 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair for a few: Improving Fairness in Doubly Imbalanced Datasets
Jun 17, 2025Fairness has been identified as an important aspect of Machine Learning and Artificial Intelligence solutions for decision making. Recent literature offers a variety of approaches for debiasing, however many of them fall short when the data collection is imbalanced. In this paper, we focus on a particular case, fairness in doubly imbalanced datasets, such that the data collection is imbalanced both for the label and the groups in the sensitive attribute. Firstly, we present an exploratory analysis to illustrate limitations in debiasing on a doubly imbalanced dataset. Then, a multi-criteria based solution is proposed for finding the most suitable sampling and distribution for label and sensitive attribute, in terms of fairness and classification accuracy
Make Satire Boring Again: Reducing Stylistic Bias of Satirical Corpus by Utilizing Generative LLMs
Dec 12, 2024Satire detection is essential for accurately extracting opinions from textual data and combating misinformation online. However, the lack of diverse corpora for satire leads to the problem of stylistic bias which impacts the models' detection performances. This study proposes a debiasing approach for satire detection, focusing on reducing biases in training data by utilizing generative large language models. The approach is evaluated in both cross-domain (irony detection) and cross-lingual (English) settings. Results show that the debiasing method enhances the robustness and generalizability of the models for satire and irony detection tasks in Turkish and English. However, its impact on causal language models, such as Llama-3.1, is limited. Additionally, this work curates and presents the Turkish Satirical News Dataset with detailed human annotations, with case studies on classification, debiasing, and explainability.
Multimodal Fact-Checking with Vision Language Models: A Probing Classifier based Solution with Embedding Strategies
Dec 06, 2024



This study evaluates the effectiveness of Vision Language Models (VLMs) in representing and utilizing multimodal content for fact-checking. To be more specific, we investigate whether incorporating multimodal content improves performance compared to text-only models and how well VLMs utilize text and image information to enhance misinformation detection. Furthermore we propose a probing classifier based solution using VLMs. Our approach extracts embeddings from the last hidden layer of selected VLMs and inputs them into a neural probing classifier for multi-class veracity classification. Through a series of experiments on two fact-checking datasets, we demonstrate that while multimodality can enhance performance, fusing separate embeddings from text and image encoders yielded superior results compared to using VLM embeddings. Furthermore, the proposed neural classifier significantly outperformed KNN and SVM baselines in leveraging extracted embeddings, highlighting its effectiveness for multimodal fact-checking.
Cross-Lingual Learning vs. Low-Resource Fine-Tuning: A Case Study with Fact-Checking in Turkish
Mar 01, 2024The rapid spread of misinformation through social media platforms has raised concerns regarding its impact on public opinion. While misinformation is prevalent in other languages, the majority of research in this field has concentrated on the English language. Hence, there is a scarcity of datasets for other languages, including Turkish. To address this concern, we have introduced the FCTR dataset, consisting of 3238 real-world claims. This dataset spans multiple domains and incorporates evidence collected from three Turkish fact-checking organizations. Additionally, we aim to assess the effectiveness of cross-lingual transfer learning for low-resource languages, with a particular focus on Turkish. We demonstrate in-context learning (zero-shot and few-shot) performance of large language models in this context. The experimental results indicate that the dataset has the potential to advance research in the Turkish language.
Explaining Veracity Predictions with Evidence Summarization: A Multi-Task Model Approach
Feb 09, 2024



The rapid dissemination of misinformation through social media increased the importance of automated fact-checking. Furthermore, studies on what deep neural models pay attention to when making predictions have increased in recent years. While significant progress has been made in this field, it has not yet reached a level of reasoning comparable to human reasoning. To address these gaps, we propose a multi-task explainable neural model for misinformation detection. Specifically, this work formulates an explanation generation process of the model's veracity prediction as a text summarization problem. Additionally, the performance of the proposed model is discussed on publicly available datasets and the findings are evaluated with related studies.
Investigating the Effect of Segmentation Methods on Neural Model based Sentiment Analysis on Informal Short Texts in Turkish
Feb 18, 2019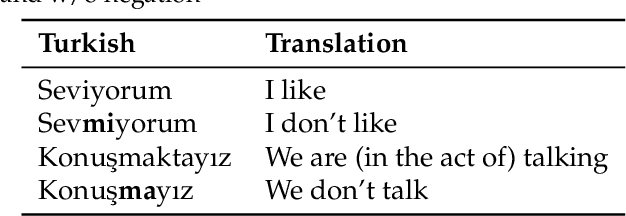
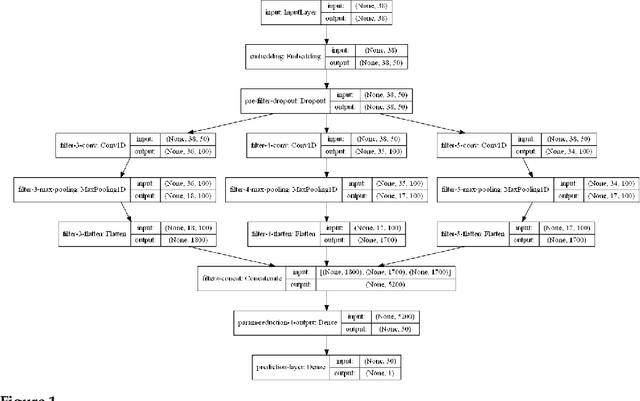

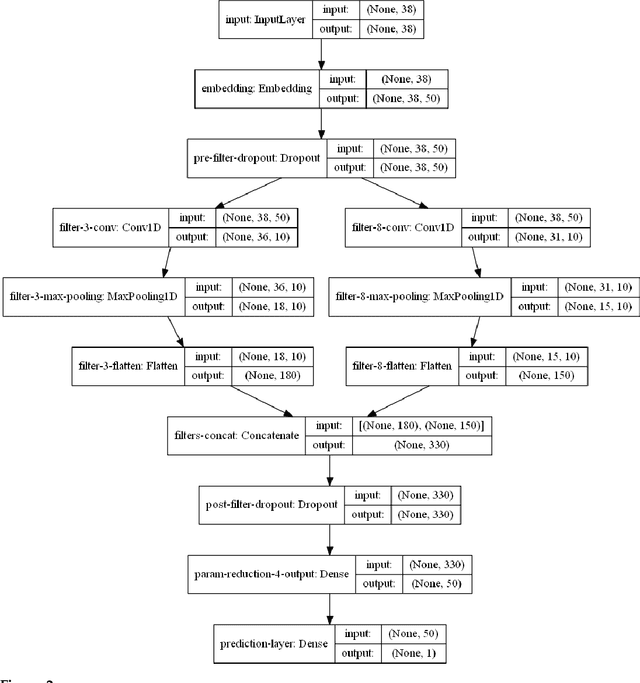
This work investigates segmentation approaches for sentiment analysis on informal short texts in Turkish. The two building blocks of the proposed work are segmentation and deep neural network model. Segmentation focuses on preprocessing of text with different methods. These methods are grouped in four: morphological, sub-word, tokenization, and hybrid approaches. We analyzed several variants for each of these four methods. The second stage focuses on evaluation of the neural model for sentiment analysis. The performance of each segmentation method is evaluated under Convolutional Neural Network (CNN) and Recurrent Neural Network (RNN) model proposed in the literature for sentiment classification.
Getting Started with Neural Models for Semantic Matching in Web Search
Nov 08, 2016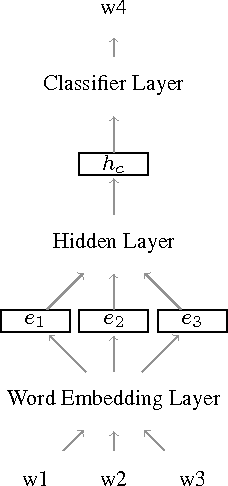

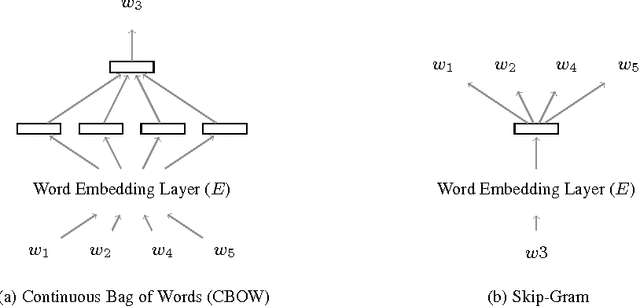
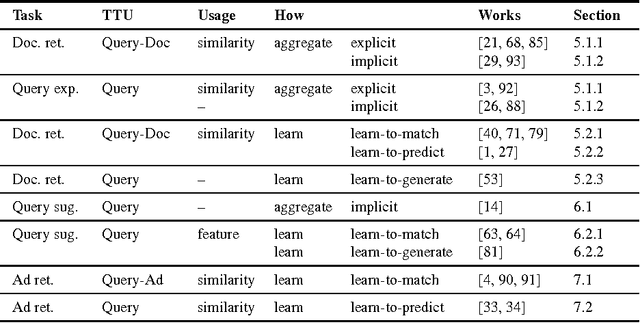
The vocabulary mismatch problem is a long-standing problem in information retrieval. Semantic matching holds the promise of solving the problem. Recent advances in language technology have given rise to unsupervised neural models for learning representations of words as well as bigger textual units. Such representations enable powerful semantic matching methods. This survey is meant as an introduction to the use of neural models for semantic matching. To remain focused we limit ourselves to web search. We detail the required background and terminology, a taxonomy grouping the rapidly growing body of work in the area, and then survey work on neural models for semantic matching in the context of three tasks: query suggestion, ad retrieval, and document retrieval. We include a section on resources and best practices that we believe will help readers who are new to the area. We conclude with an assessment of the state-of-the-art and suggestions for future work.