 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStandardization of Weighted Ranking Correlation Coefficients
Apr 11, 2025A relevant problem in statistics is defining the correlation of two rankings of a list of items. Kendall's tau and Spearman's rho are two well established correlation coefficients, characterized by a symmetric form that ensures zero expected value between two pairs of rankings randomly chosen with uniform probability. However, in recent years, several weighted versions of the original Spearman and Kendall coefficients have emerged that take into account the greater importance of top ranks compared to low ranks, which is common in many contexts. The weighting schemes break the symmetry, causing a non-zero expected value between two random rankings. This issue is very relevant, as it undermines the concept of uncorrelation between rankings. In this paper, we address this problem by proposing a standardization function $g(x)$ that maps a correlation ranking coefficient $\Gamma$ in a standard form $g(\Gamma)$ that has zero expected value, while maintaining the relevant statistical properties of $\Gamma$.
Top-Rank-Focused Adaptive Vote Collection for the Evaluation of Domain-Specific Semantic Models
Oct 09, 2020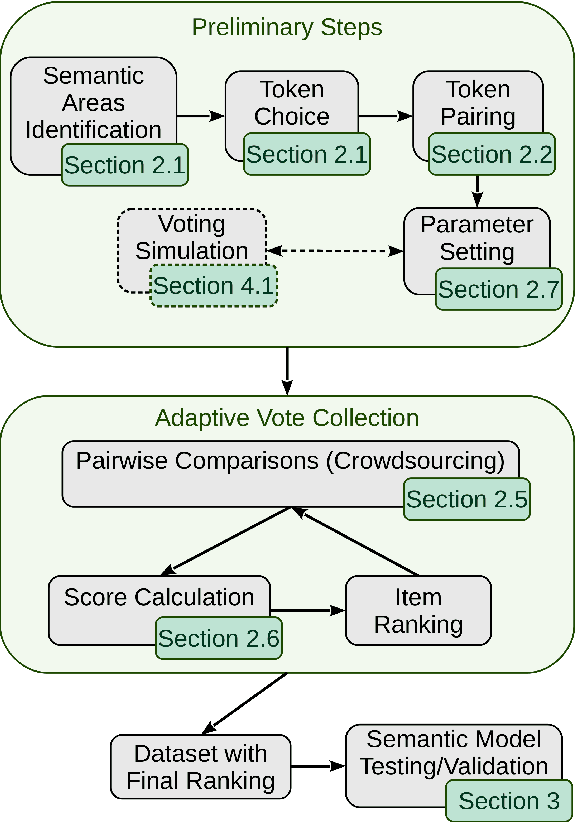
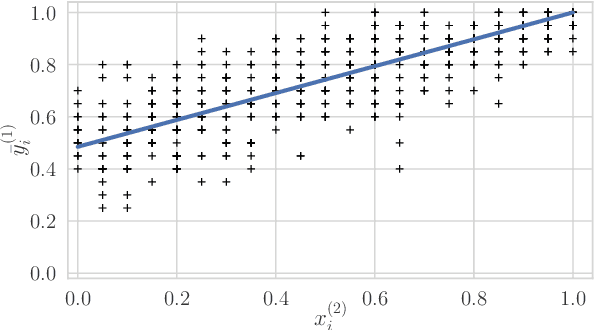
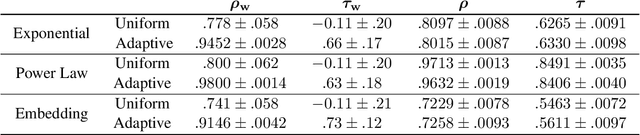
The growth of domain-specific applications of semantic models, boosted by the recent achievements of unsupervised embedding learning algorithms, demands domain-specific evaluation datasets. In many cases, content-based recommenders being a prime example, these models are required to rank words or texts according to their semantic relatedness to a given concept, with particular focus on top ranks. In this work, we give a threefold contribution to address these requirements: (i) we define a protocol for the construction, based on adaptive pairwise comparisons, of a relatedness-based evaluation dataset tailored on the available resources and optimized to be particularly accurate in top-rank evaluation; (ii) we define appropriate metrics, extensions of well-known ranking correlation coefficients, to evaluate a semantic model via the aforementioned dataset by taking into account the greater significance of top ranks. Finally, (iii) we define a stochastic transitivity model to simulate semantic-driven pairwise comparisons, which confirms the effectiveness of the proposed dataset construction protocol.
DNS Covert Channel Detection via Behavioral Analysis: a Machine Learning Approach
Oct 04, 2020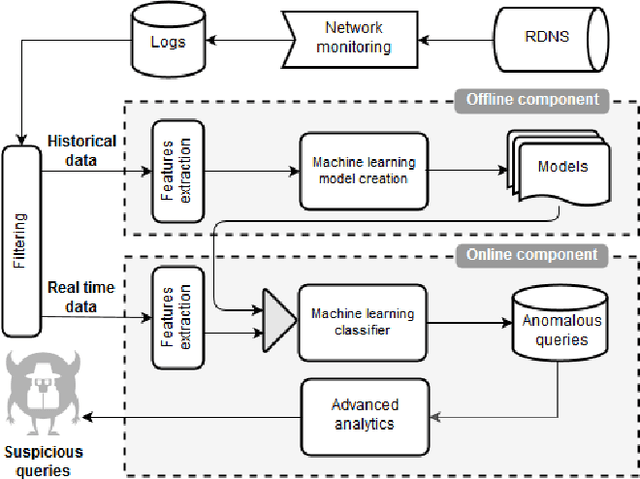
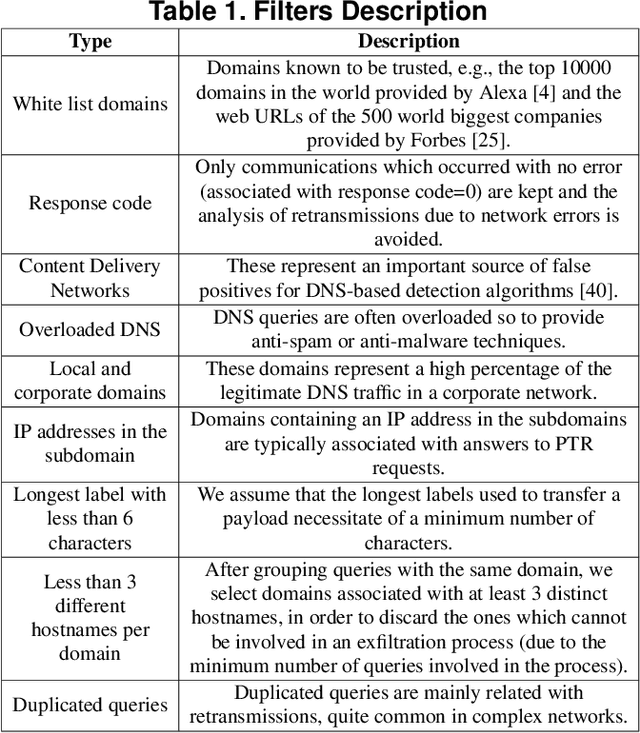
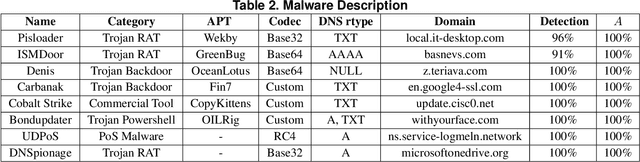

Detecting covert channels among legitimate traffic represents a severe challenge due to the high heterogeneity of networks. Therefore, we propose an effective covert channel detection method, based on the analysis of DNS network data passively extracted from a network monitoring system. The framework is based on a machine learning module and on the extraction of specific anomaly indicators able to describe the problem at hand. The contribution of this paper is two-fold: (i) the machine learning models encompass network profiles tailored to the network users, and not to the single query events, hence allowing for the creation of behavioral profiles and spotting possible deviations from the normal baseline; (ii) models are created in an unsupervised mode, thus allowing for the identification of zero-days attacks and avoiding the requirement of signatures or heuristics for new variants. The proposed solution has been evaluated over a 15-day-long experimental session with the injection of traffic that covers the most relevant exfiltration and tunneling attacks: all the malicious variants were detected, while producing a low false-positive rate during the same period.