 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Lexical and Semantic Vector Search Methods When Classifying Medical Documents
May 16, 2025



Classification is a common AI problem, and vector search is a typical solution. This transforms a given body of text into a numerical representation, known as an embedding, and modern improvements to vector search focus on optimising speed and predictive accuracy. This is often achieved through neural methods that aim to learn language semantics. However, our results suggest that these are not always the best solution. Our task was to classify rigidly-structured medical documents according to their content, and we found that using off-the-shelf semantic vector search produced slightly worse predictive accuracy than creating a bespoke lexical vector search model, and that it required significantly more time to execute. These findings suggest that traditional methods deserve to be contenders in the information retrieval toolkit, despite the prevalence and success of neural models.
Extracting Explainable Dates From Medical Images By Reverse-Engineering UNIX Timestamps
May 16, 2025Dates often contribute towards highly impactful medical decisions, but it is rarely clear how to extract this data. AI has only just begun to be used transcribe such documents, and common methods are either to trust that the output produced by a complex AI model, or to parse the text using regular expressions. Recent work has established that regular expressions are an explainable form of logic, but it is difficult to decompose these into the component parts that are required to construct precise UNIX timestamps. First, we test publicly-available regular expressions, and we found that these were unable to capture a significant number of our dates. Next, we manually created easily-decomposable regular expressions, and we found that these were able to detect the majority of real dates, but also a lot of sequences of text that look like dates. Finally, we used regular expression synthesis to automatically identify regular expressions from the reverse-engineered UNIX timestamps that we created. We find that regular expressions created by regular expression synthesis detect far fewer sequences of text that look like dates than those that were manually created, at the cost of a slight increase to the number of missed dates. Overall, our results show that regular expressions can be created through regular expression synthesis to identify complex dates and date ranges in text transcriptions. To our knowledge, our proposed way of learning deterministic logic by reverse-engineering several many-one mappings and feeding these into a regular expression synthesiser is a new approach.
OCT Data is All You Need: How Vision Transformers with and without Pre-training Benefit Imaging
Feb 17, 2025Optical Coherence Tomography (OCT) provides high-resolution cross-sectional images useful for diagnosing various diseases, but their distinct characteristics from natural images raise questions about whether large-scale pre-training on datasets like ImageNet is always beneficial. In this paper, we investigate the impact of ImageNet-based pre-training on Vision Transformer (ViT) performance for OCT image classification across different dataset sizes. Our experiments cover four-category retinal pathologies (CNV, DME, Drusen, Normal). Results suggest that while pre-training can accelerate convergence and potentially offer better performance in smaller datasets, training from scratch may achieve comparable or even superior accuracy when sufficient OCT data is available. Our findings highlight the importance of matching domain characteristics in pre-training and call for further study on large-scale OCT-specific pre-training.
Structural bias in population-based algorithms
Aug 22, 2014
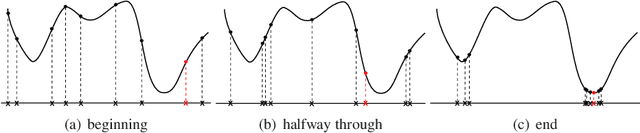
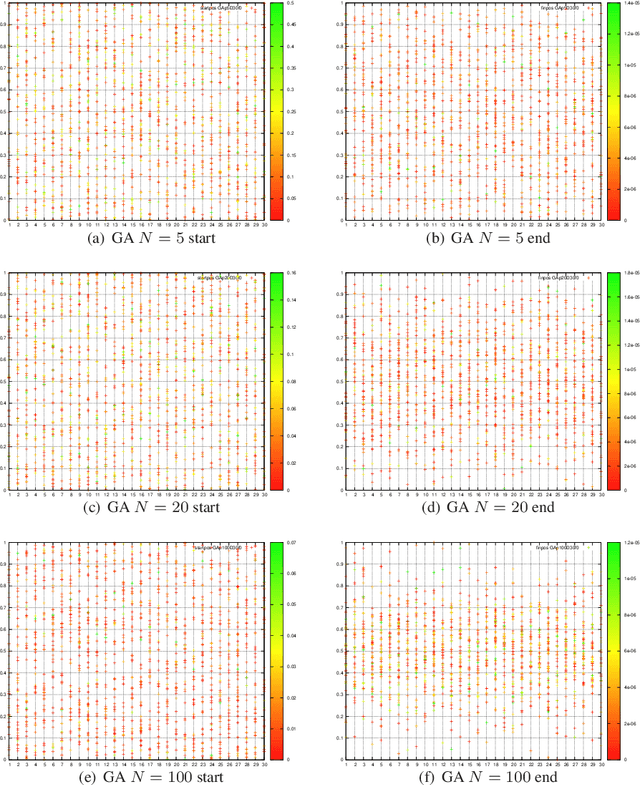
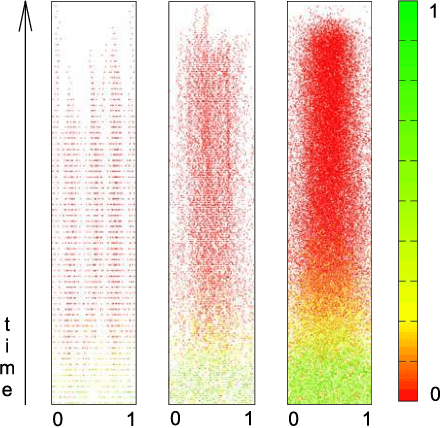
Challenging optimisation problems are abundant in all areas of science. Since the 1950s, scientists have developed ever-diversifying families of black box optimisation algorithms designed to address any optimisation problem, requiring only that quality of a candidate solution is calculated via a fitness function specific to the problem. For such algorithms to be successful, at least three properties are required: an effective informed sampling strategy, that guides generation of new candidates on the basis of fitnesses and locations of previously visited candidates; mechanisms to ensure efficiency, so that same candidates are not repeatedly visited; absence of structural bias, which, if present, would predispose the algorithm towards limiting its search to some regions of solution space. The first two of these properties have been extensively investigated, however the third is little understood. In this article we provide theoretical and empirical analyses that contribute to the understanding of structural bias. We prove a theorem concerning dynamics of population variance in the case of real-valued search spaces. This reveals how structural bias can manifest as non-uniform clustering of population over time. Theory predicts that structural bias is exacerbated with increasing population size and problem difficulty. These predictions reveal two previously unrecognised aspects of structural bias. Respectively, increasing population size, though ostensibly promoting diversity, will magnify any inherent structural bias, and effects of structural bias are more apparent when faced with difficult problems. Our theoretical result also suggests that two commonly used approaches to enhancing exploration, increasing population size and increasing disruptiveness of search operators, have quite distinct implications in terms of structural bias.
Ecosystem-Oriented Distributed Evolutionary Computing
Nov 23, 2012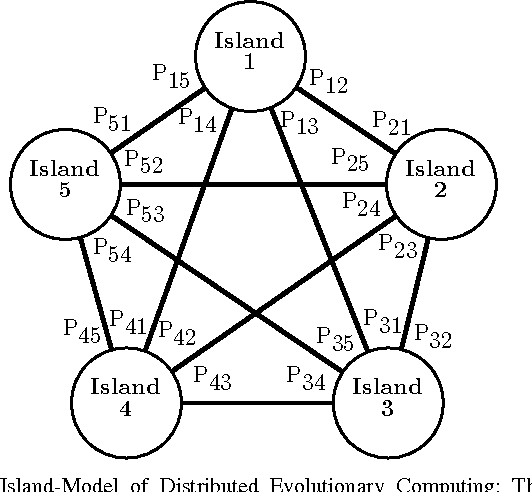
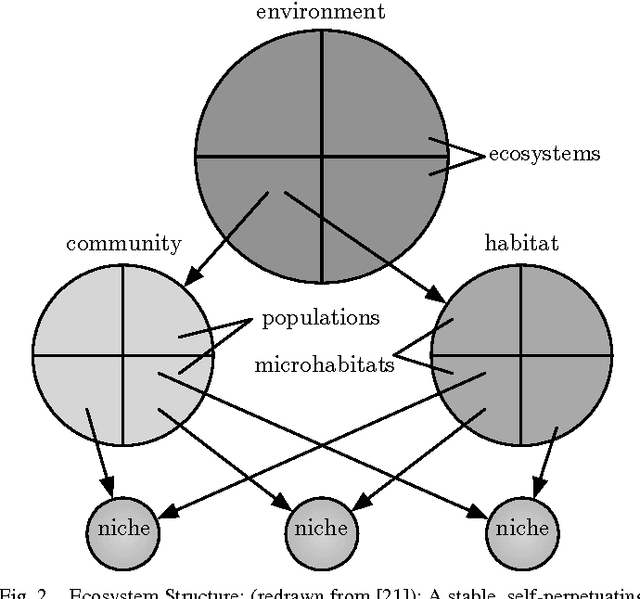
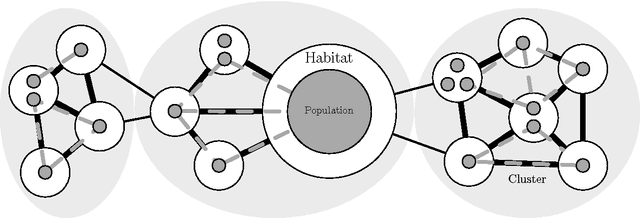
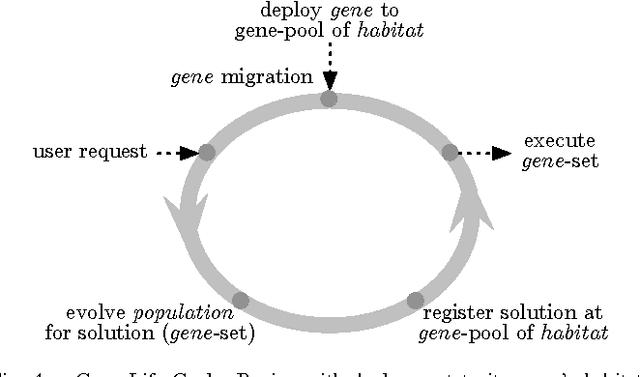
We create a novel optimisation technique inspired by natural ecosystems, where the optimisation works at two levels: a first optimisation, migration of genes which are distributed in a peer-to-peer network, operating continuously in time; this process feeds a second optimisation based on evolutionary computing that operates locally on single peers and is aimed at finding solutions to satisfy locally relevant constraints. We consider from the domain of computer science distributed evolutionary computing, with the relevant theory from the domain of theoretical biology, including the fields of evolutionary and ecological theory, the topological structure of ecosystems, and evolutionary processes within distributed environments. We then define ecosystem- oriented distributed evolutionary computing, imbibed with the properties of self-organisation, scalability and sustainability from natural ecosystems, including a novel form of distributed evolu- tionary computing. Finally, we conclude with a discussion of the apparent compromises resulting from the hybrid model created, such as the network topology.
Self-Organisation of Evolving Agent Populations in Digital Ecosystems
Jan 24, 2012
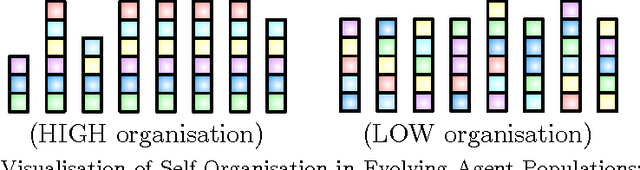
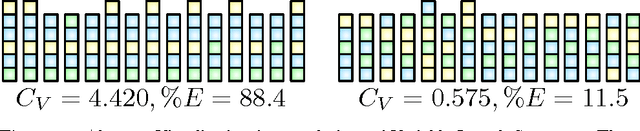
We investigate the self-organising behaviour of Digital Ecosystems, because a primary motivation for our research is to exploit the self-organising properties of biological ecosystems. We extended a definition for the complexity, grounded in the biological sciences, providing a measure of the information in an organism's genome. Next, we extended a definition for the stability, originating from the computer sciences, based upon convergence to an equilibrium distribution. Finally, we investigated a definition for the diversity, relative to the selection pressures provided by the user requests. We conclude with a summary and discussion of the achievements, including the experimental results.
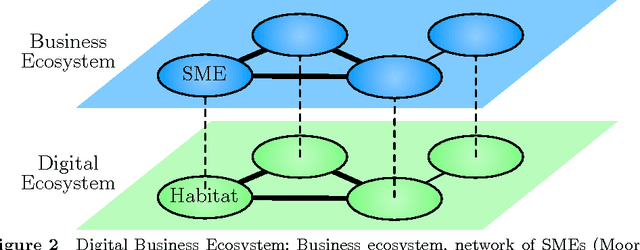
Digital Ecosystems: Ecosystem-Oriented Architectures
Dec 01, 2011
We view Digital Ecosystems to be the digital counterparts of biological ecosystems. Here, we are concerned with the creation of these Digital Ecosystems, exploiting the self-organising properties of biological ecosystems to evolve high-level software applications. Therefore, we created the Digital Ecosystem, a novel optimisation technique inspired by biological ecosystems, where the optimisation works at two levels: a first optimisation, migration of agents which are distributed in a decentralised peer-to-peer network, operating continuously in time; this process feeds a second optimisation based on evolutionary computing that operates locally on single peers and is aimed at finding solutions to satisfy locally relevant constraints. The Digital Ecosystem was then measured experimentally through simulations, with measures originating from theoretical ecology, evaluating its likeness to biological ecosystems. This included its responsiveness to requests for applications from the user base, as a measure of the ecological succession (ecosystem maturity). Overall, we have advanced the understanding of Digital Ecosystems, creating Ecosystem-Oriented Architectures where the word ecosystem is more than just a metaphor.
Stability of Evolving Multi-Agent Systems
Nov 30, 2011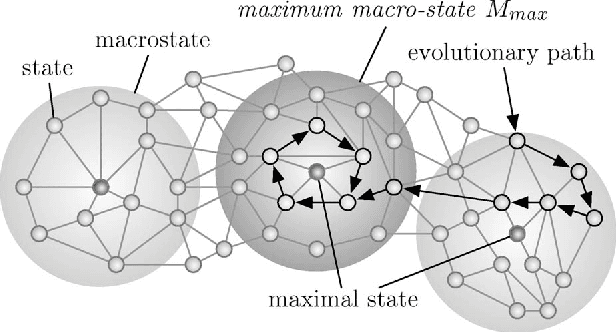
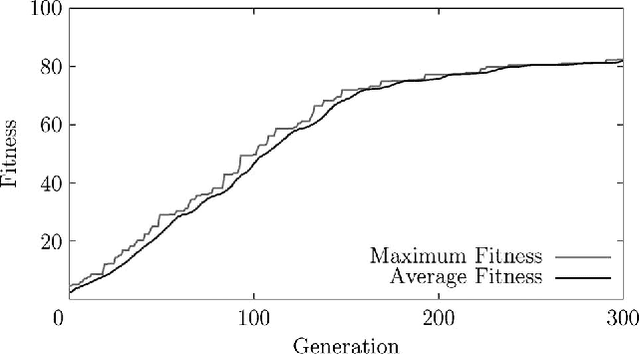
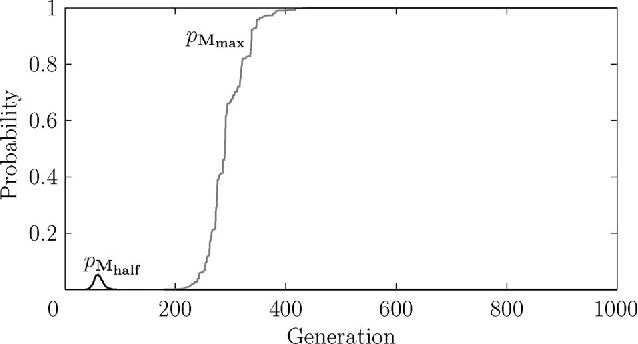

A Multi-Agent System is a distributed system where the agents or nodes perform complex functions that cannot be written down in analytic form. Multi-Agent Systems are highly connected, and the information they contain is mostly stored in the connections. When agents update their state, they take into account the state of the other agents, and they have access to those states via the connections. There is also external, user-generated input into the Multi-Agent System. As so much information is stored in the connections, agents are often memory-less. This memory-less property, together with the randomness of the external input, has allowed us to model Multi-Agent Systems using Markov chains. In this paper, we look at Multi-Agent Systems that evolve, i.e. the number of agents varies according to the fitness of the individual agents. We extend our Markov chain model, and define stability. This is the start of a methodology to control Multi-Agent Systems. We then build upon this to construct an entropy-based definition for the degree of instability (entropy of the limit probabilities), which we used to perform a stability analysis. We then investigated the stability of evolving agent populations through simulation, and show that the results are consistent with the original definition of stability in non-evolving Multi-Agent Systems, proposed by Chli and De Wilde. This paper forms the theoretical basis for the construction of Digital Business Ecosystems, and applications have been reported elsewhere.
* 9 pages, 5 figures, journal
The Computing of Digital Ecosystems
Jan 28, 2011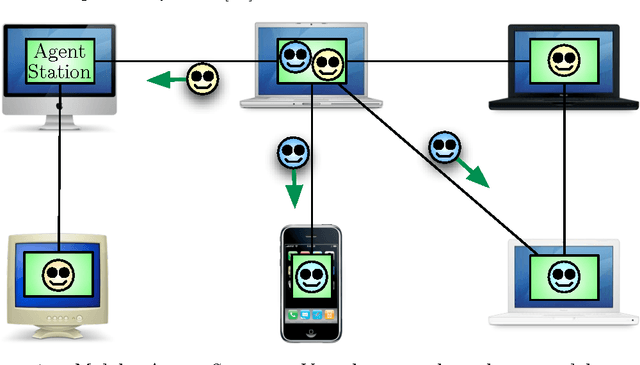

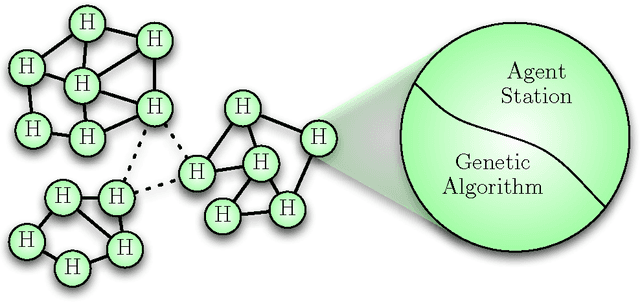
A primary motivation for our research in digital ecosystems is the desire to exploit the self-organising properties of biological ecosystems. Ecosystems are thought to be robust, scalable architectures that can automatically solve complex, dynamic problems. However, the computing technologies that contribute to these properties have not been made explicit in digital ecosystems research. Here, we discuss how different computing technologies can contribute to providing the necessary self-organising features, including Multi-Agent Systems (MASs), Service-Oriented Architectures (SOAs), and distributed evolutionary computing (DEC). The potential for exploiting these properties in digital ecosystems is considered, suggesting how several key features of biological ecosystems can be exploited in Digital Ecosystems, and discussing how mimicking these features may assist in developing robust, scalable self-organising architectures. An example architecture, the Digital Ecosystem, is considered in detail. The Digital Ecosystem is then measured experimentally through simulations, considering the self-organised diversity of its evolving agent populations relative to the user request behaviour.
Digital Ecosystems: Self-Organisation of Evolving Agent Populations
Oct 05, 2009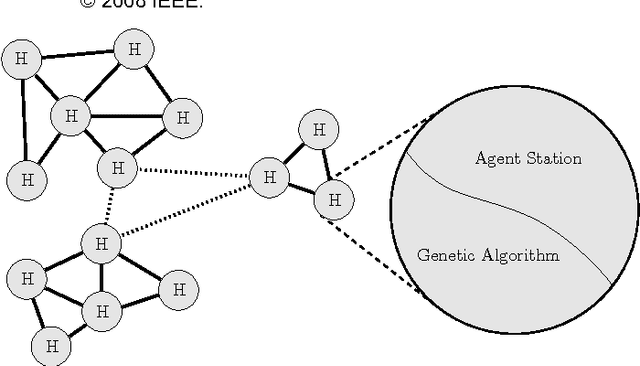
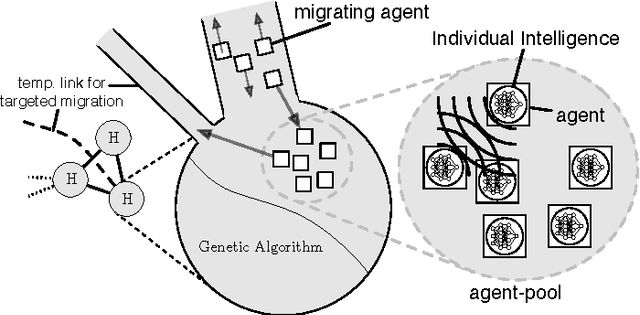
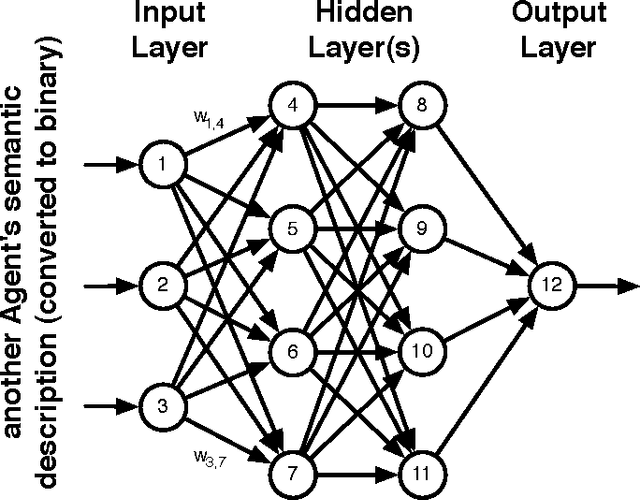
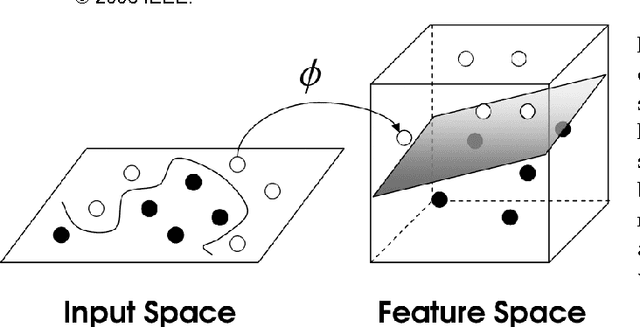
A primary motivation for our research in Digital Ecosystems is the desire to exploit the self-organising properties of biological ecosystems. Ecosystems are thought to be robust, scalable architectures that can automatically solve complex, dynamic problems. Self-organisation is perhaps one of the most desirable features in the systems that we engineer, and it is important for us to be able to measure self-organising behaviour. We investigate the self-organising aspects of Digital Ecosystems, created through the application of evolutionary computing to Multi-Agent Systems (MASs), aiming to determine a macroscopic variable to characterise the self-organisation of the evolving agent populations within. We study a measure for the self-organisation called Physical Complexity; based on statistical physics, automata theory, and information theory, providing a measure of information relative to the randomness in an organism's genome, by calculating the entropy in a population. We investigate an extension to include populations of variable length, and then built upon this to construct an efficiency measure to investigate clustering within evolving agent populations. Overall an insight has been achieved into where and how self-organisation occurs in our Digital Ecosystem, and how it can be quantified.