 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorkload-Balanced Pruning for Sparse Spiking Neural Networks
Feb 13, 2023Pruning for Spiking Neural Networks (SNNs) has emerged as a fundamental methodology for deploying deep SNNs on resource-constrained edge devices. Though the existing pruning methods can provide extremely high weight sparsity for deep SNNs, the high weight sparsity brings a workload imbalance problem. Specifically, the workload imbalance happens when a different number of non-zero weights are assigned to hardware units running in parallel, which results in low hardware utilization and thus imposes longer latency and higher energy costs. In preliminary experiments, we show that sparse SNNs ($\sim$98% weight sparsity) can suffer as low as $\sim$59% utilization. To alleviate the workload imbalance problem, we propose u-Ticket, where we monitor and adjust the weight connections of the SNN during Lottery Ticket Hypothesis (LTH) based pruning, thus guaranteeing the final ticket gets optimal utilization when deployed onto the hardware. Experiments indicate that our u-Ticket can guarantee up to 100% hardware utilization, thus reducing up to 76.9% latency and 63.8% energy cost compared to the non-utilization-aware LTH method.
DeepCAM: A Fully CAM-based Inference Accelerator with Variable Hash Lengths for Energy-efficient Deep Neural Networks
Feb 09, 2023



With ever increasing depth and width in deep neural networks to achieve state-of-the-art performance, deep learning computation has significantly grown, and dot-products remain dominant in overall computation time. Most prior works are built on conventional dot-product where weighted input summation is used to represent the neuron operation. However, another implementation of dot-product based on the notion of angles and magnitudes in the Euclidean space has attracted limited attention. This paper proposes DeepCAM, an inference accelerator built on two critical innovations to alleviate the computation time bottleneck of convolutional neural networks. The first innovation is an approximate dot-product built on computations in the Euclidean space that can replace addition and multiplication with simple bit-wise operations. The second innovation is a dynamic size content addressable memory-based (CAM-based) accelerator to perform bit-wise operations and accelerate the CNNs with a lower computation time. Our experiments on benchmark image recognition datasets demonstrate that DeepCAM is up to 523x and 3498x faster than Eyeriss and traditional CPUs like Intel Skylake, respectively. Furthermore, the energy consumed by our DeepCAM approach is 2.16x to 109x less compared to Eyeriss.
* Accepted to Design, Automation and Test in Europe (DATE) Conference, 2023
Exploring Temporal Information Dynamics in Spiking Neural Networks
Nov 30, 2022



Most existing Spiking Neural Network (SNN) works state that SNNs may utilize temporal information dynamics of spikes. However, an explicit analysis of temporal information dynamics is still missing. In this paper, we ask several important questions for providing a fundamental understanding of SNNs: What are temporal information dynamics inside SNNs? How can we measure the temporal information dynamics? How do the temporal information dynamics affect the overall learning performance? To answer these questions, we estimate the Fisher Information of the weights to measure the distribution of temporal information during training in an empirical manner. Surprisingly, as training goes on, Fisher information starts to concentrate in the early timesteps. After training, we observe that information becomes highly concentrated in earlier few timesteps, a phenomenon we refer to as temporal information concentration. We observe that the temporal information concentration phenomenon is a common learning feature of SNNs by conducting extensive experiments on various configurations such as architecture, dataset, optimization strategy, time constant, and timesteps. Furthermore, to reveal how temporal information concentration affects the performance of SNNs, we design a loss function to change the trend of temporal information. We find that temporal information concentration is crucial to building a robust SNN but has little effect on classification accuracy. Finally, we propose an efficient iterative pruning method based on our observation on temporal information concentration. Code is available at https://github.com/Intelligent-Computing-Lab-Yale/Exploring-Temporal-Information-Dynamics-in-Spiking-Neural-Networks.
Wearable-based Human Activity Recognition with Spatio-Temporal Spiking Neural Networks
Nov 14, 2022



We study the Human Activity Recognition (HAR) task, which predicts user daily activity based on time series data from wearable sensors. Recently, researchers use end-to-end Artificial Neural Networks (ANNs) to extract the features and perform classification in HAR. However, ANNs pose a huge computation burden on wearable devices and lack temporal feature extraction. In this work, we leverage Spiking Neural Networks (SNNs)--an architecture inspired by biological neurons--to HAR tasks. SNNs allow spatio-temporal extraction of features and enjoy low-power computation with binary spikes. We conduct extensive experiments on three HAR datasets with SNNs, demonstrating that SNNs are on par with ANNs in terms of accuracy while reducing up to 94% energy consumption. The code is publicly available in https://github.com/Intelligent-Computing-Lab-Yale/SNN_HAR
SpikeSim: An end-to-end Compute-in-Memory Hardware Evaluation Tool for Benchmarking Spiking Neural Networks
Oct 24, 2022SNNs are an active research domain towards energy efficient machine intelligence. Compared to conventional ANNs, SNNs use temporal spike data and bio-plausible neuronal activation functions such as Leaky-Integrate Fire/Integrate Fire (LIF/IF) for data processing. However, SNNs incur significant dot-product operations causing high memory and computation overhead in standard von-Neumann computing platforms. Today, In-Memory Computing (IMC) architectures have been proposed to alleviate the "memory-wall bottleneck" prevalent in von-Neumann architectures. Although recent works have proposed IMC-based SNN hardware accelerators, the following have been overlooked- 1) the adverse effects of crossbar non-ideality on SNN performance due to repeated analog dot-product operations over multiple time-steps, 2) hardware overheads of essential SNN-specific components such as the LIF/IF and data communication modules. To this end, we propose SpikeSim, a tool that can perform realistic performance, energy, latency and area evaluation of IMC-mapped SNNs. SpikeSim consists of a practical monolithic IMC architecture called SpikeFlow for mapping SNNs. Additionally, the non-ideality computation engine (NICE) and energy-latency-area (ELA) engine performs hardware-realistic evaluation of SpikeFlow-mapped SNNs. Based on 65nm CMOS implementation and experiments on CIFAR10, CIFAR100 and TinyImagenet datasets, we find that the LIF/IF neuronal module has significant area contribution (>11% of the total hardware area). We propose SNN topological modifications leading to 1.24x and 10x reduction in the neuronal module's area and the overall energy-delay-product value, respectively. Furthermore, in this work, we perform a holistic comparison between IMC implemented ANN and SNNs and conclude that lower number of time-steps are the key to achieve higher throughput and energy-efficiency for SNNs compared to 4-bit ANNs.
Lottery Ticket Hypothesis for Spiking Neural Networks
Jul 04, 2022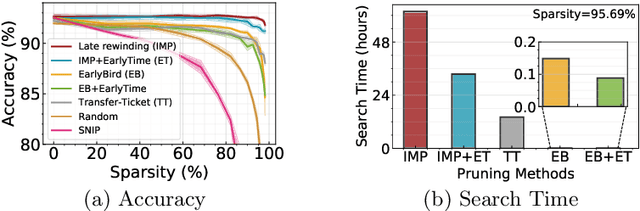
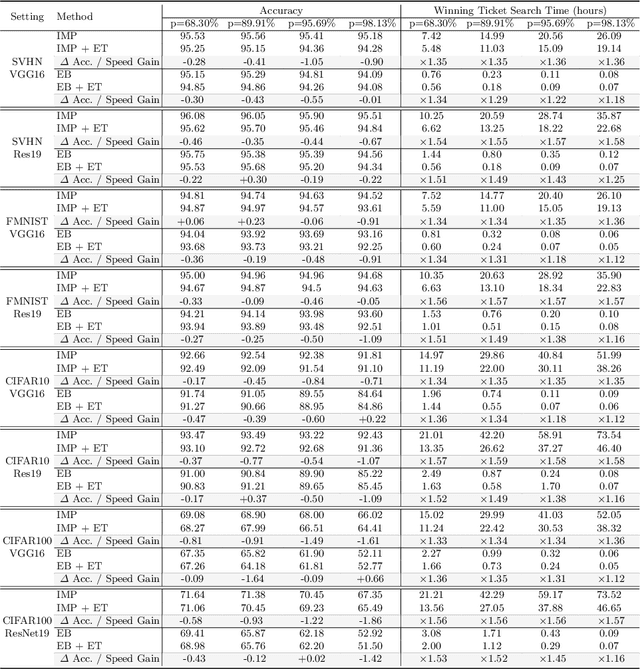
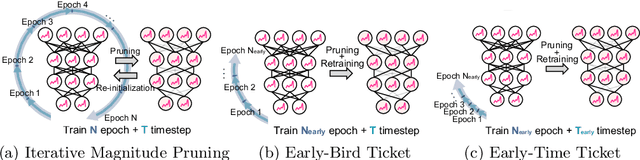
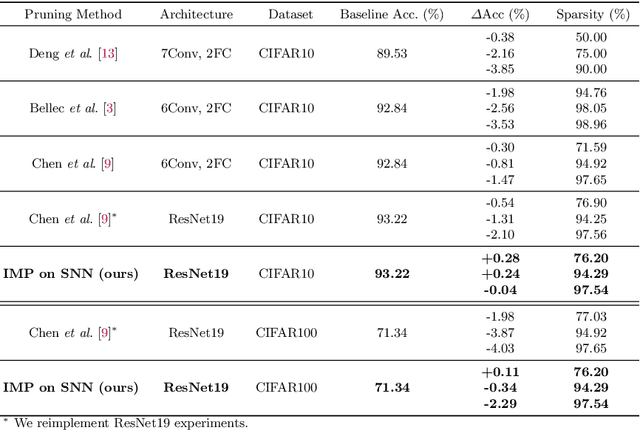
Spiking Neural Networks (SNNs) have recently emerged as a new generation of low-power deep neural networks where binary spikes convey information across multiple timesteps. Pruning for SNNs is highly important as they become deployed on a resource-constraint mobile/edge device. The previous SNN pruning works focus on shallow SNNs (2~6 layers), however, deeper SNNs (>16 layers) are proposed by state-of-the-art SNN works, which is difficult to be compatible with the current pruning work. To scale up a pruning technique toward deep SNNs, we investigate Lottery Ticket Hypothesis (LTH) which states that dense networks contain smaller subnetworks (i.e., winning tickets) that achieve comparable performance to the dense networks. Our studies on LTH reveal that the winning tickets consistently exist in deep SNNs across various datasets and architectures, providing up to 97% sparsity without huge performance degradation. However, the iterative searching process of LTH brings a huge training computational cost when combined with the multiple timesteps of SNNs. To alleviate such heavy searching cost, we propose Early-Time (ET) ticket where we find the important weight connectivity from a smaller number of timesteps. The proposed ET ticket can be seamlessly combined with common pruning techniques for finding winning tickets, such as Iterative Magnitude Pruning (IMP) and Early-Bird (EB) tickets. Our experiment results show that the proposed ET ticket reduces search time by up to 38% compared to IMP or EB methods.
Examining the Robustness of Spiking Neural Networks on Non-ideal Memristive Crossbars
Jun 20, 2022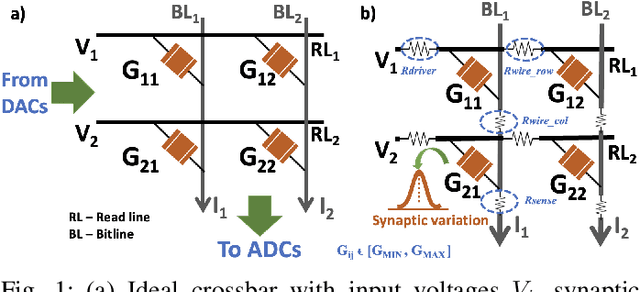
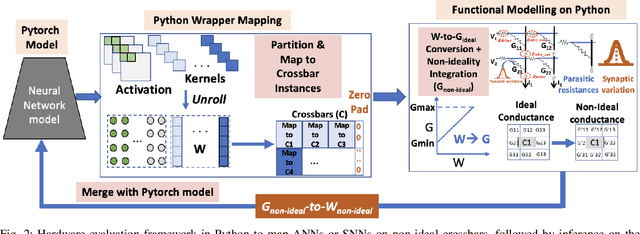
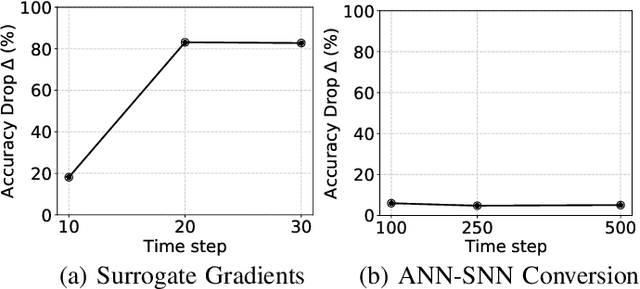
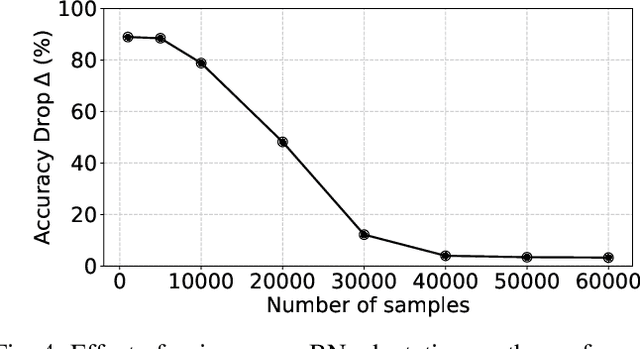
Spiking Neural Networks (SNNs) have recently emerged as the low-power alternative to Artificial Neural Networks (ANNs) owing to their asynchronous, sparse, and binary information processing. To improve the energy-efficiency and throughput, SNNs can be implemented on memristive crossbars where Multiply-and-Accumulate (MAC) operations are realized in the analog domain using emerging Non-Volatile-Memory (NVM) devices. Despite the compatibility of SNNs with memristive crossbars, there is little attention to study on the effect of intrinsic crossbar non-idealities and stochasticity on the performance of SNNs. In this paper, we conduct a comprehensive analysis of the robustness of SNNs on non-ideal crossbars. We examine SNNs trained via learning algorithms such as, surrogate gradient and ANN-SNN conversion. Our results show that repetitive crossbar computations across multiple time-steps induce error accumulation, resulting in a huge performance drop during SNN inference. We further show that SNNs trained with a smaller number of time-steps achieve better accuracy when deployed on memristive crossbars.
SATA: Sparsity-Aware Training Accelerator for Spiking Neural Networks
Apr 11, 2022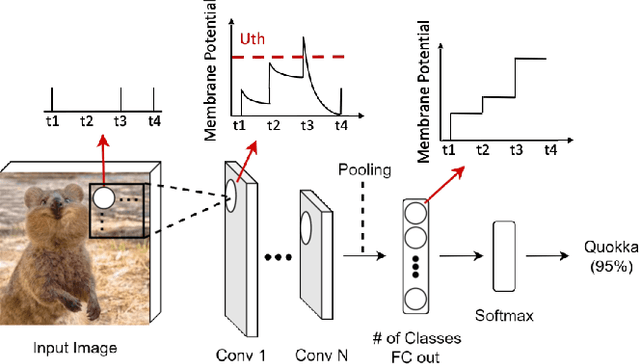
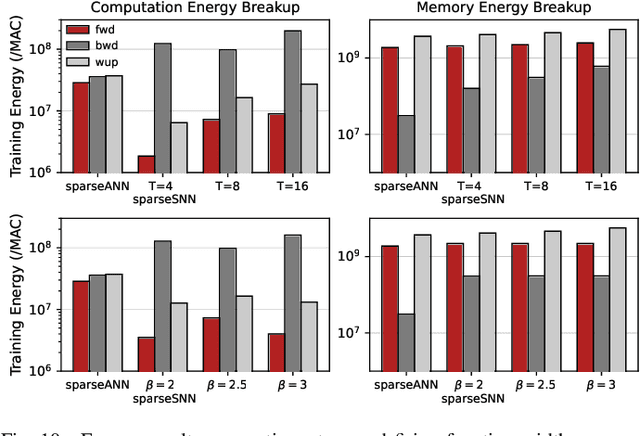
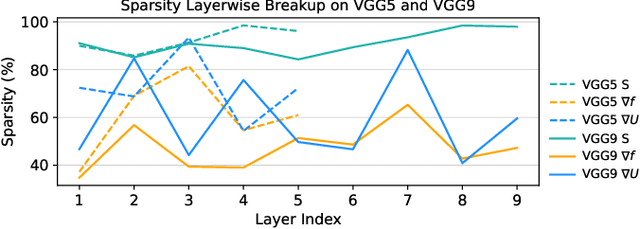
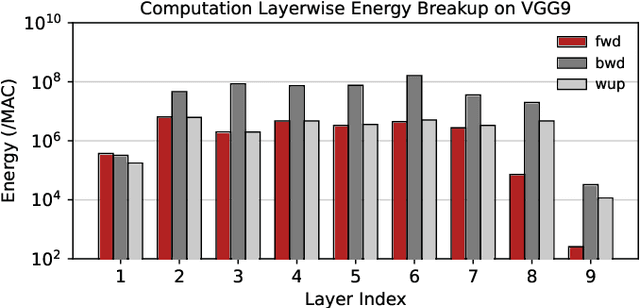
Spiking Neural Networks (SNNs) have gained huge attention as a potential energy-efficient alternative to conventional Artificial Neural Networks (ANNs) due to their inherent high-sparsity activation. Recently, SNNs with backpropagation through time (BPTT) have achieved a higher accuracy result on image recognition tasks compared to other SNN training algorithms. Despite the success on the algorithm perspective, prior works neglect the evaluation of the hardware energy overheads of BPTT, due to the lack of a hardware evaluation platform for SNN training algorithm design. Moreover, although SNNs have been long seen as an energy-efficient counterpart of ANNs, a quantitative comparison between the training cost of SNNs and ANNs is missing. To address the above-mentioned issues, in this work, we introduce SATA (Sparsity-Aware Training Accelerator), a BPTT-based training accelerator for SNNs. The proposed SATA provides a simple and re-configurable accelerator architecture for the general-purpose hardware evaluation platform, which makes it easier to analyze the training energy for SNN training algorithms. Based on SATA, we show quantitative analyses on the energy efficiency of SNN training and make a comparison between the training cost of SNNs and ANNs. The results show that SNNs consume $1.27\times$ more total energy with considering sparsity (spikes, gradient of firing function, and gradient of membrane potential) when compared to ANNs. We find that such high training energy cost is from time-repetitive convolution operations and data movements during backpropagation. Moreover, to guide the future SNN training algorithm design, we provide several observations on energy efficiency with respect to different SNN-specific training parameters.
MIME: Adapting a Single Neural Network for Multi-task Inference with Memory-efficient Dynamic Pruning
Apr 11, 2022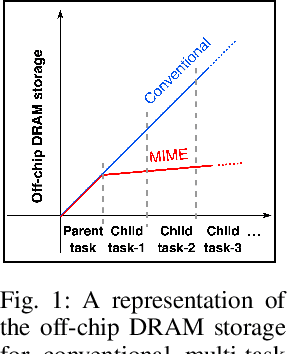
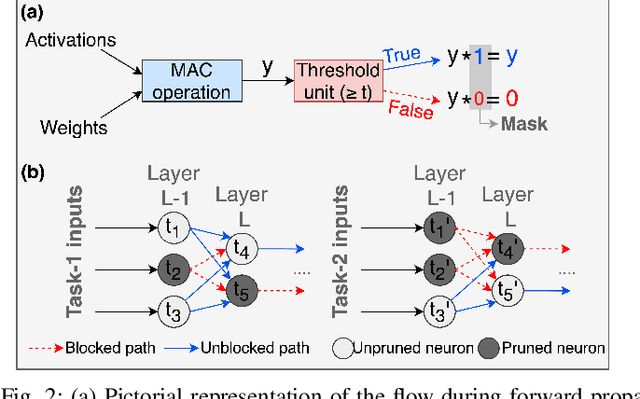
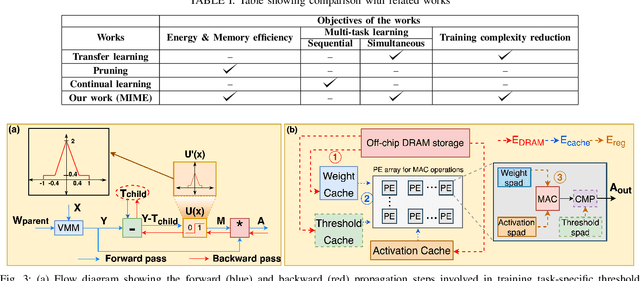
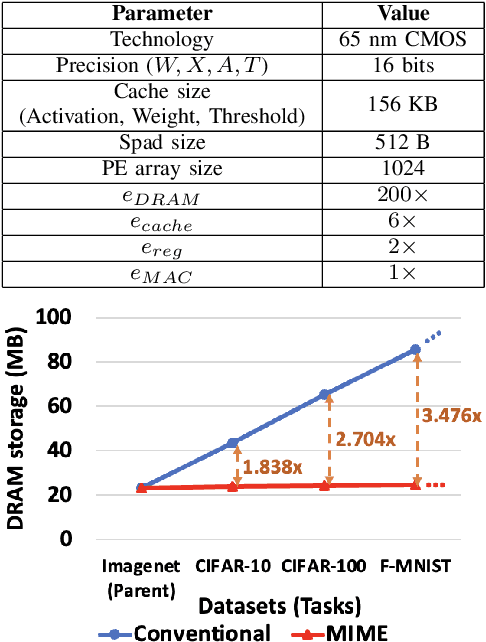
Recent years have seen a paradigm shift towards multi-task learning. This calls for memory and energy-efficient solutions for inference in a multi-task scenario. We propose an algorithm-hardware co-design approach called MIME. MIME reuses the weight parameters of a trained parent task and learns task-specific threshold parameters for inference on multiple child tasks. We find that MIME results in highly memory-efficient DRAM storage of neural-network parameters for multiple tasks compared to conventional multi-task inference. In addition, MIME results in input-dependent dynamic neuronal pruning, thereby enabling energy-efficient inference with higher throughput on a systolic-array hardware. Our experiments with benchmark datasets (child tasks)- CIFAR10, CIFAR100, and Fashion-MNIST, show that MIME achieves ~3.48x memory-efficiency and ~2.4-3.1x energy-savings compared to conventional multi-task inference in Pipelined task mode.
* Accepted in Design Automation Conference (DAC), 2022
Addressing Client Drift in Federated Continual Learning with Adaptive Optimization
Mar 24, 2022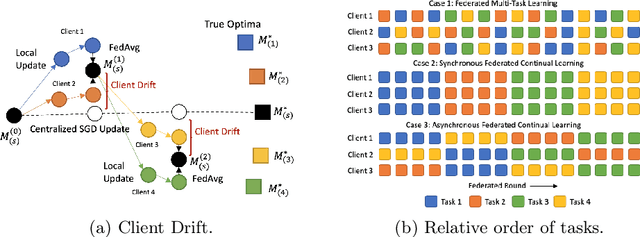
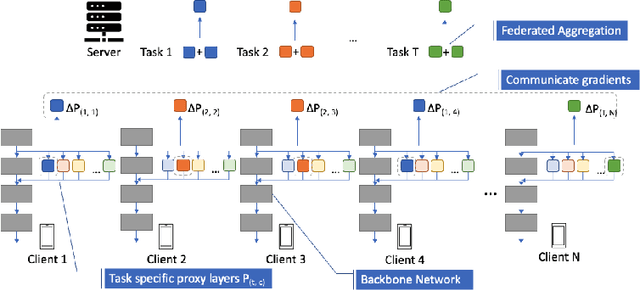
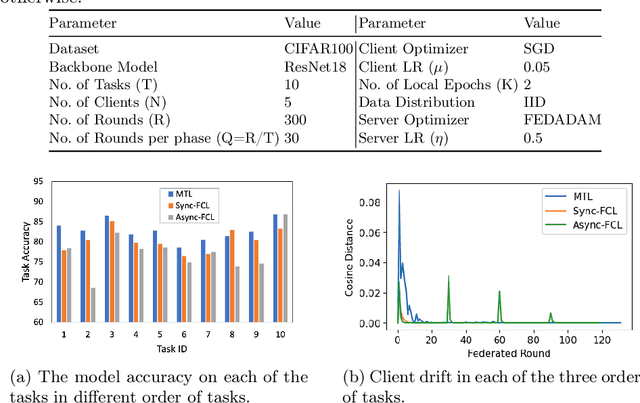
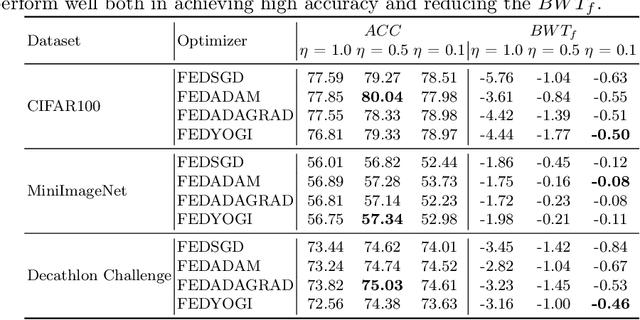
Federated learning has been extensively studied and is the prevalent method for privacy-preserving distributed learning in edge devices. Correspondingly, continual learning is an emerging field targeted towards learning multiple tasks sequentially. However, there is little attention towards additional challenges emerging when federated aggregation is performed in a continual learning system. We identify \textit{client drift} as one of the key weaknesses that arise when vanilla federated averaging is applied in such a system, especially since each client can independently have different order of tasks. We outline a framework for performing Federated Continual Learning (FCL) by using NetTailor as a candidate continual learning approach and show the extent of the problem of client drift. We show that adaptive federated optimization can reduce the adverse impact of client drift and showcase its effectiveness on CIFAR100, MiniImagenet, and Decathlon benchmarks. Further, we provide an empirical analysis highlighting the interplay between different hyperparameters such as client and server learning rates, the number of local training iterations, and communication rounds. Finally, we evaluate our framework on useful characteristics of federated learning systems such as scalability, robustness to the skewness in clients' data distribution, and stragglers.