 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the relationship between regularity and learnability in recursive numeral systems using Reinforcement Learning
Feb 25, 2026Human recursive numeral systems (i.e., counting systems such as English base-10 numerals), like many other grammatical systems, are highly regular. Following prior work that relates cross-linguistic tendencies to biases in learning, we ask whether regular systems are common because regularity facilitates learning. Adopting methods from the Reinforcement Learning literature, we confirm that highly regular human(-like) systems are easier to learn than unattested but possible irregular systems. This asymmetry emerges under the natural assumption that recursive numeral systems are designed for generalisation from limited data to represent all integers exactly. We also find that the influence of regularity on learnability is absent for unnatural, highly irregular systems, whose learnability is influenced instead by signal length, suggesting that different pressures may influence learnability differently in different parts of the space of possible numeral systems. Our results contribute to the body of work linking learnability to cross-linguistic prevalence.
Recursive numeral systems are highly regular and easy to process
Oct 30, 2025Previous work has argued that recursive numeral systems optimise the trade-off between lexicon size and average morphosyntatic complexity (Deni\'c and Szymanik, 2024). However, showing that only natural-language-like systems optimise this tradeoff has proven elusive, and the existing solution has relied on ad-hoc constraints to rule out unnatural systems (Yang and Regier, 2025). Here, we argue that this issue arises because the proposed trade-off has neglected regularity, a crucial aspect of complexity central to human grammars in general. Drawing on the Minimum Description Length (MDL) approach, we propose that recursive numeral systems are better viewed as efficient with regard to their regularity and processing complexity. We show that our MDL-based measures of regularity and processing complexity better capture the key differences between attested, natural systems and unattested but possible ones, including "optimal" recursive numeral systems from previous work, and that the ad-hoc constraints from previous literature naturally follow from regularity. Our approach highlights the need to incorporate regularity across sets of forms in studies that attempt to measure and explain optimality in language.
AttaCut: A Fast and Accurate Neural Thai Word Segmenter
Nov 16, 2019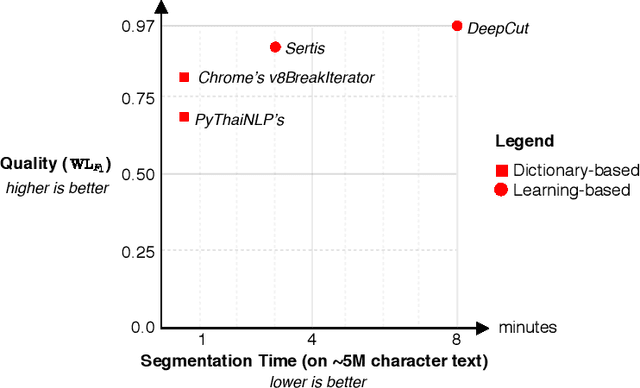

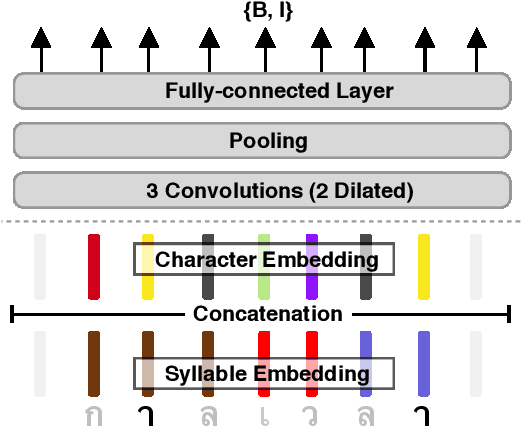

Word segmentation is a fundamental pre-processing step for Thai Natural Language Processing. The current off-the-shelf solutions are not benchmarked consistently, so it is difficult to compare their trade-offs. We conducted a speed and accuracy comparison of the popular systems on three different domains and found that the state-of-the-art deep learning system is slow and moreover does not use sub-word structures to guide the model. Here, we propose a fast and accurate neural Thai Word Segmenter that uses dilated CNN filters to capture the environment of each character and uses syllable embeddings as features. Our system runs at least 5.6x faster and outperforms the previous state-of-the-art system on some domains. In addition, we develop the first ML-based Thai orthographical syllable segmenter, which yields syllable embeddings to be used as features by the word segmenter.