 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocation, Location: Enhancing the Evaluation of Text-to-Speech Synthesis Using the Rapid Prosody Transcription Paradigm
Jul 06, 2021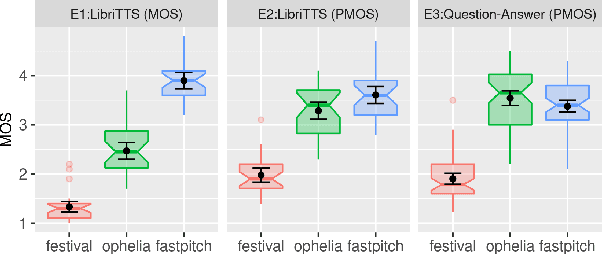
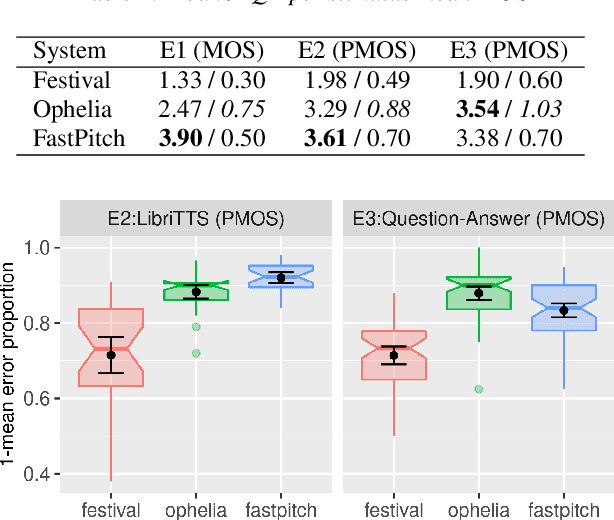
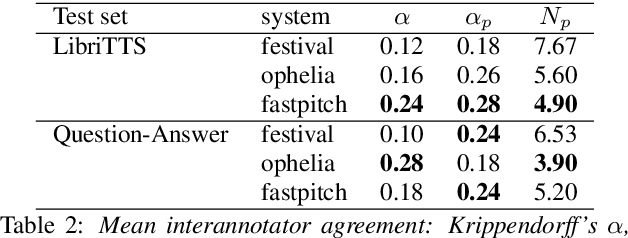
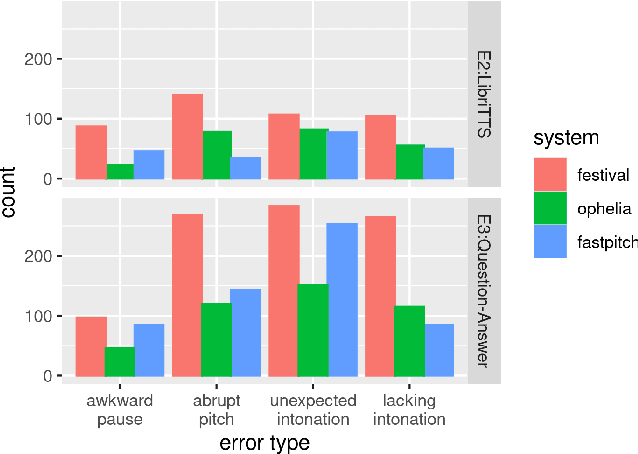
Text-to-Speech synthesis systems are generally evaluated using Mean Opinion Score (MOS) tests, where listeners score samples of synthetic speech on a Likert scale. A major drawback of MOS tests is that they only offer a general measure of overall quality-i.e., the naturalness of an utterance-and so cannot tell us where exactly synthesis errors occur. This can make evaluation of the appropriateness of prosodic variation within utterances inconclusive. To address this, we propose a novel evaluation method based on the Rapid Prosody Transcription paradigm. This allows listeners to mark the locations of errors in an utterance in real-time, providing a probabilistic representation of the perceptual errors that occur in the synthetic signal. We conduct experiments that confirm that the fine-grained evaluation can be mapped to system rankings of standard MOS tests, but the error marking gives a much more comprehensive assessment of synthesized prosody. In particular, for standard audiobook test set samples, we see that error marks consistently cluster around words at major prosodic boundaries indicated by punctuation. However, for question-answer based stimuli, where we control information structure, we see differences emerge in the ability of neural TTS systems to generate context-appropriate prosodic prominence.
Using previous acoustic context to improve Text-to-Speech synthesis
Dec 07, 2020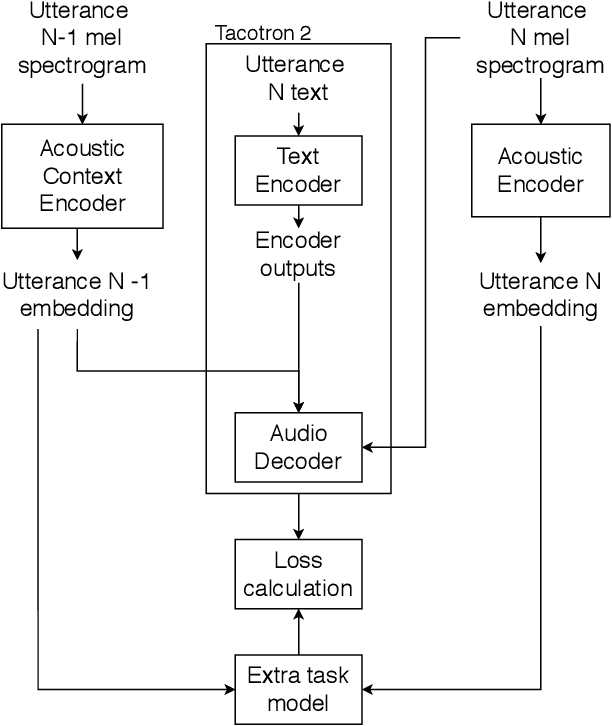
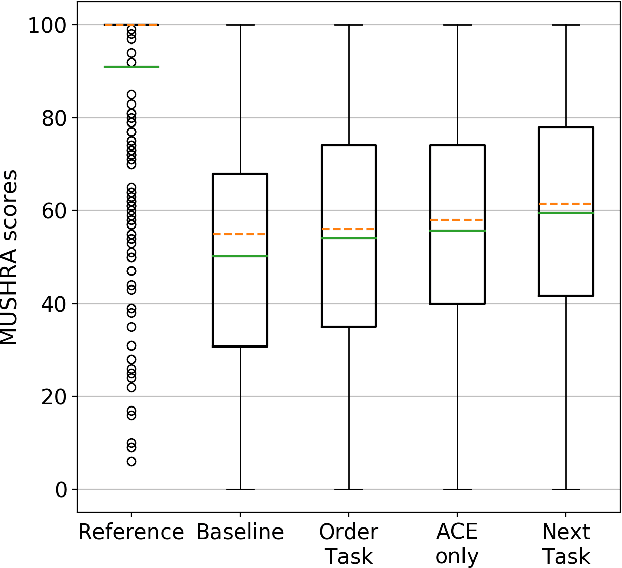
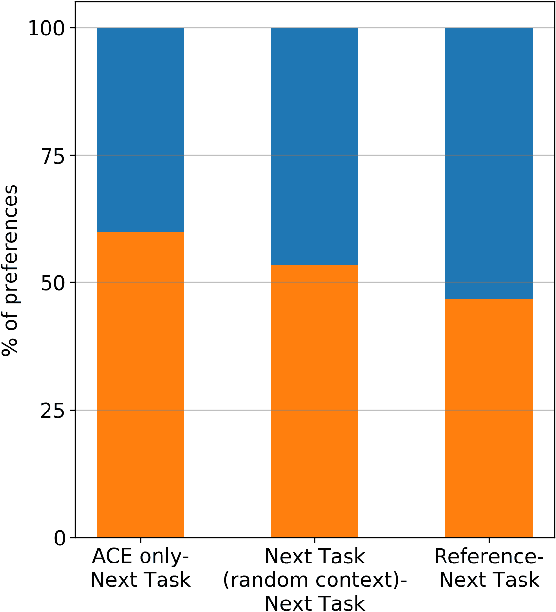
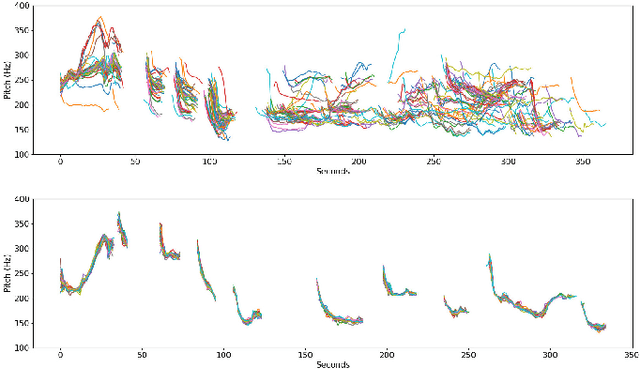
Many speech synthesis datasets, especially those derived from audiobooks, naturally comprise sequences of utterances. Nevertheless, such data are commonly treated as individual, unordered utterances both when training a model and at inference time. This discards important prosodic phenomena above the utterance level. In this paper, we leverage the sequential nature of the data using an acoustic context encoder that produces an embedding of the previous utterance audio. This is input to the decoder in a Tacotron 2 model. The embedding is also used for a secondary task, providing additional supervision. We compare two secondary tasks: predicting the ordering of utterance pairs, and predicting the embedding of the current utterance audio. Results show that the relation between consecutive utterances is informative: our proposed model significantly improves naturalness over a Tacotron 2 baseline.