 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHidden Biases in Conditioning Autoregressive Models
Apr 09, 2026Large language and music models are increasingly used for constrained generation: rhyming lines, fixed meter, inpainting or infilling, positional endings, and other global form requirements. These systems often perform strikingly well, but the induced procedures are usually not exact conditioning of the underlying autoregressive model. This creates a hidden inferential bias, distinct from the better-known notion of bias inherited from the training set: samples are distorted relative to the true constrained distribution, with no generic guarantee of complete coverage of the admissible solution space or of correct conditional probabilities over valid completions. We formalize several exact inference tasks for autoregressive models and prove corresponding hardness results. For succinctly represented autoregressive models whose next-token probabilities are computable in polynomial time, exact sentence-level maximum a posteriori (MAP) decoding is NP-hard. This hardness persists under unary and metrical constraints. On the sampling side, exact conditioned normalization is \#P-hard even for regular constraints such as fixed-length terminal events. Unlike finite-state Markov models, general autoregressive models do not admit a bounded-state dynamic program for these tasks. These results formalize a standard claim in the neural decoding literature: local autoregressive sampling is easy, whereas exact decoding and exact conditioning under global form constraints are computationally intractable in general.
Assisted music creation with Flow Machines: towards new categories of new
Jun 22, 2020



This chapter reflects on about 10 years of research in AI- assisted music composition, in particular during the Flow Machines project. We reflect on the motivations for such a project, its background, its main results and impact, both technological and musical, several years after its completion. We conclude with a proposal for new categories of new, created by the many uses of AI techniques to generate novel material.
Sampling Variations of Lead Sheets
Mar 02, 2017
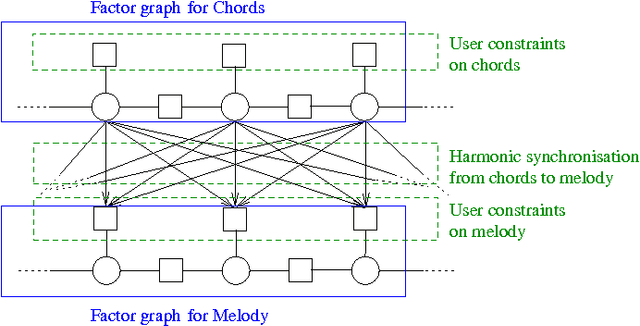
Machine-learning techniques have been recently used with spectacular results to generate artefacts such as music or text. However, these techniques are still unable to capture and generate artefacts that are convincingly structured. In this paper we present an approach to generate structured musical sequences. We introduce a mechanism for sampling efficiently variations of musical sequences. Given a input sequence and a statistical model, this mechanism samples a set of sequences whose distance to the input sequence is approximately within specified bounds. This mechanism is implemented as an extension of belief propagation, and uses local fields to bias the generation. We show experimentally that sampled sequences are indeed closely correlated to the standard musical similarity measure defined by Mongeau and Sankoff. We then show how this mechanism can used to implement composition strategies that enforce arbitrary structure on a musical lead sheet generation problem.