 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORE: Comprehensive Ontological Relation Evaluation for Large Language Models
Feb 06, 2026Large Language Models (LLMs) perform well on many reasoning benchmarks, yet existing evaluations rarely assess their ability to distinguish between meaningful semantic relations and genuine unrelatedness. We introduce CORE (Comprehensive Ontological Relation Evaluation), a dataset of 225K multiple-choice questions spanning 74 disciplines, together with a general-domain open-source benchmark of 203 rigorously validated questions (Cohen's Kappa = 1.0) covering 24 semantic relation types with equal representation of unrelated pairs. A human baseline from 1,000+ participants achieves 92.6% accuracy (95.1% on unrelated pairs). In contrast, 29 state-of-the-art LLMs achieve 48.25-70.9% overall accuracy, with near-ceiling performance on related pairs (86.5-100%) but severe degradation on unrelated pairs (0-41.35%), despite assigning similar confidence (92-94%). Expected Calibration Error increases 2-4x on unrelated pairs, and a mean semantic collapse rate of 37.6% indicates systematic generation of spurious relations. On the CORE 225K MCQs dataset, accuracy further drops to approximately 2%, highlighting substantial challenges in domain-specific semantic reasoning. We identify unrelatedness reasoning as a critical, under-evaluated frontier for LLM evaluation and safety.
Development of a Dataset and a Deep Learning Baseline Named Entity Recognizer for Three Low Resource Languages: Bhojpuri, Maithili and Magahi
Sep 14, 2020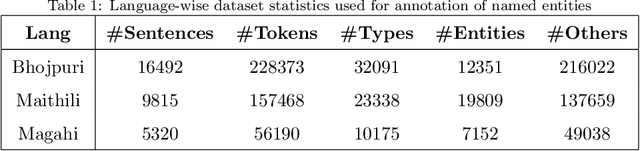
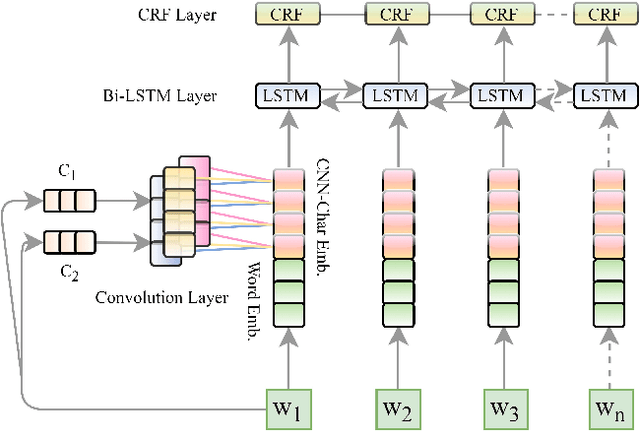
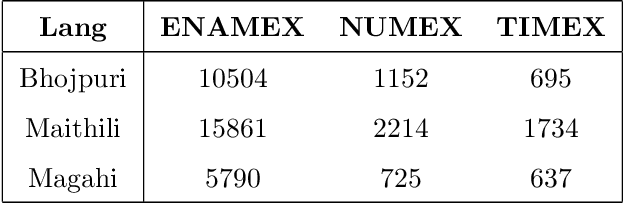
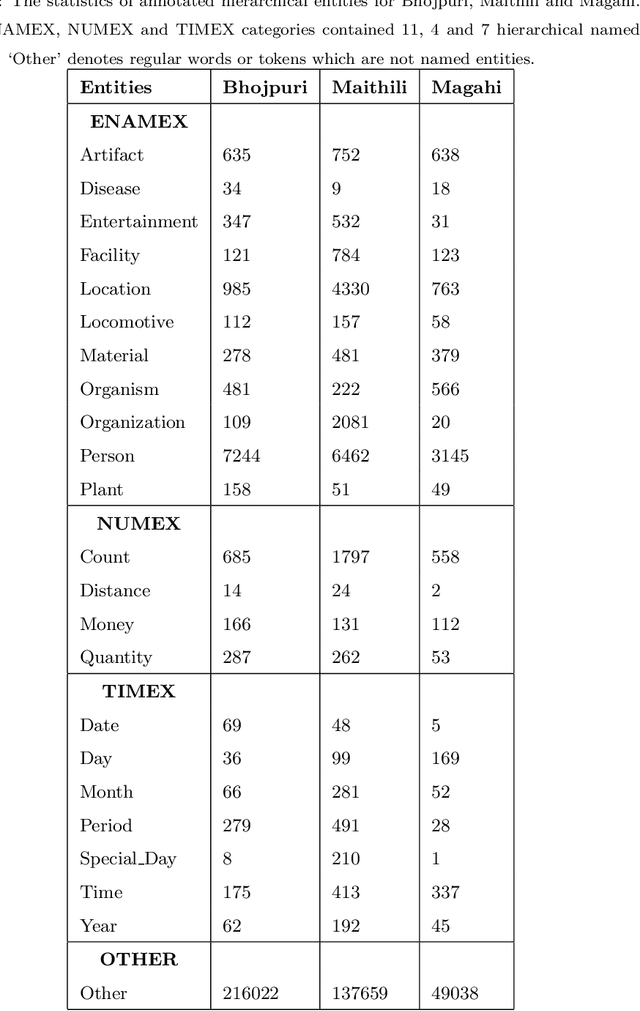
In Natural Language Processing (NLP) pipelines, Named Entity Recognition (NER) is one of the preliminary problems, which marks proper nouns and other named entities such as Location, Person, Organization, Disease etc. Such entities, without a NER module, adversely affect the performance of a machine translation system. NER helps in overcoming this problem by recognising and handling such entities separately, although it can be useful in Information Extraction systems also. Bhojpuri, Maithili and Magahi are low resource languages, usually known as Purvanchal languages. This paper focuses on the development of a NER benchmark dataset for the Machine Translation systems developed to translate from these languages to Hindi by annotating parts of their available corpora. Bhojpuri, Maithili and Magahi corpora of sizes 228373, 157468 and 56190 tokens, respectively, were annotated using 22 entity labels. The annotation considers coarse-grained annotation labels followed by the tagset used in one of the Hindi NER datasets. We also report a Deep Learning based baseline that uses an LSTM-CNNs-CRF model. The lower baseline F1-scores from the NER tool obtained by using Conditional Random Fields models are 96.73 for Bhojpuri, 93.33 for Maithili and 95.04 for Magahi. The Deep Learning-based technique (LSTM-CNNs-CRF) achieved 96.25 for Bhojpuri, 93.33 for Maithili and 95.44 for Magahi.