice to achieve adversarial robustness. Standard training procedures bias neural networks towards learning "simple" classification boundaries, which may be less robust than more complex ones. We observe that adversarial training does produce more complex decision boundaries. We conjecture that in part the need for complex decision boundaries arises from sub-optimal representation learning. By means of simple toy examples, we show theoretically how the choice of representation can drastically affect adversarial robustness.
Deformable Registration through Learning of Context-Specific Metric Aggregation
Jul 19, 2017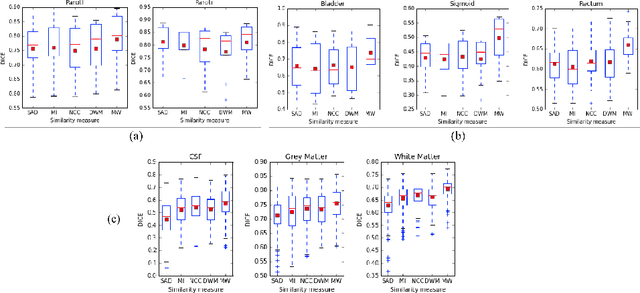
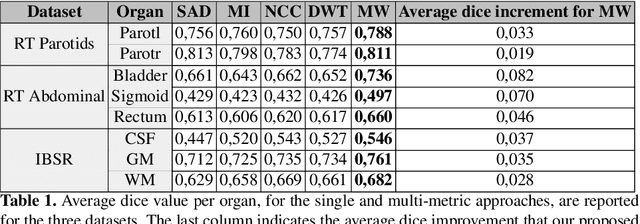
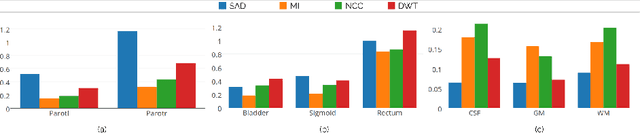
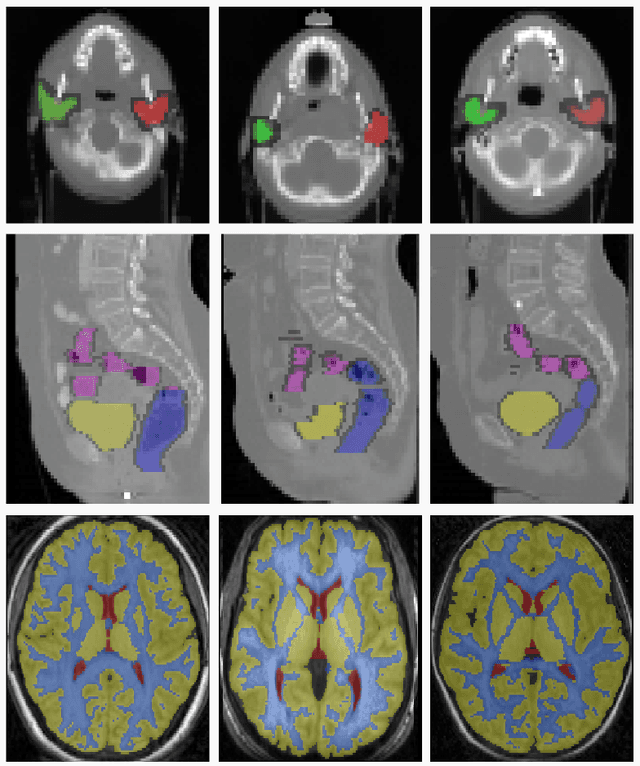
We propose a novel weakly supervised discriminative algorithm for learning context specific registration metrics as a linear combination of conventional similarity measures. Conventional metrics have been extensively used over the past two decades and therefore both their strengths and limitations are known. The challenge is to find the optimal relative weighting (or parameters) of different metrics forming the similarity measure of the registration algorithm. Hand-tuning these parameters would result in sub optimal solutions and quickly become infeasible as the number of metrics increases. Furthermore, such hand-crafted combination can only happen at global scale (entire volume) and therefore will not be able to account for the different tissue properties. We propose a learning algorithm for estimating these parameters locally, conditioned to the data semantic classes. The objective function of our formulation is a special case of non-convex function, difference of convex function, which we optimize using the concave convex procedure. As a proof of concept, we show the impact of our approach on three challenging datasets for different anatomical structures and modalities.