 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Geometric Canary: Predicting Steerability and Detecting Drift via Representational Stability
Apr 20, 2026Reliable deployment of language models requires two capabilities that appear distinct but share a common geometric foundation: predicting whether a model will accept targeted behavioral control, and detecting when its internal structure degrades. We show that geometric stability, the consistency of a representation's pairwise distance structure, addresses both. Supervised Shesha variants that measure task-aligned geometric stability predict linear steerability with near-perfect accuracy ($ρ= 0.89$-$0.97$) across 35-69 embedding models and three NLP tasks, capturing unique variance beyond class separability (partial $ρ= 0.62$-$0.76$). A critical dissociation emerges: unsupervised stability fails entirely for steering on real-world tasks ($ρ\approx 0.10$), revealing that task alignment is essential for controllability prediction. However, unsupervised stability excels at drift detection, measuring nearly $2\times$ greater geometric change than CKA during post-training alignment (up to $5.23\times$ in Llama) while providing earlier warning in 73\% of models and maintaining a $6\times$ lower false alarm rate than Procrustes. Together, supervised and unsupervised stability form complementary diagnostics for the LLM deployment lifecycle: one for pre-deployment controllability assessment, the other for post-deployment monitoring.
The Geometric Alignment Tax: Tokenization vs. Continuous Geometry in Scientific Foundation Models
Apr 05, 2026Foundation models for biology and physics optimize predictive accuracy, but their internal representations systematically fail to preserve the continuous geometry of the systems they model. We identify the root cause: the Geometric Alignment Tax, an intrinsic cost of forcing continuous manifolds through discrete categorical bottlenecks. Controlled ablations on synthetic dynamical systems demonstrate that replacing cross-entropy with a continuous head on an identical encoder reduces geometric distortion by up to 8.5x, while learned codebooks exhibit a non-monotonic double bind where finer quantization worsens geometry despite improving reconstruction. Under continuous objectives, three architectures differ by 1.3x; under discrete tokenization, they diverge by 3,000x. Evaluating 14 biological foundation models with rate-distortion theory and MINE, we identify three failure regimes: Local-Global Decoupling, Representational Compression, and Geometric Vacuity. A controlled experiment confirms that Evo 2's reverse-complement robustness on real DNA reflects conserved sequence composition, not learned symmetry. No model achieves simultaneously low distortion, high mutual information, and global coherence.
Geometric Stability: The Missing Axis of Representations
Jan 14, 2026Analysis of learned representations has a blind spot: it focuses on $similarity$, measuring how closely embeddings align with external references, but similarity reveals only what is represented, not whether that structure is robust. We introduce $geometric$ $stability$, a distinct dimension that quantifies how reliably representational geometry holds under perturbation, and present $Shesha$, a framework for measuring it. Across 2,463 configurations in seven domains, we show that stability and similarity are empirically uncorrelated ($ρ\approx 0.01$) and mechanistically distinct: similarity metrics collapse after removing the top principal components, while stability retains sensitivity to fine-grained manifold structure. This distinction yields actionable insights: for safety monitoring, stability acts as a functional geometric canary, detecting structural drift nearly 2$\times$ more sensitively than CKA while filtering out the non-functional noise that triggers false alarms in rigid distance metrics; for controllability, supervised stability predicts linear steerability ($ρ= 0.89$-$0.96$); for model selection, stability dissociates from transferability, revealing a geometric tax that transfer optimization incurs. Beyond machine learning, stability predicts CRISPR perturbation coherence and neural-behavioral coupling. By quantifying $how$ $reliably$ systems maintain structure, geometric stability provides a necessary complement to similarity for auditing representations across biological and computational systems.
Controversial stimuli: pitting neural networks against each other as models of human recognition
Nov 21, 2019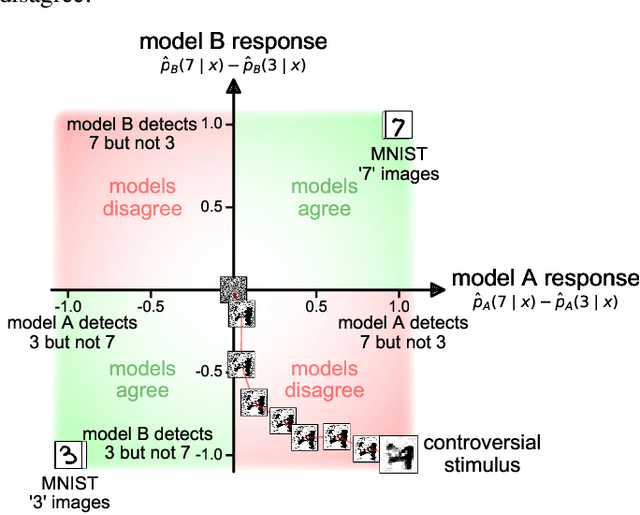
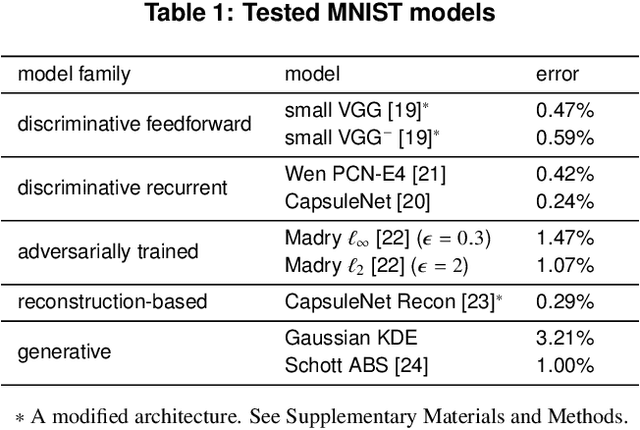
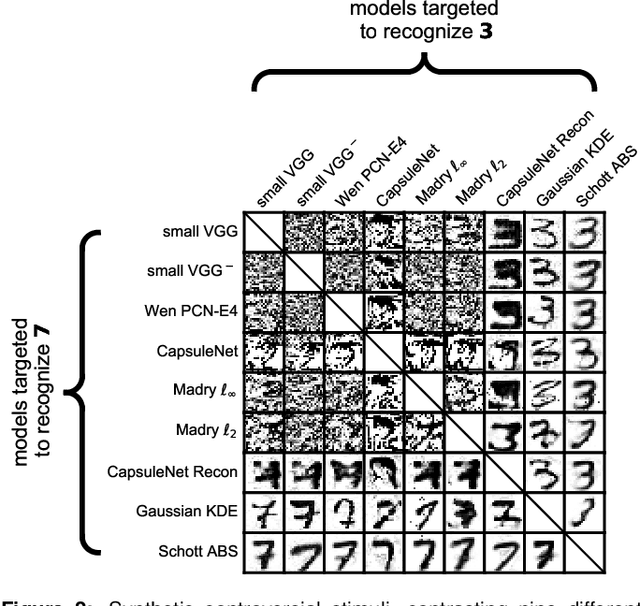
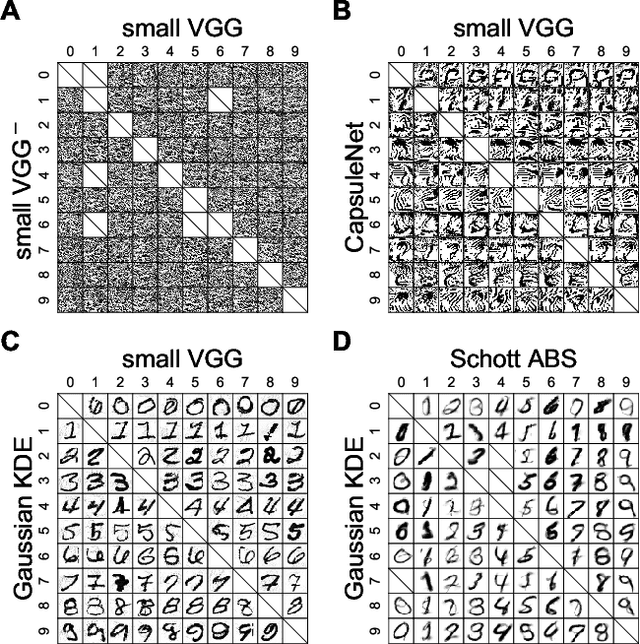
Distinct scientific theories can make similar predictions. To adjudicate between theories, we must design experiments for which the theories make distinct predictions. Here we consider the problem of comparing deep neural networks as models of human visual recognition. To efficiently determine which models better explain human responses, we synthesize controversial stimuli: images for which different models produce distinct responses. We tested nine different models, which employed different architectures and recognition algorithms, including discriminative and generative models, all trained to recognize handwritten digits (from the MNIST set of digit images). We synthesized controversial stimuli to maximize the disagreement among the models. Human subjects viewed hundreds of these stimuli and judged the probability of presence of each digit in each image. We quantified how accurately each model predicted the human judgements. We found that the generative models (which learn the distribution of images for each class) better predicted the human judgments than the discriminative models (which learn to directly map from images to labels). The best performing model was the generative Analysis-by-Synthesis model (based on variational autoencoders). However, a simpler generative model (based on Gaussian-kernel-density estimation) also performed better than each of the discriminative models. None of the candidate models fully explained the human responses. We discuss the advantages and limitations of controversial stimuli as an experimental paradigm and how they generalize and improve on adversarial examples as probes of discrepancies between models and human perception.