 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimized Disaster Recovery for Distributed Storage Systems: Lightweight Metadata Architectures to Overcome Cryptographic Hashing Bottleneck
Feb 23, 2026Distributed storage architectures are foundational to modern cloud-native infrastructure, yet a critical operational bottleneck persists within disaster recovery (DR) workflows: the dependence on content-based cryptographic hashing for data identification and synchronization. While hash-based deduplication is effective for storage efficiency in steady-state operation, it becomes a systemic liability during failover and failback events when hash indexes are stale, incomplete, or must be rebuilt following a crash. This paper precisely characterizes the operational conditions under which full or partial re-hashing becomes unavoidable. The paper also analyzes the downstream impact of cryptographic re-hashing on Recovery Time Objective (RTO) compliance, and proposes a generalized architectural shift toward deterministic, metadata-driven identification. The proposed framework assigns globally unique composite identifiers to data blocks at ingestion time-independent of content analysis enabling instantaneous delta computation during DR without any cryptographic overhead.
The Dark Side of AI Transformers: Sentiment Polarization & the Loss of Business Neutrality by NLP Transformers
Jan 21, 2026The use of Transfer Learning & Transformers has steadily improved accuracy and has significantly contributed in solving complex computation problems. However, this transformer led accuracy improvement in Applied AI Analytics specifically in sentiment analytics comes with the dark side. It is observed during experiments that a lot of these improvements in transformer led accuracy of one class of sentiment has been at the cost of polarization of another class of sentiment and the failing of neutrality. This lack of neutrality poses an acute problem in the Applied NLP space, which relies heavily on the computational outputs of sentiment analytics for reliable industry ready tasks.
New Methods & Metrics for LFQA tasks
Dec 26, 2021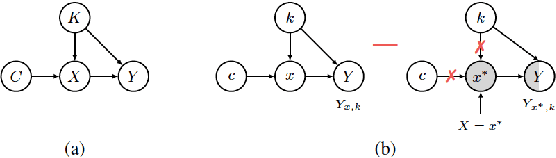
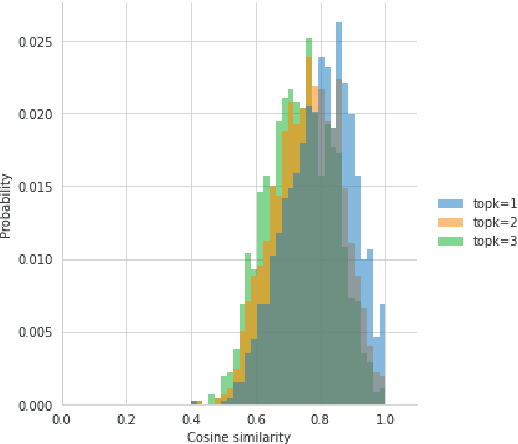

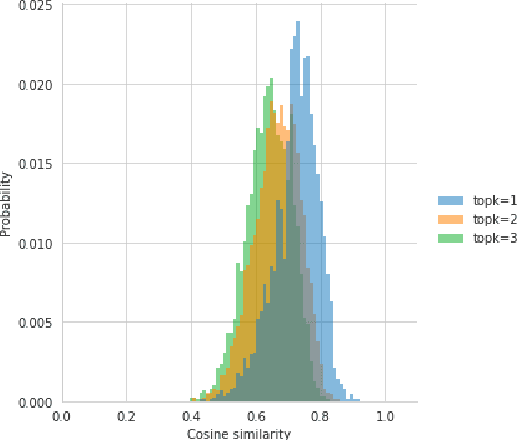
Long-form question answering (LFQA) tasks require retrieving the documents pertinent to a query, using them to form a paragraph-length answer. Despite considerable progress in LFQA modeling, fundamental issues impede its progress: i) train/validation/test dataset overlap, ii) absence of automatic metrics and iii) generated answers not being "grounded" in retrieved documents. This work addresses every one these critical bottlenecks, contributing natural language inference/generation (NLI/NLG) methods and metrics that make significant strides to their alleviation.