 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Compression-Inspired Framework for Macro Discovery
Feb 22, 2019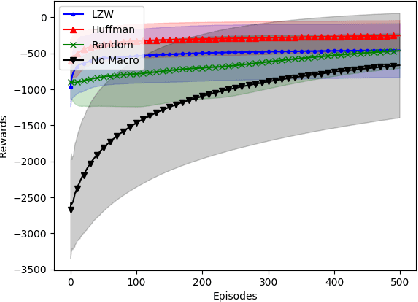
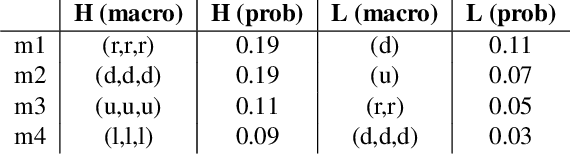
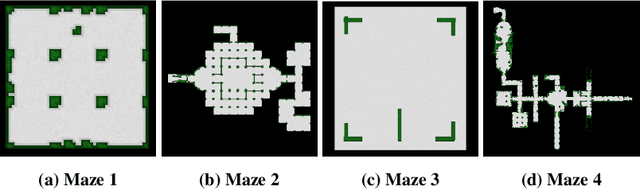
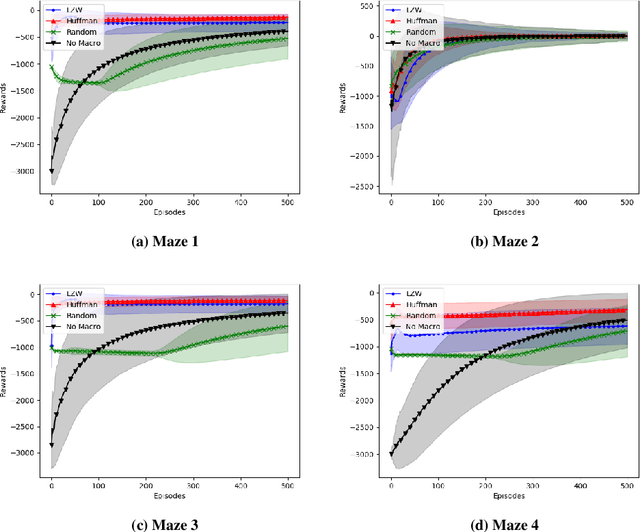
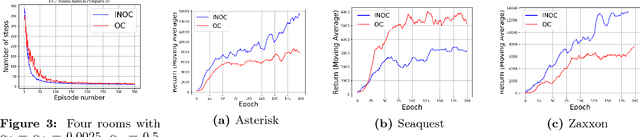
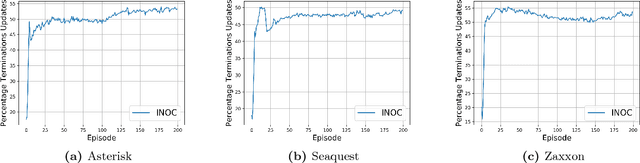
In this paper we consider the problem of how a reinforcement learning agent tasked with solving a set of related Markov decision processes can use knowledge acquired early in its lifetime to improve its ability to more rapidly solve novel, but related, tasks. One way of exploiting this experience is by identifying recurrent patterns in trajectories obtained from well-performing policies. We propose a three-step framework in which an agent 1) generates a set of candidate open-loop macros by compressing trajectories drawn from near-optimal policies; 2) evaluates the value of each macro; and 3) selects a maximally diverse subset of macros that spans the space of policies typically required for solving the set of related tasks. Our experiments show that extending the original primitive action-set of the agent with the identified macros allows it to more rapidly learn an optimal policy in unseen, but similar MDPs.
Asynchronous Coagent Networks: Stochastic Networks for Reinforcement Learning without Backpropagation or a Clock
Feb 21, 2019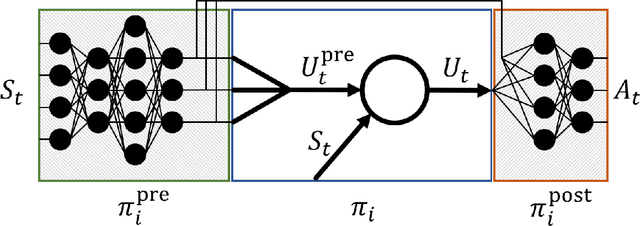
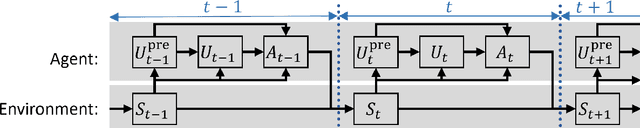
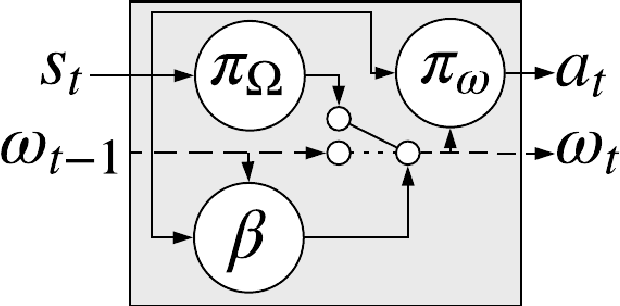
In this paper we introduce a reinforcement learning (RL) approach for training policies, including artificial neural network policies, that is both backpropagation-free and clock-free. It is backpropagation-free in that it does not propagate any information backwards through the network. It is clock-free in that no signal is given to each node in the network to specify when it should compute its output and when it should update its weights. We contend that these two properties increase the biological plausibility of our algorithms and facilitate distributed implementations. Additionally, our approach eliminates the need for customized learning rules for hierarchical RL algorithms like the option-critic.
A Meta-MDP Approach to Exploration for Lifelong Reinforcement Learning
Feb 03, 2019
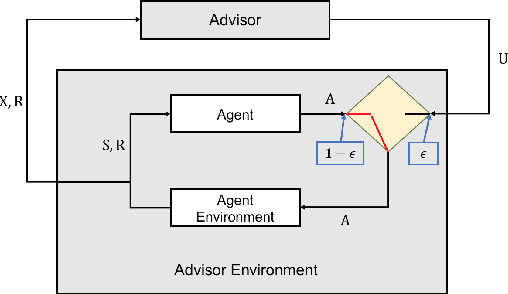
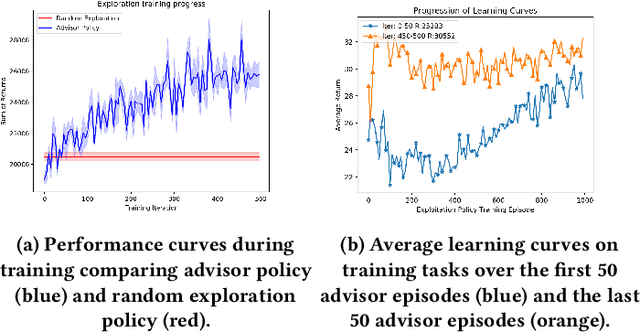
In this paper we consider the problem of how a reinforcement learning agent that is tasked with solving a sequence of reinforcement learning problems (a sequence of Markov decision processes) can use knowledge acquired early in its lifetime to improve its ability to solve new problems. We argue that previous experience with similar problems can provide an agent with information about how it should explore when facing a new but related problem. We show that the search for an optimal exploration strategy can be formulated as a reinforcement learning problem itself and demonstrate that such strategy can leverage patterns found in the structure of related problems. We conclude with experiments that show the benefits of optimizing an exploration strategy using our proposed approach.
Learning Action Representations for Reinforcement Learning
Feb 01, 2019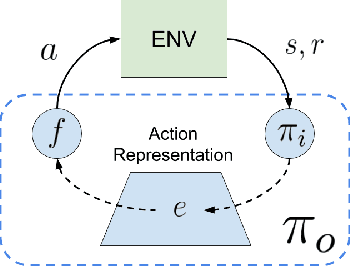
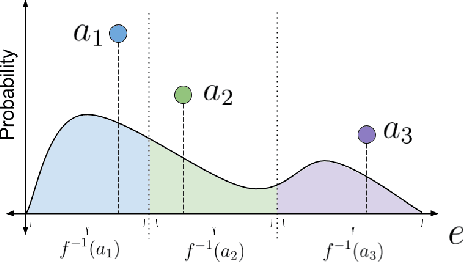
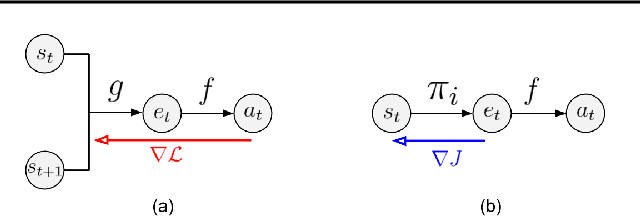
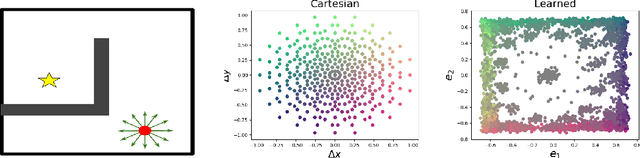
Most model-free reinforcement learning methods leverage state representations (embeddings) for generalization, but either ignore structure in the space of actions or assume the structure is provided a priori. We show how a policy can be decomposed into a component that acts in a low-dimensional space of action representations and a component that transforms these representations into actual actions. These representations improve generalization over large, finite action sets by allowing the agent to infer the outcomes of actions similar to actions already taken. We provide an algorithm to both learn and use action representations and provide conditions for its convergence. The efficacy of the proposed method is demonstrated on large-scale real-world problems.
Privacy Preserving Off-Policy Evaluation
Feb 01, 2019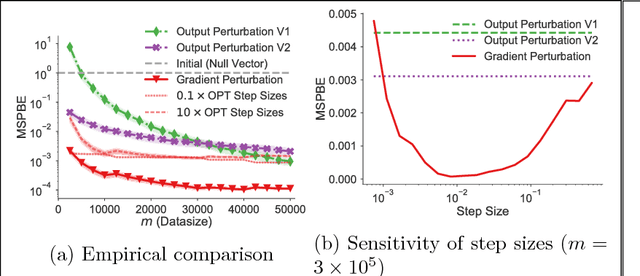
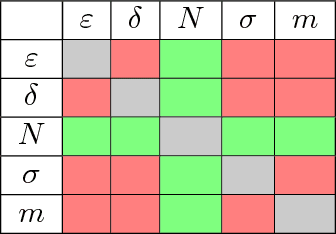
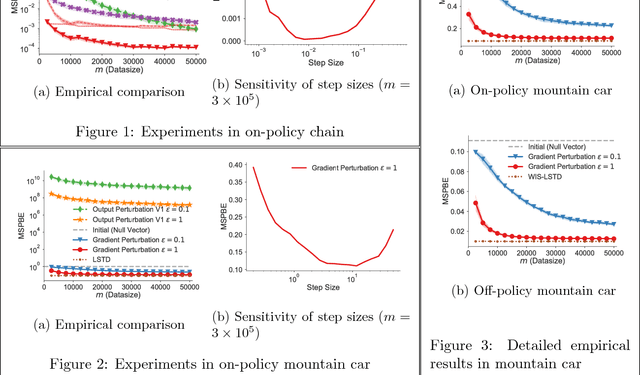
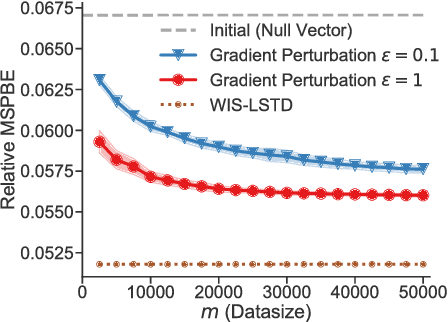
Many reinforcement learning applications involve the use of data that is sensitive, such as medical records of patients or financial information. However, most current reinforcement learning methods can leak information contained within the (possibly sensitive) data on which they are trained. To address this problem, we present the first differentially private approach for off-policy evaluation. We provide a theoretical analysis of the privacy-preserving properties of our algorithm and analyze its utility (speed of convergence). After describing some results of this theoretical analysis, we show empirically that our method outperforms previous methods (which are restricted to the on-policy setting).
Natural Option Critic
Dec 04, 2018
The recently proposed option-critic architecture Bacon et al. provide a stochastic policy gradient approach to hierarchical reinforcement learning. Specifically, they provide a way to estimate the gradient of the expected discounted return with respect to parameters that define a finite number of temporally extended actions, called \textit{options}. In this paper we show how the option-critic architecture can be extended to estimate the natural gradient of the expected discounted return. To this end, the central questions that we consider in this paper are: 1) what is the definition of the natural gradient in this context, 2) what is the Fisher information matrix associated with an option's parameterized policy, 3) what is the Fisher information matrix associated with an option's parameterized termination function, and 4) how can a compatible function approximation approach be leveraged to obtain natural gradient estimates for both the parameterized policy and parameterized termination functions of an option with per-time-step time and space complexity linear in the total number of parameters. Based on answers to these questions we introduce the natural option critic algorithm. Experimental results showcase improvement over the vanilla gradient approach.
Using Options and Covariance Testing for Long Horizon Off-Policy Policy Evaluation
Dec 05, 2017
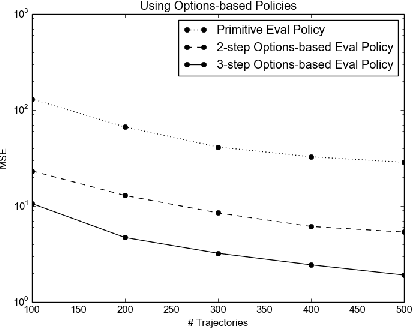
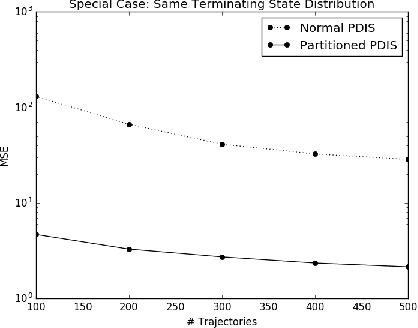
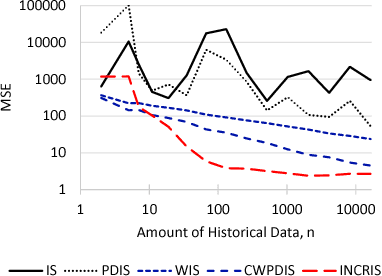
Evaluating a policy by deploying it in the real world can be risky and costly. Off-policy policy evaluation (OPE) algorithms use historical data collected from running a previous policy to evaluate a new policy, which provides a means for evaluating a policy without requiring it to ever be deployed. Importance sampling is a popular OPE method because it is robust to partial observability and works with continuous states and actions. However, the amount of historical data required by importance sampling can scale exponentially with the horizon of the problem: the number of sequential decisions that are made. We propose using policies over temporally extended actions, called options, and show that combining these policies with importance sampling can significantly improve performance for long-horizon problems. In addition, we can take advantage of special cases that arise due to options-based policies to further improve the performance of importance sampling. We further generalize these special cases to a general covariance testing rule that can be used to decide which weights to drop in an IS estimate, and derive a new IS algorithm called Incremental Importance Sampling that can provide significantly more accurate estimates for a broad class of domains.
On Ensuring that Intelligent Machines Are Well-Behaved
Aug 17, 2017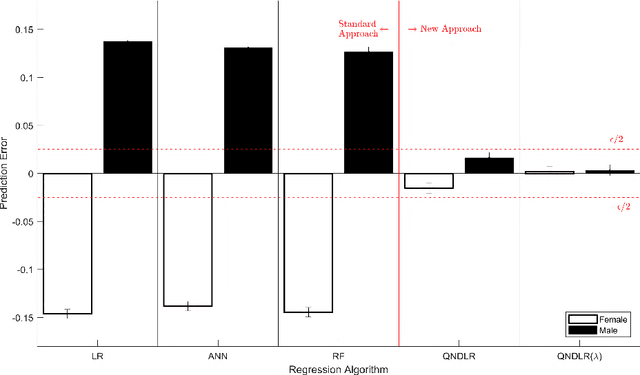
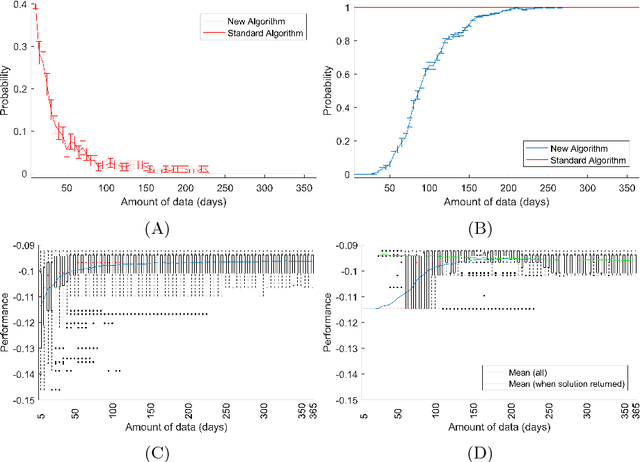
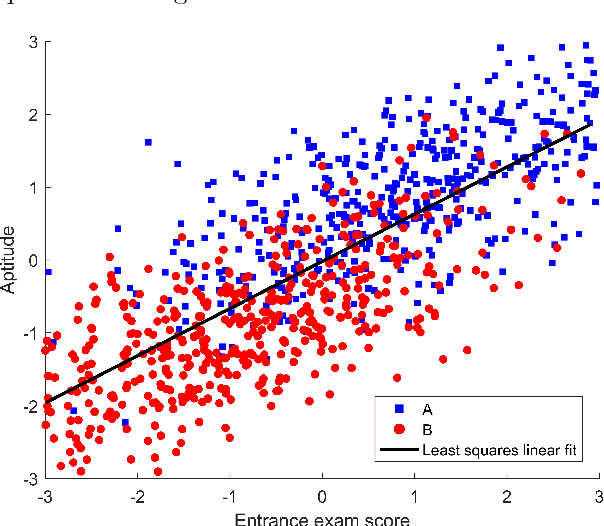
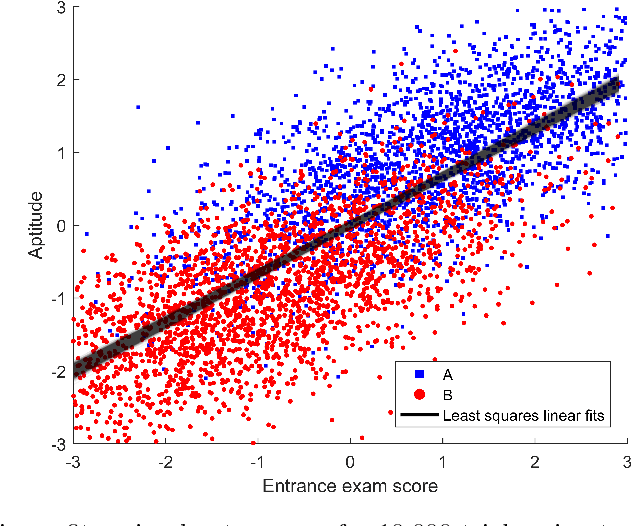
Machine learning algorithms are everywhere, ranging from simple data analysis and pattern recognition tools used across the sciences to complex systems that achieve super-human performance on various tasks. Ensuring that they are well-behaved---that they do not, for example, cause harm to humans or act in a racist or sexist way---is therefore not a hypothetical problem to be dealt with in the future, but a pressing one that we address here. We propose a new framework for designing machine learning algorithms that simplifies the problem of specifying and regulating undesirable behaviors. To show the viability of this new framework, we use it to create new machine learning algorithms that preclude the sexist and harmful behaviors exhibited by standard machine learning algorithms in our experiments. Our framework for designing machine learning algorithms simplifies the safe and responsible application of machine learning.
Policy Gradient Methods for Reinforcement Learning with Function Approximation and Action-Dependent Baselines
Jun 20, 2017We show how an action-dependent baseline can be used by the policy gradient theorem using function approximation, originally presented with action-independent baselines by (Sutton et al. 2000).
Data-Efficient Policy Evaluation Through Behavior Policy Search
Jun 12, 2017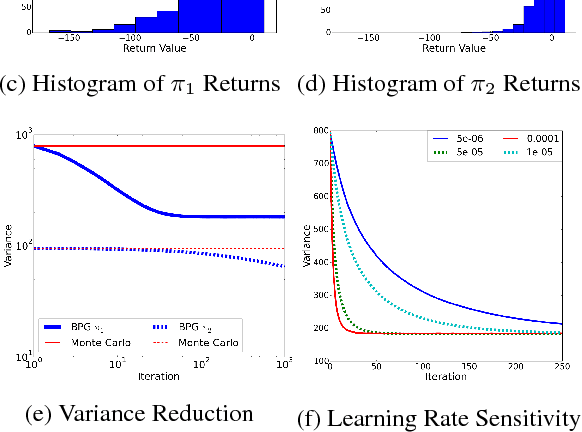
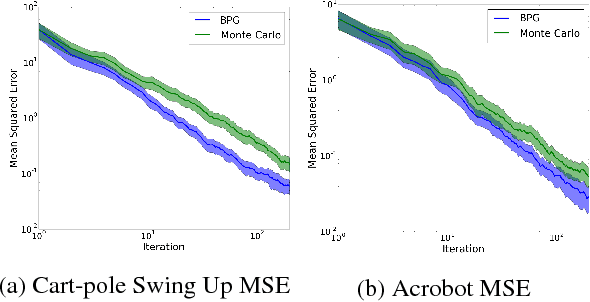
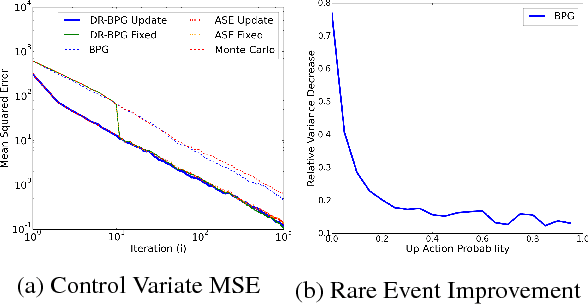
We consider the task of evaluating a policy for a Markov decision process (MDP). The standard unbiased technique for evaluating a policy is to deploy the policy and observe its performance. We show that the data collected from deploying a different policy, commonly called the behavior policy, can be used to produce unbiased estimates with lower mean squared error than this standard technique. We derive an analytic expression for the optimal behavior policy --- the behavior policy that minimizes the mean squared error of the resulting estimates. Because this expression depends on terms that are unknown in practice, we propose a novel policy evaluation sub-problem, behavior policy search: searching for a behavior policy that reduces mean squared error. We present a behavior policy search algorithm and empirically demonstrate its effectiveness in lowering the mean squared error of policy performance estimates.