 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivateSNN: Fully Privacy-Preserving Spiking Neural Networks
Apr 07, 2021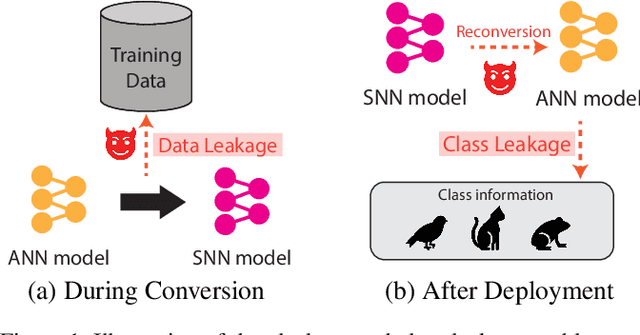
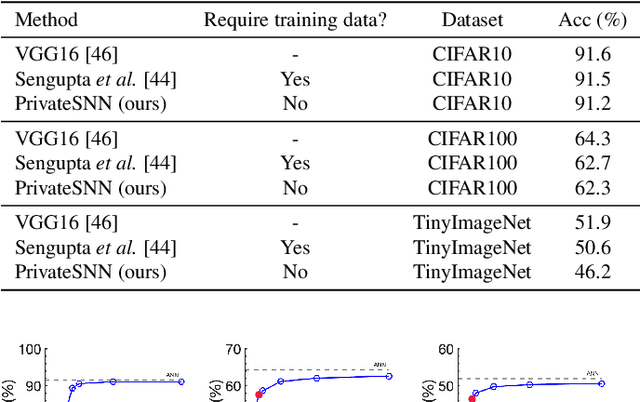

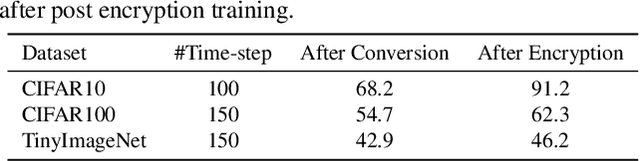
How can we bring both privacy and energy-efficiency to a neural system on edge devices? In this paper, we propose PrivateSNN, which aims to build low-power Spiking Neural Networks (SNNs) from a pre-trained ANN model without leaking sensitive information contained in a dataset. Here, we tackle two types of leakage problems: 1) Data leakage caused when the networks access real training data during an ANN-SNN conversion process. 2) Class leakage is the concept of leakage caused when class-related features can be reconstructed from network parameters. In order to address the data leakage issue, we generate synthetic images from the pre-trained ANNs and convert ANNs to SNNs using generated images. However, converted SNNs are still vulnerable with respect to the class leakage since the weight parameters have the same (or scaled) value with respect to ANN parameters. Therefore, we encrypt SNN weights by training SNNs with a temporal spike-based learning rule. Updating weight parameters with temporal data makes networks difficult to be interpreted in the spatial domain. We observe that the encrypted PrivateSNN can be implemented not only without the huge performance drop (less than ~5%) but also with significant energy-efficiency gain (about x60 compared to the standard ANN). We conduct extensive experiments on various datasets including CIFAR10, CIFAR100, and TinyImageNet, highlighting the importance of privacy-preserving SNN training.
Visual Explanations from Spiking Neural Networks using Interspike Intervals
Mar 26, 2021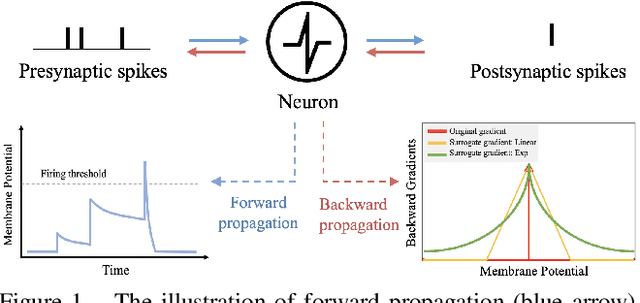
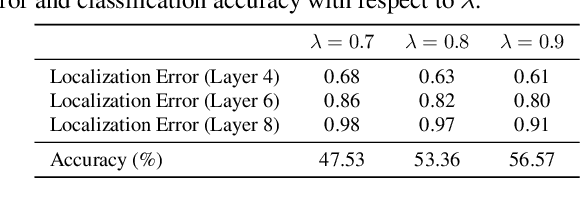
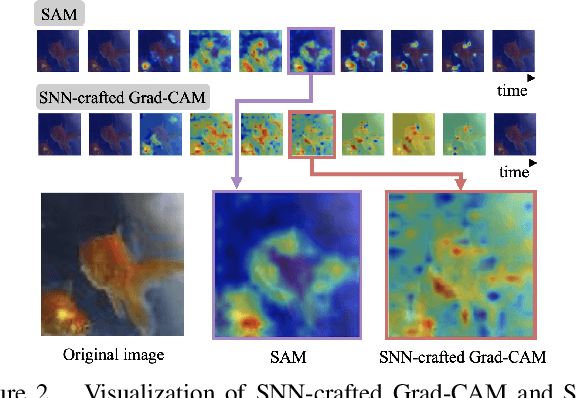
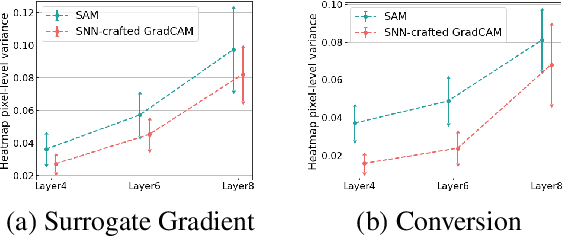
Spiking Neural Networks (SNNs) compute and communicate with asynchronous binary temporal events that can lead to significant energy savings with neuromorphic hardware. Recent algorithmic efforts on training SNNs have shown competitive performance on a variety of classification tasks. However, a visualization tool for analysing and explaining the internal spike behavior of such temporal deep SNNs has not been explored. In this paper, we propose a new concept of bio-plausible visualization for SNNs, called Spike Activation Map (SAM). The proposed SAM circumvents the non-differentiable characteristic of spiking neurons by eliminating the need for calculating gradients to obtain visual explanations. Instead, SAM calculates a temporal visualization map by forward propagating input spikes over different time-steps. SAM yields an attention map corresponding to each time-step of input data by highlighting neurons with short inter-spike interval activity. Interestingly, without both the backpropagation process and the class label, SAM highlights the discriminative region of the image while capturing fine-grained details. With SAM, for the first time, we provide a comprehensive analysis on how internal spikes work in various SNN training configurations depending on optimization types, leak behavior, as well as when faced with adversarial examples.
Activation Density based Mixed-Precision Quantization for Energy Efficient Neural Networks
Jan 12, 2021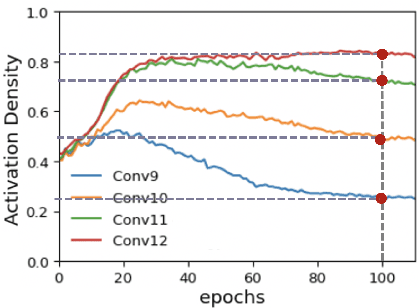
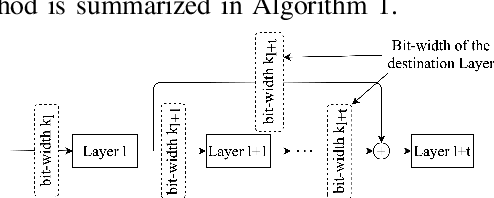
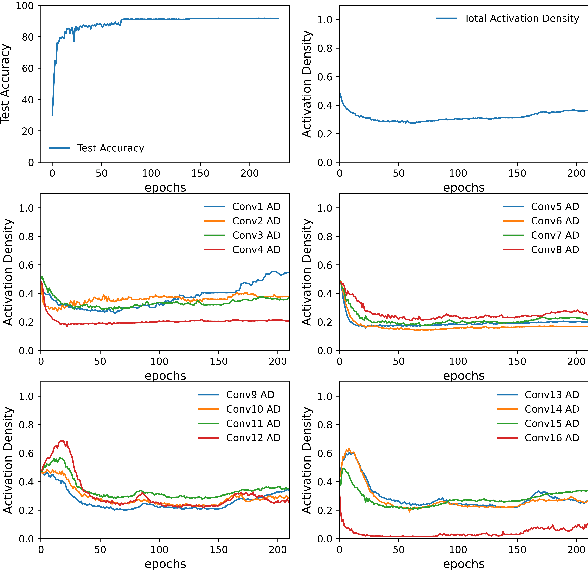
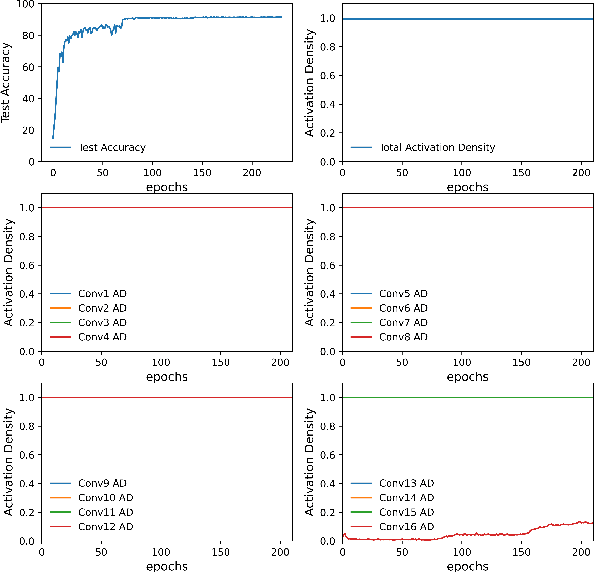
As neural networks gain widespread adoption in embedded devices, there is a need for model compression techniques to facilitate deployment in resource-constrained environments. Quantization is one of the go-to methods yielding state-of-the-art model compression. Most approaches take a fully trained model, apply different heuristics to determine the optimal bit-precision for different layers of the network, and retrain the network to regain any drop in accuracy. Based on Activation Density (AD)-the proportion of non-zero activations in a layer-we propose an in-training quantization method. Our method calculates bit-width for each layer during training yielding a mixed precision model with competitive accuracy. Since we train lower precision models during training, our approach yields the final quantized model at lower training complexity and also eliminates the need for re-training. We run experiments on benchmark datasets like CIFAR-10, CIFAR-100, TinyImagenet on VGG19/ResNet18 architectures and report the accuracy and energy estimates for the same. We achieve ~4.5x benefit in terms of estimated multiply-and-accumulate (MAC) reduction while reducing the training complexity by 50% in our experiments. To further evaluate the energy benefits of our proposed method, we develop a mixed-precision scalable Process In Memory (PIM) hardware accelerator platform. The hardware platform incorporates shift-add functionality for handling multi-bit precision neural network models. Evaluating the quantized models obtained with our proposed method on the PIM platform yields ~5x energy reduction compared to 16-bit models. Additionally, we find that integrating AD based quantization with AD based pruning (both conducted during training) yields up to ~198x and ~44x energy reductions for VGG19 and ResNet18 architectures respectively on PIM platform compared to baseline 16-bit precision, unpruned models.
Noise Sensitivity-Based Energy Efficient and Robust Adversary Detection in Neural Networks
Jan 05, 2021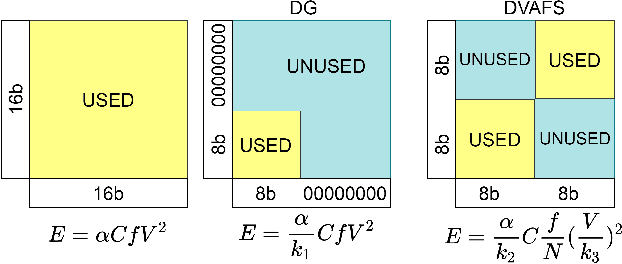
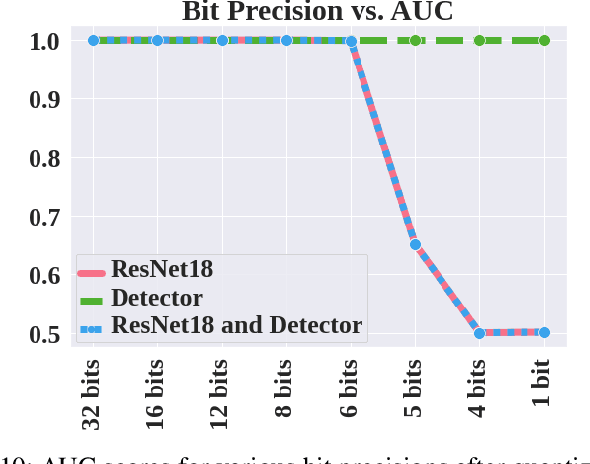
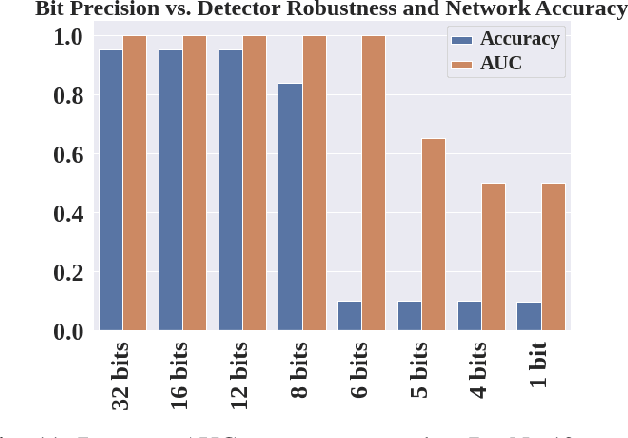
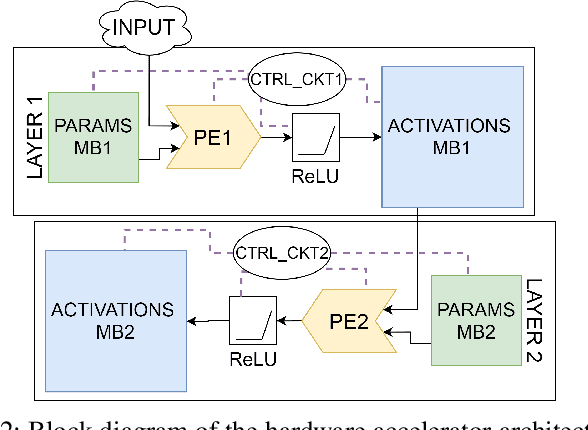
Neural networks have achieved remarkable performance in computer vision, however they are vulnerable to adversarial examples. Adversarial examples are inputs that have been carefully perturbed to fool classifier networks, while appearing unchanged to humans. Based on prior works on detecting adversaries, we propose a structured methodology of augmenting a deep neural network (DNN) with a detector subnetwork. We use $\textit{Adversarial Noise Sensitivity}$ (ANS), a novel metric for measuring the adversarial gradient contribution of different intermediate layers of a network. Based on the ANS value, we append a detector to the most sensitive layer. In prior works, more complex detectors were added to a DNN, increasing the inference computational cost of the model. In contrast, our structured and strategic addition of a detector to a DNN reduces the complexity of the model while making the overall network adversarially resilient. Through comprehensive white-box and black-box experiments on MNIST, CIFAR-10, and CIFAR-100, we show that our method improves state-of-the-art detector robustness against adversarial examples. Furthermore, we validate the energy efficiency of our proposed adversarial detection methodology through an extensive energy analysis on various hardware scalable CMOS accelerator platforms. We also demonstrate the effects of quantization on our detector-appended networks.
Exposing the Robustness and Vulnerability of Hybrid 8T-6T SRAM Memory Architectures to Adversarial Attacks in Deep Neural Networks
Nov 26, 2020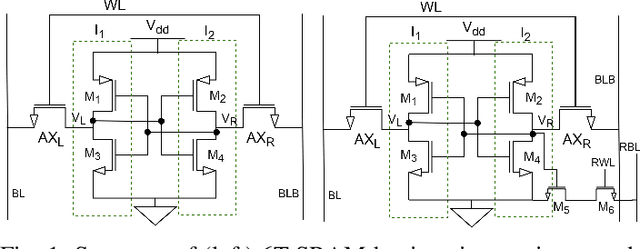
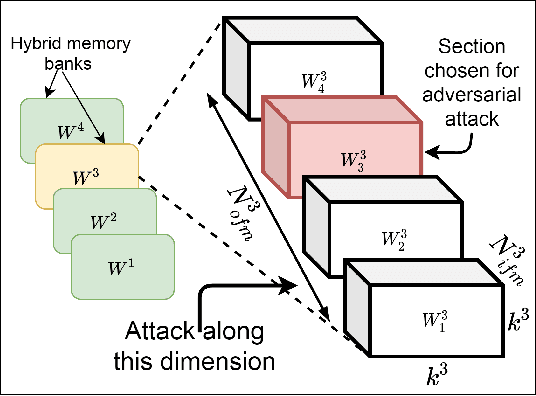
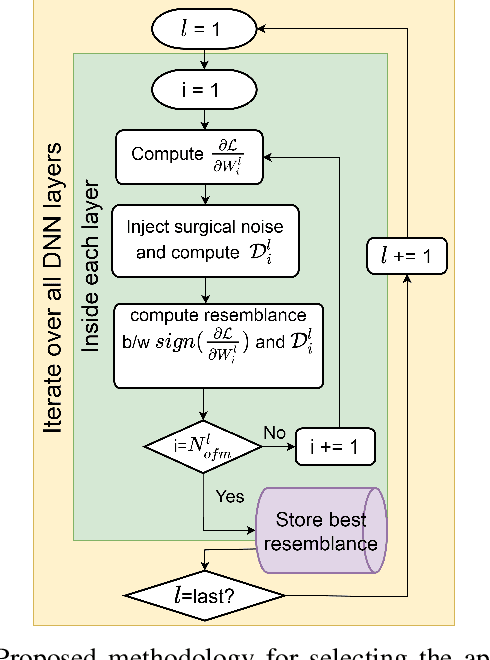
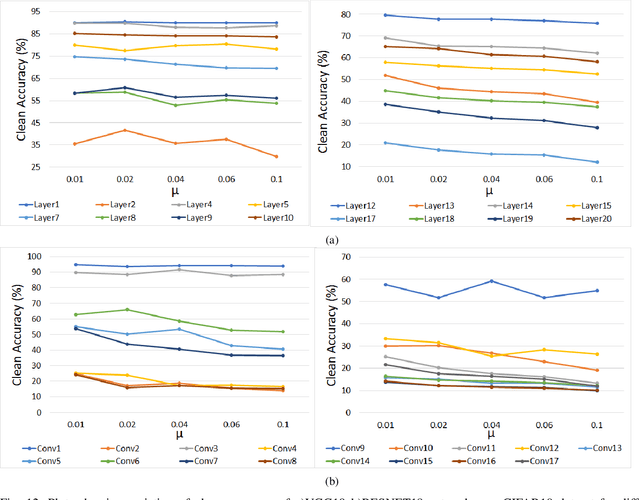
Deep Learning is able to solve a plethora of once impossible problems. However, they are vulnerable to input adversarial attacks preventing them from being autonomously deployed in critical applications. Several algorithm-centered works have discussed methods to cause adversarial attacks and improve adversarial robustness of a Deep Neural Network (DNN). In this work, we elicit the advantages and vulnerabilities of hybrid 6T-8T memories to improve the adversarial robustness and cause adversarial attacks on DNNs. We show that bit-error noise in hybrid memories due to erroneous 6T-SRAM cells have deterministic behaviour based on the hybrid memory configurations (V_DD, 8T-6T ratio). This controlled noise (surgical noise) can be strategically introduced into specific DNN layers to improve the adversarial accuracy of DNNs. At the same time, surgical noise can be carefully injected into the DNN parameters stored in hybrid memory to cause adversarial attacks. To improve the adversarial robustness of DNNs using surgical noise, we propose a methodology to select appropriate DNN layers and their corresponding hybrid memory configurations to introduce the required surgical noise. Using this, we achieve 2-8% higher adversarial accuracy without re-training against white-box attacks like FGSM, than the baseline models (with no surgical noise introduced). To demonstrate adversarial attacks using surgical noise, we design a novel, white-box attack on DNN parameters stored in hybrid memory banks that causes the DNN inference accuracy to drop by more than 60% with over 90% confidence value. We support our claims with experiments, performed using benchmark datasets-CIFAR10 and CIFAR100 on VGG19 and ResNet18 networks.
Revisiting Batch Normalization for Training Low-latency Deep Spiking Neural Networks from Scratch
Oct 27, 2020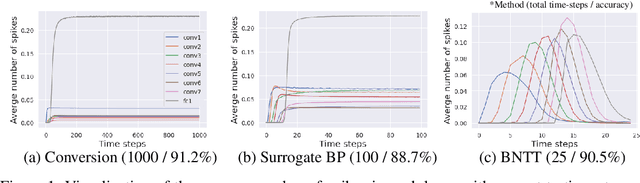
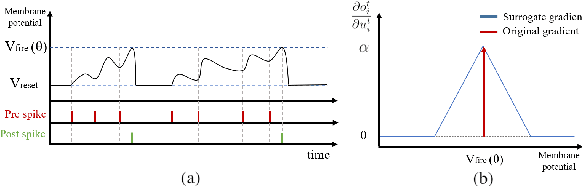
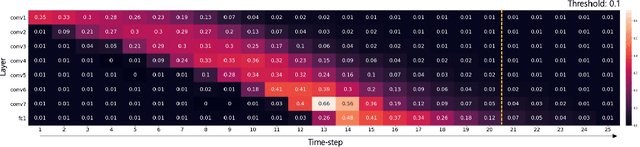

Spiking Neural Networks (SNNs) have recently emerged as an alternative to deep learning owing to sparse, asynchronous and binary event (or spike) driven processing, that can yield huge energy efficiency benefits on neuromorphic hardware. Most existing approaches to create SNNs either convert the weights from pre-trained Artificial Neural Networks (ANNs) or directly train SNNs with surrogate gradient backpropagation. Each approach presents its pros and cons. The ANN-to-SNN conversion method requires at least hundreds of time-steps for inference to yield competitive accuracy that in turn reduces the energy savings. Training SNNs with surrogate gradients from scratch reduces the latency or total number of time-steps, but the training becomes slow/problematic and has convergence issues. Thus, the latter approach of training SNNs has been limited to shallow networks on simple datasets. To address this training issue in SNNs, we revisit batch normalization and propose a temporal Batch Normalization Through Time (BNTT) technique. Most prior SNN works till now have disregarded batch normalization deeming it ineffective for training temporal SNNs. Different from previous works, our proposed BNTT decouples the parameters in a BNTT layer along the time axis to capture the temporal dynamics of spikes. The temporally evolving learnable parameters in BNTT allow a neuron to control its spike rate through different time-steps, enabling low-latency and low-energy training from scratch. We conduct experiments on CIFAR-10, CIFAR-100, Tiny-ImageNet and event-driven DVS-CIFAR10 datasets. BNTT allows us to train deep SNN architectures from scratch, for the first time, on complex datasets with just few 25-30 time-steps. We also propose an early exit algorithm using the distribution of parameters in BNTT to reduce the latency at inference, that further improves the energy-efficiency.
Compression-aware Continual Learning using Singular Value Decomposition
Sep 14, 2020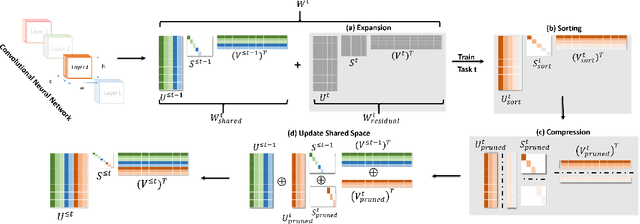
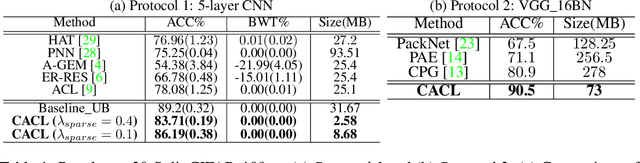


We propose a compression based continual task learning method that can dynamically grow a neural network. Inspired from the recent model compression techniques, we employ compression-aware training and perform low-rank weight approximations using singular value decomposition (SVD) to achieve network compaction. By encouraging the network to learn low-rank weight filters, our method achieves compressed representations with minimal performance degradation without the need for costly fine-tuning. Specifically, we decompose the weight filters using SVD and train the network on incremental tasks in its factorized form. Such a factorization allows us to directly impose sparsity-inducing regularizers over the singular values and allows us to use fewer number of parameters for each task. We further introduce a novel shared representational space based learning between tasks. This promotes the incoming tasks to only learn residual task-specific information on top of the previously learnt weight filters and greatly helps in learning under fixed capacity constraints. Our method significantly outperforms prior continual learning approaches on three benchmark datasets, demonstrating accuracy improvements of 10.3%, 12.3%, 15.6% on 20-split CIFAR-100, miniImageNet and a 5-sequence dataset, respectively, over state-of-the-art. Further, our method yields compressed models that have ~3.64x, 2.88x, 5.91x fewer number of parameters respectively, on the above mentioned datasets in comparison to baseline individual task models. Our source code is available at https://github.com/pavanteja295/CACL.
Rethinking Non-idealities in Memristive Crossbars for Adversarial Robustness in Neural Networks
Aug 25, 2020
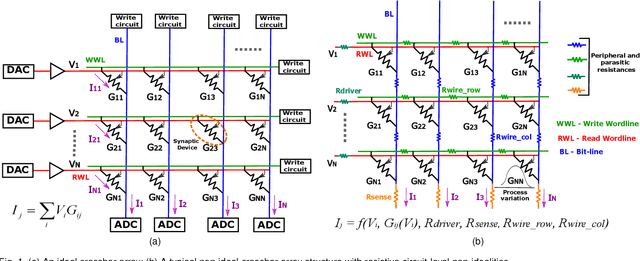
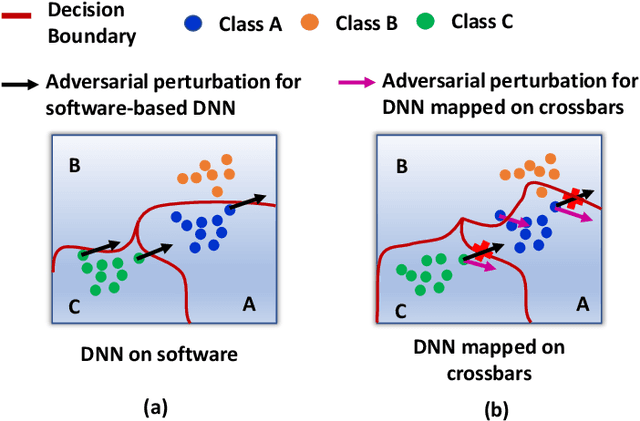

\textit{Deep Neural Networks} (DNNs) have been shown to be prone to adversarial attacks. With a growing need to enable intelligence in embedded devices in this \textit{Internet of Things} (IoT) era, secure hardware implementation of DNNs has become imperative. Memristive crossbars, being able to perform \textit{Matrix-Vector-Multiplications} (MVMs) efficiently, are used to realize DNNs on hardware. However, crossbar non-idealities have always been devalued since they cause errors in performing MVMs, leading to degradation in the accuracy of the DNNs. Several software-based adversarial defenses have been proposed in the past to make DNNs adversarially robust. However, no previous work has demonstrated the advantage conferred by the non-idealities present in analog crossbars in terms of adversarial robustness. In this work, we show that the intrinsic hardware variations manifested through crossbar non-idealities yield adversarial robustness to the mapped DNNs without any additional optimization. We evaluate resilience of state-of-the-art DNNs (VGG8 \& VGG16 networks) using benchmark datasets (CIFAR-10 \& CIFAR-100) across various crossbar sizes towards both hardware and software adversarial attacks. We find that crossbar non-idealities unleash greater adversarial robustness ($>10-20\%$) in DNNs than baseline software DNNs. We further assess the performance of our approach with other state-of-the-art efficiency-driven adversarial defenses and find that our approach performs significantly well in terms of reducing adversarial losses.
Domain Adaptation without Source Data
Jul 11, 2020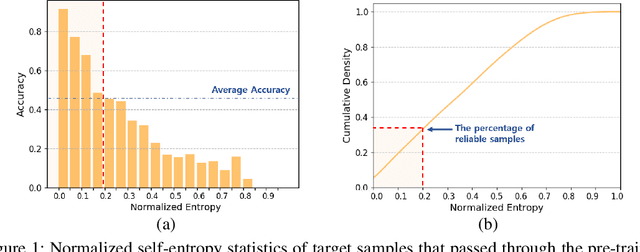
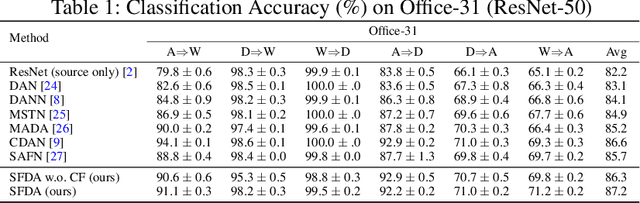
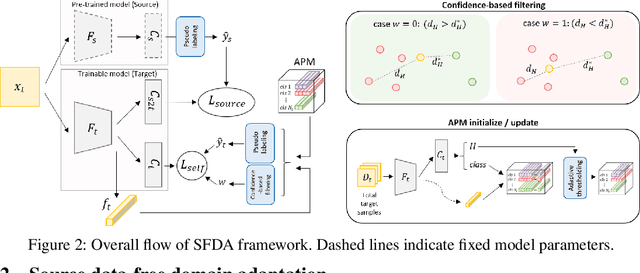

Domain adaptation assumes that samples from source and target domains are freely accessible during a training phase. However, such an assumption is rarely plausible in real cases and possibly causes data-privacy issues, especially when the label of the source domain can be a sensitive attribute as an identifier. To avoid accessing source data which may contain sensitive information, we introduce source data-free domain adaptation (SFDA). Our key idea is to leverage a pre-trained model from the source domain and progressively update the target model in a self-learning manner. We observe that target samples with lower self-entropy measured by the pre-trained source model are more likely to be classified correctly. From this, we select the reliable samples with the self-entropy criterion and define these as class prototypes. We then assign pseudo labels for every target sample based on the similarity score with class prototypes. Further, to reduce the uncertainty from the pseudo labeling process, we propose set-to-set distance-based filtering which does not require any tunable hyperparameters. Finally, we train the target model with the filtered pseudo labels with regularization from the pre-trained source model. Surprisingly, without direct usage of labeled source samples, our SFDA outperforms conventional domain adaptation methods on benchmark datasets. Our code is publicly available at https://github.com/youngryan1993/SFDA-Domain-Adaptation-without-Source-Data.
Enabling Deep Spiking Neural Networks with Hybrid Conversion and Spike Timing Dependent Backpropagation
May 04, 2020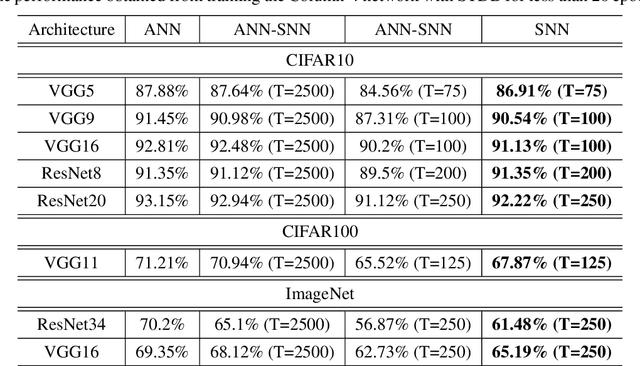
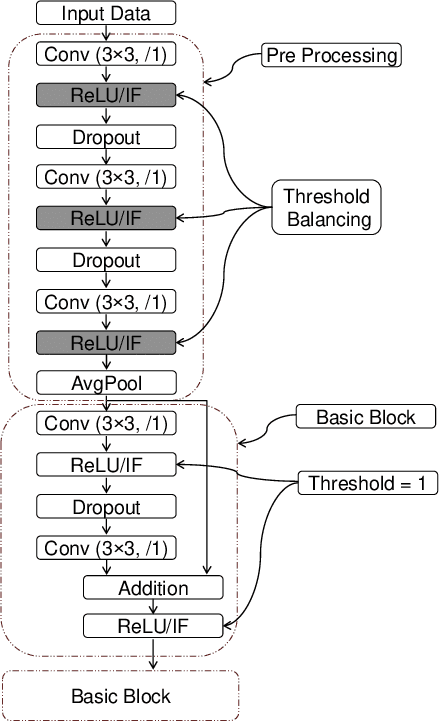
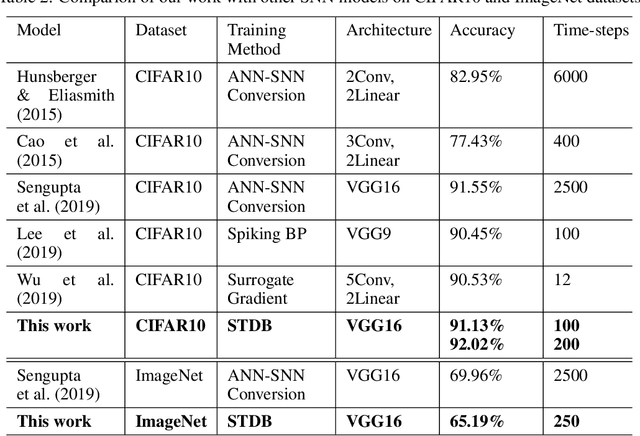
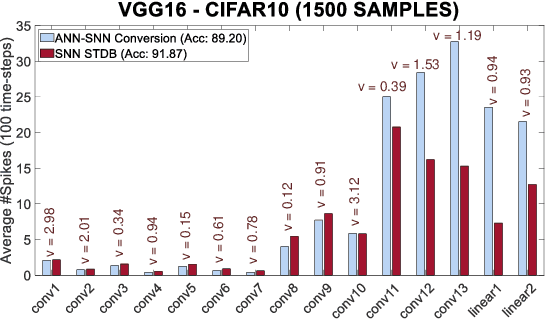
Spiking Neural Networks (SNNs) operate with asynchronous discrete events (or spikes) which can potentially lead to higher energy-efficiency in neuromorphic hardware implementations. Many works have shown that an SNN for inference can be formed by copying the weights from a trained Artificial Neural Network (ANN) and setting the firing threshold for each layer as the maximum input received in that layer. These type of converted SNNs require a large number of time steps to achieve competitive accuracy which diminishes the energy savings. The number of time steps can be reduced by training SNNs with spike-based backpropagation from scratch, but that is computationally expensive and slow. To address these challenges, we present a computationally-efficient training technique for deep SNNs. We propose a hybrid training methodology: 1) take a converted SNN and use its weights and thresholds as an initialization step for spike-based backpropagation, and 2) perform incremental spike-timing dependent backpropagation (STDB) on this carefully initialized network to obtain an SNN that converges within few epochs and requires fewer time steps for input processing. STDB is performed with a novel surrogate gradient function defined using neuron's spike time. The proposed training methodology converges in less than 20 epochs of spike-based backpropagation for most standard image classification datasets, thereby greatly reducing the training complexity compared to training SNNs from scratch. We perform experiments on CIFAR-10, CIFAR-100, and ImageNet datasets for both VGG and ResNet architectures. We achieve top-1 accuracy of 65.19% for ImageNet dataset on SNN with 250 time steps, which is 10X faster compared to converted SNNs with similar accuracy.