 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-Key Normalization for Transformers
Oct 08, 2020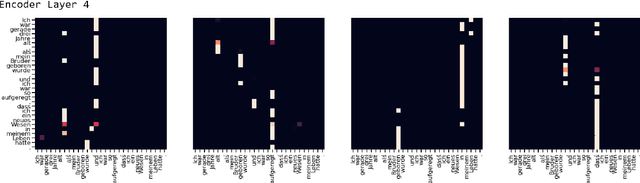

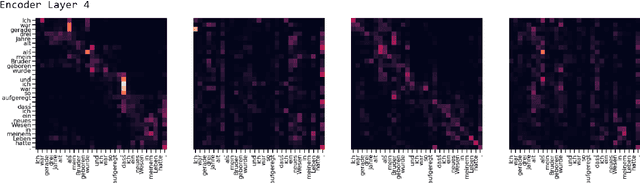

Low-resource language translation is a challenging but socially valuable NLP task. Building on recent work adapting the Transformer's normalization to this setting, we propose QKNorm, a normalization technique that modifies the attention mechanism to make the softmax function less prone to arbitrary saturation without sacrificing expressivity. Specifically, we apply $\ell_2$ normalization along the head dimension of each query and key matrix prior to multiplying them and then scale up by a learnable parameter instead of dividing by the square root of the embedding dimension. We show improvements averaging 0.928 BLEU over state-of-the-art bilingual benchmarks for 5 low-resource translation pairs from the TED Talks corpus and IWSLT'15.
In-depth Question classification using Convolutional Neural Networks
Mar 31, 2018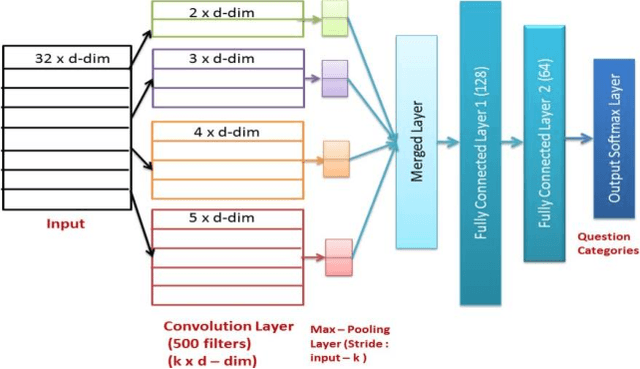
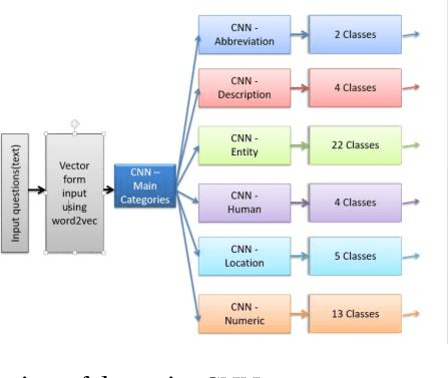

Convolutional neural networks for computer vision are fairly intuitive. In a typical CNN used in image classification, the first layers learn edges, and the following layers learn some filters that can identify an object. But CNNs for Natural Language Processing are not used often and are not completely intuitive. We have a good idea about what the convolution filters learn for the task of text classification, and to that, we propose a neural network structure that will be able to give good results in less time. We will be using convolutional neural networks to predict the primary or broader topic of a question, and then use separate networks for each of these predicted topics to accurately classify their sub-topics.
Facial Emotion Detection Using Convolutional Neural Networks and Representational Autoencoder Units
Jun 05, 2017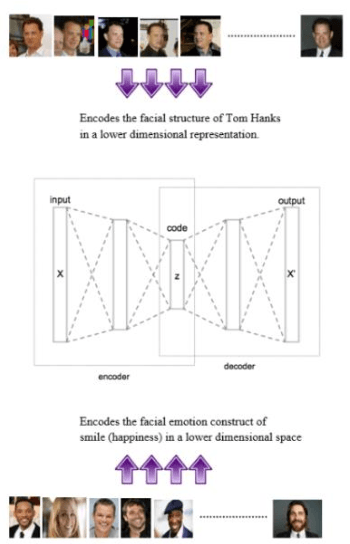
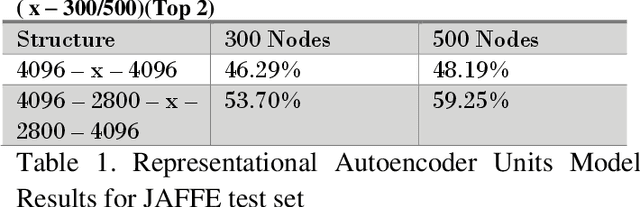
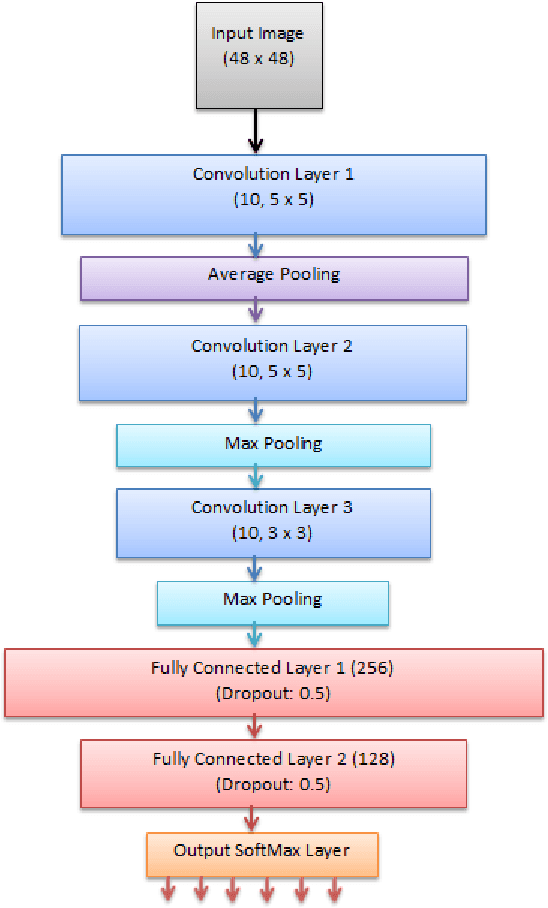
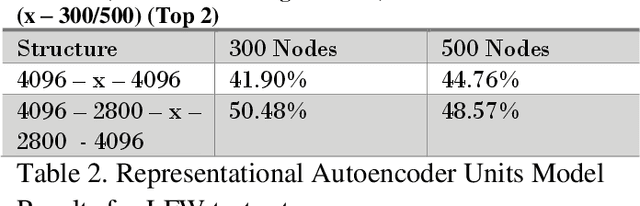
Emotion being a subjective thing, leveraging knowledge and science behind labeled data and extracting the components that constitute it, has been a challenging problem in the industry for many years. With the evolution of deep learning in computer vision, emotion recognition has become a widely-tackled research problem. In this work, we propose two independent methods for this very task. The first method uses autoencoders to construct a unique representation of each emotion, while the second method is an 8-layer convolutional neural network (CNN). These methods were trained on the posed-emotion dataset (JAFFE), and to test their robustness, both the models were also tested on 100 random images from the Labeled Faces in the Wild (LFW) dataset, which consists of images that are candid than posed. The results show that with more fine-tuning and depth, our CNN model can outperform the state-of-the-art methods for emotion recognition. We also propose some exciting ideas for expanding the concept of representational autoencoders to improve their performance.