 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA comparative analysis of deep learning models for lung segmentation on X-ray images
Apr 09, 2024


Robust and highly accurate lung segmentation in X-rays is crucial in medical imaging. This study evaluates deep learning solutions for this task, ranking existing methods and analyzing their performance under diverse image modifications. Out of 61 analyzed papers, only nine offered implementation or pre-trained models, enabling assessment of three prominent methods: Lung VAE, TransResUNet, and CE-Net. The analysis revealed that CE-Net performs best, demonstrating the highest values in dice similarity coefficient and intersection over union metric.
Interpretable Machine Learning for Survival Analysis
Mar 15, 2024



With the spread and rapid advancement of black box machine learning models, the field of interpretable machine learning (IML) or explainable artificial intelligence (XAI) has become increasingly important over the last decade. This is particularly relevant for survival analysis, where the adoption of IML techniques promotes transparency, accountability and fairness in sensitive areas, such as clinical decision making processes, the development of targeted therapies, interventions or in other medical or healthcare related contexts. More specifically, explainability can uncover a survival model's potential biases and limitations and provide more mathematically sound ways to understand how and which features are influential for prediction or constitute risk factors. However, the lack of readily available IML methods may have deterred medical practitioners and policy makers in public health from leveraging the full potential of machine learning for predicting time-to-event data. We present a comprehensive review of the limited existing amount of work on IML methods for survival analysis within the context of the general IML taxonomy. In addition, we formally detail how commonly used IML methods, such as such as individual conditional expectation (ICE), partial dependence plots (PDP), accumulated local effects (ALE), different feature importance measures or Friedman's H-interaction statistics can be adapted to survival outcomes. An application of several IML methods to real data on data on under-5 year mortality of Ghanaian children from the Demographic and Health Surveys (DHS) Program serves as a tutorial or guide for researchers, on how to utilize the techniques in practice to facilitate understanding of model decisions or predictions.
Underestimation of lung regions on chest X-ray segmentation masks assessed by comparison with total lung volume evaluated on computed tomography
Feb 18, 2024



Lung mask creation lacks well-defined criteria and standardized guidelines, leading to a high degree of subjectivity between annotators. In this study, we assess the underestimation of lung regions on chest X-ray segmentation masks created according to the current state-of-the-art method, by comparison with total lung volume evaluated on computed tomography (CT). We show, that lung X-ray masks created by following the contours of the heart, mediastinum, and diaphragm significantly underestimate lung regions and exclude substantial portions of the lungs from further assessment, which may result in numerous clinical errors.
NormEnsembleXAI: Unveiling the Strengths and Weaknesses of XAI Ensemble Techniques
Jan 30, 2024This paper presents a comprehensive comparative analysis of explainable artificial intelligence (XAI) ensembling methods. Our research brings three significant contributions. Firstly, we introduce a novel ensembling method, NormEnsembleXAI, that leverages minimum, maximum, and average functions in conjunction with normalization techniques to enhance interpretability. Secondly, we offer insights into the strengths and weaknesses of XAI ensemble methods. Lastly, we provide a library, facilitating the practical implementation of XAI ensembling, thus promoting the adoption of transparent and interpretable deep learning models.
Deep spatial context: when attention-based models meet spatial regression
Jan 18, 2024We propose 'Deep spatial context' (DSCon) method, which serves for investigation of the attention-based vision models using the concept of spatial context. It was inspired by histopathologists, however, the method can be applied to various domains. The DSCon allows for a quantitative measure of the spatial context's role using three Spatial Context Measures: $SCM_{features}$, $SCM_{targets}$, $SCM_{residuals}$ to distinguish whether the spatial context is observable within the features of neighboring regions, their target values (attention scores) or residuals, respectively. It is achieved by integrating spatial regression into the pipeline. The DSCon helps to verify research questions. The experiments reveal that spatial relationships are much bigger in the case of the classification of tumor lesions than normal tissues. Moreover, it turns out that the larger the size of the neighborhood taken into account within spatial regression, the less valuable contextual information is. Furthermore, it is observed that the spatial context measure is the largest when considered within the feature space as opposed to the targets and residuals.
Big Tech influence over AI research revisited: memetic analysis of attribution of ideas to affiliation
Dec 20, 2023



There exists a growing discourse around the domination of Big Tech on the landscape of artificial intelligence (AI) research, yet our comprehension of this phenomenon remains cursory. This paper aims to broaden and deepen our understanding of Big Tech's reach and power within AI research. It highlights the dominance not merely in terms of sheer publication volume but rather in the propagation of new ideas or \textit{memes}. Current studies often oversimplify the concept of influence to the share of affiliations in academic papers, typically sourced from limited databases such as arXiv or specific academic conferences. The main goal of this paper is to unravel the specific nuances of such influence, determining which AI ideas are predominantly driven by Big Tech entities. By employing network and memetic analysis on AI-oriented paper abstracts and their citation network, we are able to grasp a deeper insight into this phenomenon. By utilizing two databases: OpenAlex and S2ORC, we are able to perform such analysis on a much bigger scale than previous attempts. Our findings suggest, that while Big Tech-affiliated papers are disproportionately more cited in some areas, the most cited papers are those affiliated with both Big Tech and Academia. Focusing on the most contagious memes, their attribution to specific affiliation groups (Big Tech, Academia, mixed affiliation) seems to be equally distributed between those three groups. This suggests that the notion of Big Tech domination over AI research is oversimplified in the discourse. Ultimately, this more nuanced understanding of Big Tech's and Academia's influence could inform a more symbiotic alliance between these stakeholders which would better serve the dual goals of societal welfare and the scientific integrity of AI research.
survex: an R package for explaining machine learning survival models
Aug 30, 2023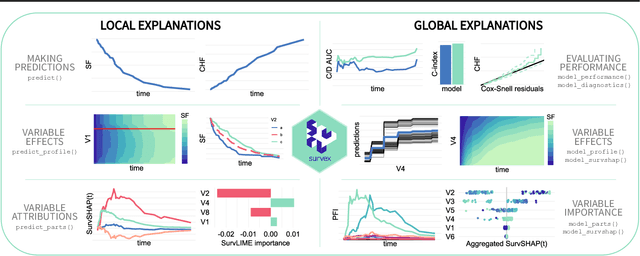
Due to their flexibility and superior performance, machine learning models frequently complement and outperform traditional statistical survival models. However, their widespread adoption is hindered by a lack of user-friendly tools to explain their internal operations and prediction rationales. To tackle this issue, we introduce the survex R package, which provides a cohesive framework for explaining any survival model by applying explainable artificial intelligence techniques. The capabilities of the proposed software encompass understanding and diagnosing survival models, which can lead to their improvement. By revealing insights into the decision-making process, such as variable effects and importances, survex enables the assessment of model reliability and the detection of biases. Thus, transparency and responsibility may be promoted in sensitive areas, such as biomedical research and healthcare applications.
Exploration of Rashomon Set Assists Explanations for Medical Data
Aug 22, 2023



The machine learning modeling process conventionally culminates in selecting a single model that maximizes a selected performance metric. However, this approach leads to abandoning a more profound analysis of slightly inferior models. Particularly in medical and healthcare studies, where the objective extends beyond predictions to valuable insight generation, relying solely on performance metrics can result in misleading or incomplete conclusions. This problem is particularly pertinent when dealing with a set of models with performance close to maximum one, known as $\textit{Rashomon set}$. Such a set can be numerous and may contain models describing the data in a different way, which calls for comprehensive analysis. This paper introduces a novel process to explore Rashomon set models, extending the conventional modeling approach. The cornerstone is the identification of the most different models within the Rashomon set, facilitated by the introduced $\texttt{Rashomon_DETECT}$ algorithm. This algorithm compares profiles illustrating prediction dependencies on variable values generated by eXplainable Artificial Intelligence (XAI) techniques. To quantify differences in variable effects among models, we introduce the Profile Disparity Index (PDI) based on measures from functional data analysis. To illustrate the effectiveness of our approach, we showcase its application in predicting survival among hemophagocytic lymphohistiocytosis (HLH) patients - a foundational case study. Additionally, we benchmark our approach on other medical data sets, demonstrating its versatility and utility in various contexts.
Multi-task learning for classification, segmentation, reconstruction, and detection on chest CT scans
Aug 02, 2023Lung cancer and covid-19 have one of the highest morbidity and mortality rates in the world. For physicians, the identification of lesions is difficult in the early stages of the disease and time-consuming. Therefore, multi-task learning is an approach to extracting important features, such as lesions, from small amounts of medical data because it learns to generalize better. We propose a novel multi-task framework for classification, segmentation, reconstruction, and detection. To the best of our knowledge, we are the first ones who added detection to the multi-task solution. Additionally, we checked the possibility of using two different backbones and different loss functions in the segmentation task.
The Effect of Balancing Methods on Model Behavior in Imbalanced Classification Problems
Jun 30, 2023



Imbalanced data poses a significant challenge in classification as model performance is affected by insufficient learning from minority classes. Balancing methods are often used to address this problem. However, such techniques can lead to problems such as overfitting or loss of information. This study addresses a more challenging aspect of balancing methods - their impact on model behavior. To capture these changes, Explainable Artificial Intelligence tools are used to compare models trained on datasets before and after balancing. In addition to the variable importance method, this study uses the partial dependence profile and accumulated local effects techniques. Real and simulated datasets are tested, and an open-source Python package edgaro is developed to facilitate this analysis. The results obtained show significant changes in model behavior due to balancing methods, which can lead to biased models toward a balanced distribution. These findings confirm that balancing analysis should go beyond model performance comparisons to achieve higher reliability of machine learning models. Therefore, we propose a new method performance gain plot for informed data balancing strategy to make an optimal selection of balancing method by analyzing the measure of change in model behavior versus performance gain.