 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Language Prior for Infrared Small Target Detection
Jul 17, 2025IRSTD (InfraRed Small Target Detection) detects small targets in infrared blurry backgrounds and is essential for various applications. The detection task is challenging due to the small size of the targets and their sparse distribution in infrared small target datasets. Although existing IRSTD methods and datasets have led to significant advancements, they are limited by their reliance solely on the image modality. Recent advances in deep learning and large vision-language models have shown remarkable performance in various visual recognition tasks. In this work, we propose a novel multimodal IRSTD framework that incorporates language priors to guide small target detection. We leverage language-guided attention weights derived from the language prior to enhance the model's ability for IRSTD, presenting a novel approach that combines textual information with image data to improve IRSTD capabilities. Utilizing the state-of-the-art GPT-4 vision model, we generate text descriptions that provide the locations of small targets in infrared images, employing careful prompt engineering to ensure improved accuracy. Due to the absence of multimodal IR datasets, existing IRSTD methods rely solely on image data. To address this shortcoming, we have curated a multimodal infrared dataset that includes both image and text modalities for small target detection, expanding upon the popular IRSTD-1k and NUDT-SIRST datasets. We validate the effectiveness of our approach through extensive experiments and comprehensive ablation studies. The results demonstrate significant improvements over the state-of-the-art method, with relative percentage differences of 9.74%, 13.02%, 1.25%, and 67.87% in IoU, nIoU, Pd, and Fa on the NUAA-SIRST subset, and 4.41%, 2.04%, 2.01%, and 113.43% on the IRSTD-1k subset of the LangIR dataset, respectively.
Hyperspectral Image Land Cover Captioning Dataset for Vision Language Models
May 18, 2025We introduce HyperCap, the first large-scale hyperspectral captioning dataset designed to enhance model performance and effectiveness in remote sensing applications. Unlike traditional hyperspectral imaging (HSI) datasets that focus solely on classification tasks, HyperCap integrates spectral data with pixel-wise textual annotations, enabling deeper semantic understanding of hyperspectral imagery. This dataset enhances model performance in tasks like classification and feature extraction, providing a valuable resource for advanced remote sensing applications. HyperCap is constructed from four benchmark datasets and annotated through a hybrid approach combining automated and manual methods to ensure accuracy and consistency. Empirical evaluations using state-of-the-art encoders and diverse fusion techniques demonstrate significant improvements in classification performance. These results underscore the potential of vision-language learning in HSI and position HyperCap as a foundational dataset for future research in the field.
Secure Generalization through Stochastic Bidirectional Parameter Updates Using Dual-Gradient Mechanism
Apr 03, 2025



Federated learning (FL) has gained increasing attention due to privacy-preserving collaborative training on decentralized clients, mitigating the need to upload sensitive data to a central server directly. Nonetheless, recent research has underscored the risk of exposing private data to adversaries, even within FL frameworks. In general, existing methods sacrifice performance while ensuring resistance to privacy leakage in FL. We overcome these issues and generate diverse models at a global server through the proposed stochastic bidirectional parameter update mechanism. Using diverse models, we improved the generalization and feature representation in the FL setup, which also helped to improve the robustness of the model against privacy leakage without hurting the model's utility. We use global models from past FL rounds to follow systematic perturbation in parameter space at the server to ensure model generalization and resistance against privacy attacks. We generate diverse models (in close neighborhoods) for each client by using systematic perturbations in model parameters at a fine-grained level (i.e., altering each convolutional filter across the layers of the model) to improve the generalization and security perspective. We evaluated our proposed approach on four benchmark datasets to validate its superiority. We surpassed the state-of-the-art methods in terms of model utility and robustness towards privacy leakage. We have proven the effectiveness of our method by evaluating performance using several quantitative and qualitative results.
Pedestrian Trajectory Prediction with Missing Data: Datasets, Imputation, and Benchmarking
Oct 31, 2024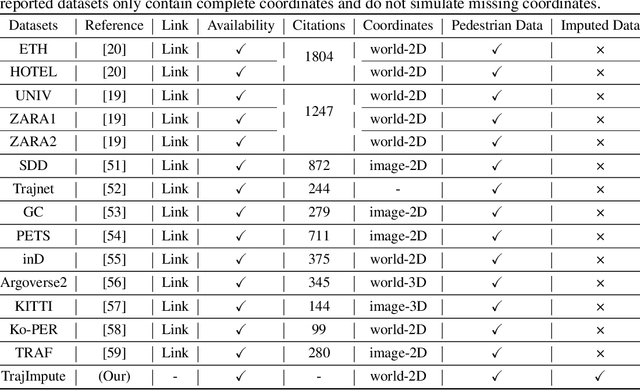
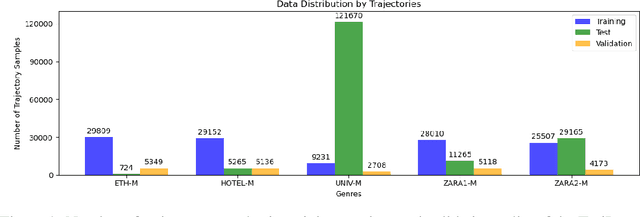
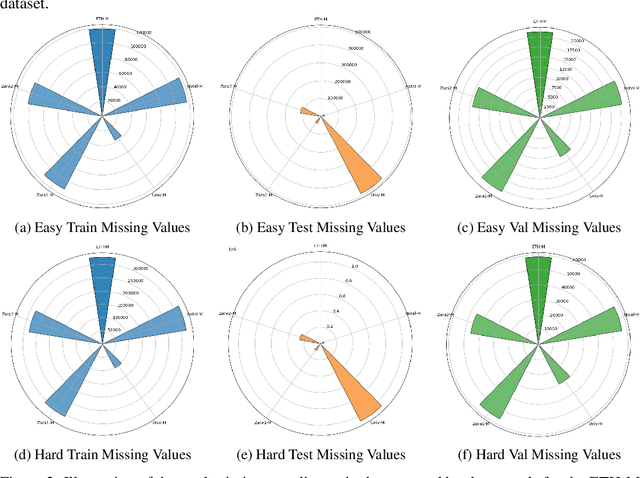
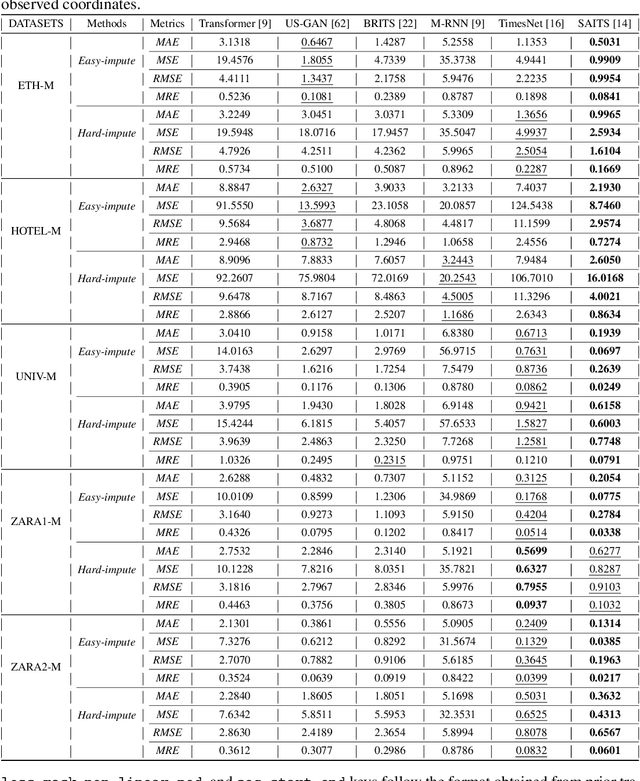
Pedestrian trajectory prediction is crucial for several applications such as robotics and self-driving vehicles. Significant progress has been made in the past decade thanks to the availability of pedestrian trajectory datasets, which enable trajectory prediction methods to learn from pedestrians' past movements and predict future trajectories. However, these datasets and methods typically assume that the observed trajectory sequence is complete, ignoring real-world issues such as sensor failure, occlusion, and limited fields of view that can result in missing values in observed trajectories. To address this challenge, we present TrajImpute, a pedestrian trajectory prediction dataset that simulates missing coordinates in the observed trajectory, enhancing real-world applicability. TrajImpute maintains a uniform distribution of missing data within the observed trajectories. In this work, we comprehensively examine several imputation methods to reconstruct the missing coordinates and benchmark them for imputing pedestrian trajectories. Furthermore, we provide a thorough analysis of recent trajectory prediction methods and evaluate the performance of these models on the imputed trajectories. Our experimental evaluation of the imputation and trajectory prediction methods offers several valuable insights. Our dataset provides a foundational resource for future research on imputation-aware pedestrian trajectory prediction, potentially accelerating the deployment of these methods in real-world applications. Publicly accessible links to the datasets and code files are available at https://github.com/Pranav-chib/TrajImpute.
Leveraging Task-Specific Knowledge from LLM for Semi-Supervised 3D Medical Image Segmentation
Jul 06, 2024



Traditional supervised 3D medical image segmentation models need voxel-level annotations, which require huge human effort, time, and cost. Semi-supervised learning (SSL) addresses this limitation of supervised learning by facilitating learning with a limited annotated and larger amount of unannotated training samples. However, state-of-the-art SSL models still struggle to fully exploit the potential of learning from unannotated samples. To facilitate effective learning from unannotated data, we introduce LLM-SegNet, which exploits a large language model (LLM) to integrate task-specific knowledge into our co-training framework. This knowledge aids the model in comprehensively understanding the features of the region of interest (ROI), ultimately leading to more efficient segmentation. Additionally, to further reduce erroneous segmentation, we propose a Unified Segmentation loss function. This loss function reduces erroneous segmentation by not only prioritizing regions where the model is confident in predicting between foreground or background pixels but also effectively addressing areas where the model lacks high confidence in predictions. Experiments on publicly available Left Atrium, Pancreas-CT, and Brats-19 datasets demonstrate the superior performance of LLM-SegNet compared to the state-of-the-art. Furthermore, we conducted several ablation studies to demonstrate the effectiveness of various modules and loss functions leveraged by LLM-SegNet.
MWIRSTD: A MWIR Small Target Detection Dataset
Jun 12, 2024



This paper presents a novel mid-wave infrared (MWIR) small target detection dataset (MWIRSTD) comprising 14 video sequences containing approximately 1053 images with annotated targets of three distinct classes of small objects. Captured using cooled MWIR imagers, the dataset offers a unique opportunity for researchers to develop and evaluate state-of-the-art methods for small object detection in realistic MWIR scenes. Unlike existing datasets, which primarily consist of uncooled thermal images or synthetic data with targets superimposed onto the background or vice versa, MWIRSTD provides authentic MWIR data with diverse targets and environments. Extensive experiments on various traditional methods and deep learning-based techniques for small target detection are performed on the proposed dataset, providing valuable insights into their efficacy. The dataset and code are available at https://github.com/avinres/MWIRSTD.
CCF: Cross Correcting Framework for Pedestrian Trajectory Prediction
Jun 02, 2024



Accurately predicting future pedestrian trajectories is crucial across various domains. Due to the uncertainty in future pedestrian trajectories, it is important to learn complex spatio-temporal representations in multi-agent scenarios. To address this, we propose a novel Cross-Correction Framework (CCF) to learn spatio-temporal representations of pedestrian trajectories better. Our framework consists of two trajectory prediction models, known as subnets, which share the same architecture and are trained with both cross-correction loss and trajectory prediction loss. Cross-correction leverages the learning from both subnets and enables them to refine their underlying representations of trajectories through a mutual correction mechanism. Specifically, we use the cross-correction loss to learn how to correct each other through an inter-subnet interaction. To induce diverse learning among the subnets, we use the transformed observed trajectories produced by a neural network as input to one subnet and the original observed trajectories as input to the other subnet. We utilize transformer-based encoder-decoder architecture for each subnet to capture motion and social interaction among pedestrians. The encoder of the transformer captures motion patterns in trajectories, while the decoder focuses on pedestrian interactions with neighbors. Each subnet performs the primary task of predicting future trajectories (a regression task) along with the secondary task of classifying the predicted trajectories (a classification task). Extensive experiments on real-world benchmark datasets such as ETH-UCY and SDD demonstrate the efficacy of our proposed framework, CCF, in precisely predicting pedestrian future trajectories. We also conducted several ablation experiments to demonstrate the effectiveness of various modules and loss functions used in our approach.
Biasing & Debiasing based Approach Towards Fair Knowledge Transfer for Equitable Skin Analysis
May 16, 2024



Deep learning models, particularly Convolutional Neural Networks (CNNs), have demonstrated exceptional performance in diagnosing skin diseases, often outperforming dermatologists. However, they have also unveiled biases linked to specific demographic traits, notably concerning diverse skin tones or gender, prompting concerns regarding fairness and limiting their widespread deployment. Researchers are actively working to ensure fairness in AI-based solutions, but existing methods incur an accuracy loss when striving for fairness. To solve this issue, we propose a `two-biased teachers' (i.e., biased on different sensitive attributes) based approach to transfer fair knowledge into the student network. Our approach mitigates biases present in the student network without harming its predictive accuracy. In fact, in most cases, our approach improves the accuracy of the baseline model. To achieve this goal, we developed a weighted loss function comprising biasing and debiasing loss terms. We surpassed available state-of-the-art approaches to attain fairness and also improved the accuracy at the same time. The proposed approach has been evaluated and validated on two dermatology datasets using standard accuracy and fairness evaluation measures. We will make source code publicly available to foster reproducibility and future research.
Leveraging Fixed and Dynamic Pseudo-labels for Semi-supervised Medical Image Segmentation
May 12, 2024Semi-supervised medical image segmentation has gained growing interest due to its ability to utilize unannotated data. The current state-of-the-art methods mostly rely on pseudo-labeling within a co-training framework. These methods depend on a single pseudo-label for training, but these labels are not as accurate as the ground truth of labeled data. Relying solely on one pseudo-label often results in suboptimal results. To this end, we propose a novel approach where multiple pseudo-labels for the same unannotated image are used to learn from the unlabeled data: the conventional fixed pseudo-label and the newly introduced dynamic pseudo-label. By incorporating multiple pseudo-labels for the same unannotated image into the co-training framework, our approach provides a more robust training approach that improves model performance and generalization capabilities. We validate our novel approach on three semi-supervised medical benchmark segmentation datasets, the Left Atrium dataset, the Pancreas-CT dataset, and the Brats-2019 dataset. Our approach significantly outperforms state-of-the-art methods over multiple medical benchmark segmentation datasets with different labeled data ratios. We also present several ablation experiments to demonstrate the effectiveness of various components used in our approach.
Reliable or Deceptive? Investigating Gated Features for Smooth Visual Explanations in CNNs
Apr 30, 2024Deep learning models have achieved remarkable success across diverse domains. However, the intricate nature of these models often impedes a clear understanding of their decision-making processes. This is where Explainable AI (XAI) becomes indispensable, offering intuitive explanations for model decisions. In this work, we propose a simple yet highly effective approach, ScoreCAM++, which introduces modifications to enhance the promising ScoreCAM method for visual explainability. Our proposed approach involves altering the normalization function within the activation layer utilized in ScoreCAM, resulting in significantly improved results compared to previous efforts. Additionally, we apply an activation function to the upsampled activation layers to enhance interpretability. This improvement is achieved by selectively gating lower-priority values within the activation layer. Through extensive experiments and qualitative comparisons, we demonstrate that ScoreCAM++ consistently achieves notably superior performance and fairness in interpreting the decision-making process compared to both ScoreCAM and previous methods.