 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Challenge Set for French --> English Machine Translation
Jun 15, 2018

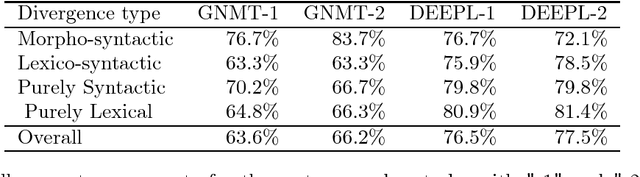
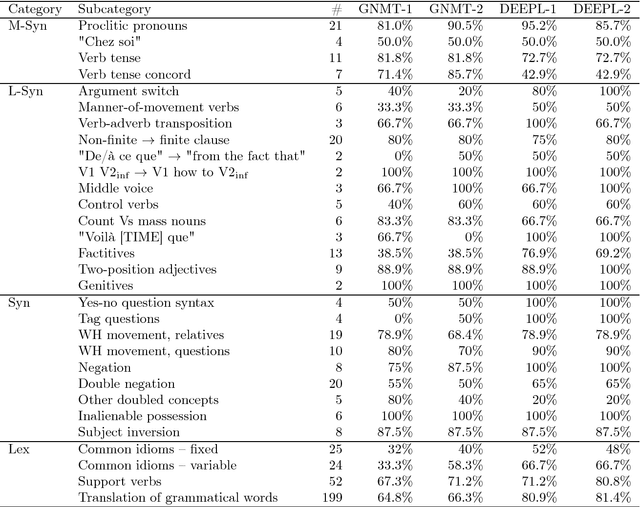
We present a challenge set for French --> English machine translation based on the approach introduced in Isabelle, Cherry and Foster (EMNLP 2017). Such challenge sets are made up of sentences that are expected to be relatively difficult for machines to translate correctly because their most straightforward translations tend to be linguistically divergent. We present here a set of 506 manually constructed French sentences, 307 of which are targeted to the same kinds of structural divergences as in the paper mentioned above. The remaining 199 sentences are designed to test the ability of the systems to correctly translate difficult grammatical words such as prepositions. We report on the results of using this challenge set for testing two different systems, namely Google Translate and DEEPL, each on two different dates (October 2017 and January 2018). All the resulting data are made publicly available.
A Challenge Set Approach to Evaluating Machine Translation
Aug 29, 2017

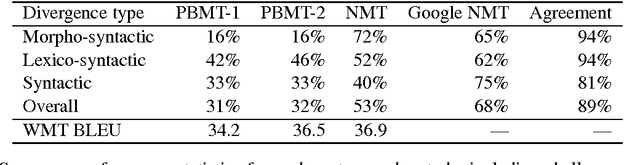
Neural machine translation represents an exciting leap forward in translation quality. But what longstanding weaknesses does it resolve, and which remain? We address these questions with a challenge set approach to translation evaluation and error analysis. A challenge set consists of a small set of sentences, each hand-designed to probe a system's capacity to bridge a particular structural divergence between languages. To exemplify this approach, we present an English-French challenge set, and use it to analyze phrase-based and neural systems. The resulting analysis provides not only a more fine-grained picture of the strengths of neural systems, but also insight into which linguistic phenomena remain out of reach.
Towards an Automatic Dictation System for Translators: the TransTalk Project
Sep 28, 1994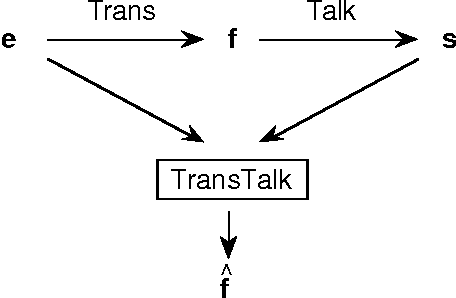

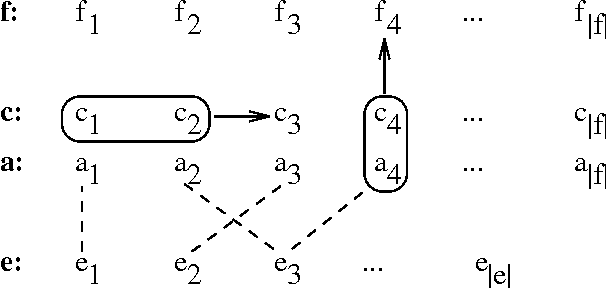
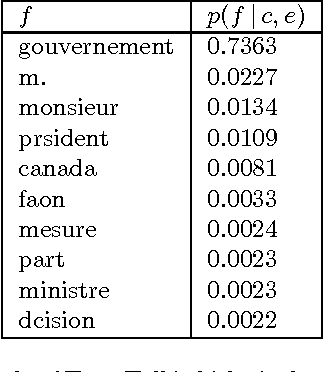
Professional translators often dictate their translations orally and have them typed afterwards. The TransTalk project aims at automating the second part of this process. Its originality as a dictation system lies in the fact that both the acoustic signal produced by the translator and the source text under translation are made available to the system. Probable translations of the source text can be predicted and these predictions used to help the speech recognition system in its lexical choices. We present the results of the first prototype, which show a marked improvement in the performance of the speech recognition task when translation predictions are taken into account.