 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Testing and Adapting REST APIs as LLM Tools
Apr 22, 2025Large Language Models (LLMs) are enabling autonomous agents to perform complex workflows using external tools or functions, often provided via REST APIs in enterprise systems. However, directly utilizing these APIs as tools poses challenges due to their complex input schemas, elaborate responses, and often ambiguous documentation. Current benchmarks for tool testing do not adequately address these complexities, leading to a critical gap in evaluating API readiness for agent-driven automation. In this work, we present a novel testing framework aimed at evaluating and enhancing the readiness of REST APIs to function as tools for LLM-based agents. Our framework transforms apis as tools, generates comprehensive test cases for the APIs, translates tests cases into natural language instructions suitable for agents, enriches tool definitions and evaluates the agent's ability t correctly invoke the API and process its inputs and responses. To provide actionable insights, we analyze the outcomes of 750 test cases, presenting a detailed taxonomy of errors, including input misinterpretation, output handling inconsistencies, and schema mismatches. Additionally, we classify these test cases to streamline debugging and refinement of tool integrations. This work offers a foundational step toward enabling enterprise APIs as tools, improving their usability in agent-based applications.
Goal-Oriented Next Best Activity Recommendation using Reinforcement Learning
May 06, 2022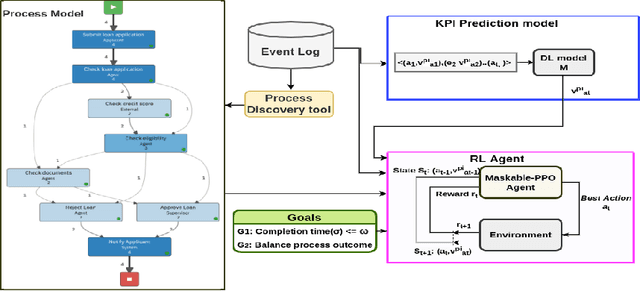
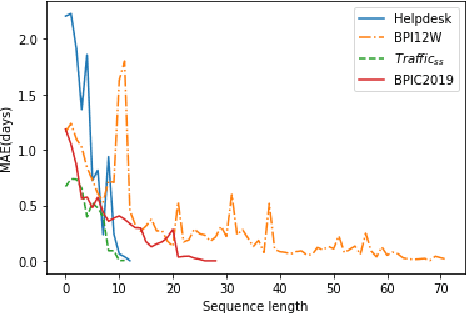
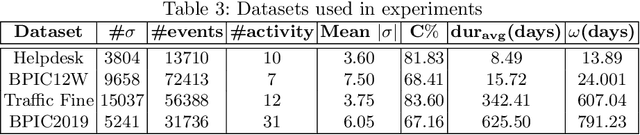
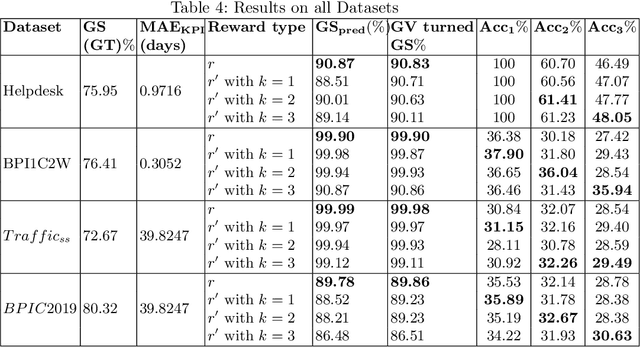
Recommending a sequence of activities for an ongoing case requires that the recommendations conform to the underlying business process and meet the performance goal of either completion time or process outcome. Existing work on next activity prediction can predict the future activity but cannot provide guarantees of the prediction being conformant or meeting the goal. Hence, we propose a goal-oriented next best activity recommendation. Our proposed framework uses a deep learning model to predict the next best activity and an estimated value of a goal given the activity. A reinforcement learning method explores the sequence of activities based on the estimates likely to meet one or more goals. We further address a real-world problem of multiple goals by introducing an additional reward function to balance the outcome of a recommended activity and satisfy the goal. We demonstrate the effectiveness of the proposed method on four real-world datasets with different characteristics. The results show that the recommendations from our proposed approach outperform in goal satisfaction and conformance compared to the existing state-of-the-art next best activity recommendation techniques.
Indian Regional Movie Dataset for Recommender Systems
Jan 07, 2018
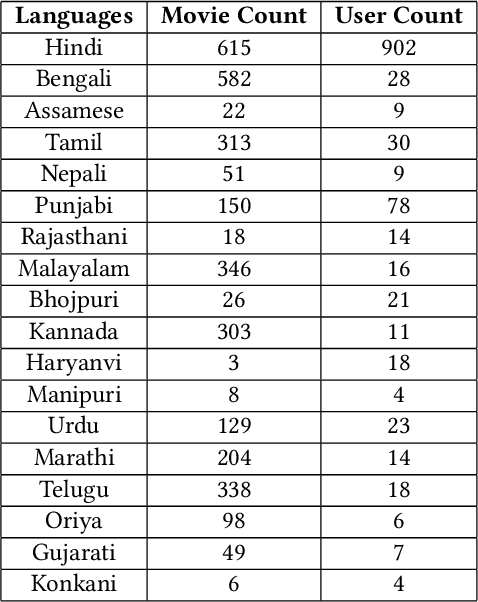
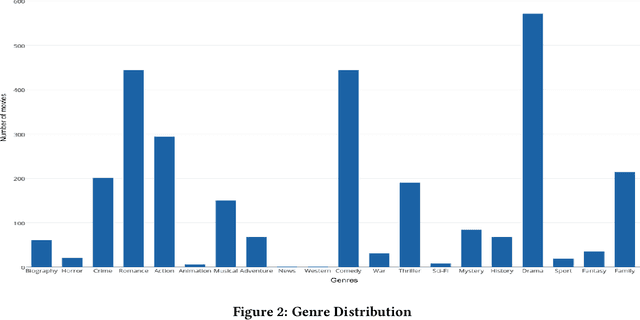
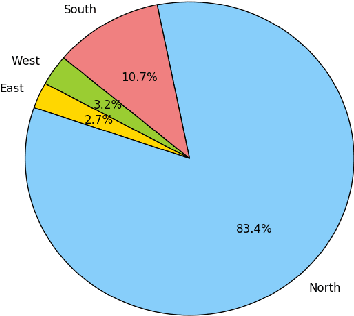
Indian regional movie dataset is the first database of regional Indian movies, users and their ratings. It consists of movies belonging to 18 different Indian regional languages and metadata of users with varying demographics. Through this dataset, the diversity of Indian regional cinema and its huge viewership is captured. We analyze the dataset that contains roughly 10K ratings of 919 users and 2,851 movies using some supervised and unsupervised collaborative filtering techniques like Probabilistic Matrix Factorization, Matrix Completion, Blind Compressed Sensing etc. The dataset consists of metadata information of users like age, occupation, home state and known languages. It also consists of metadata of movies like genre, language, release year and cast. India has a wide base of viewers which is evident by the large number of movies released every year and the huge box-office revenue. This dataset can be used for designing recommendation systems for Indian users and regional movies, which do not, yet, exist. The dataset can be downloaded from \href{https://goo.gl/EmTPv6}{https://goo.gl/EmTPv6}.