 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing positive spanning sets to achieve stationarity with the Boosted DC Algorithm
Jul 26, 2019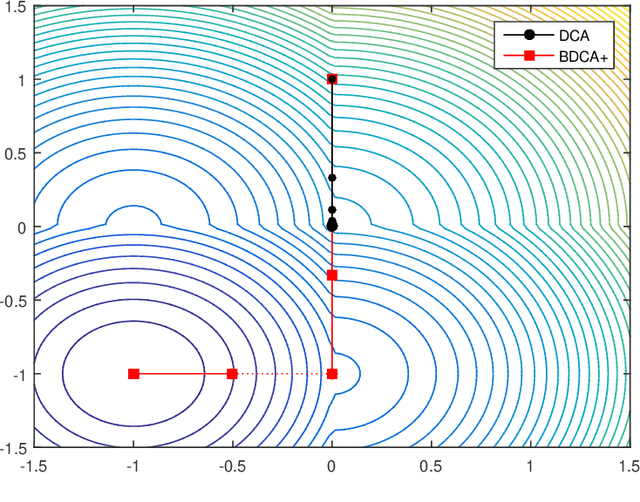
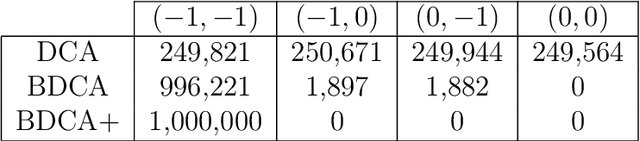
The Difference of Convex function Algorithm (DCA) is widely used for minimizing the difference of two convex functions. A recently proposed accelerated version, termed BDCA for Boosted DC Algorithm, incorporates a line search step to achieve a larger decrease of the objective value at each iteration. Thanks to this step, BDCA usually converges much faster than DCA in practice. The solutions found by DCA are guaranteed to be critical points of the problem, but they are rarely local minima. Although BDCA tends to improve the objective value of the solutions it finds, these are frequently just critical points as well. In this paper we combine BDCA with a simple Derivative-Free Optimization (DFO) algorithm to force the stationarity (lack of descent direction) at the point obtained. The potential of this approach is illustrated through some computational experiments on a Minimum-Sum-of-Squares problem. Our numerical results demonstrate that the new method provides better solutions while still remains faster than DCA in the majority of test cases.
The Boosted DC Algorithm for nonsmooth functions
Dec 14, 2018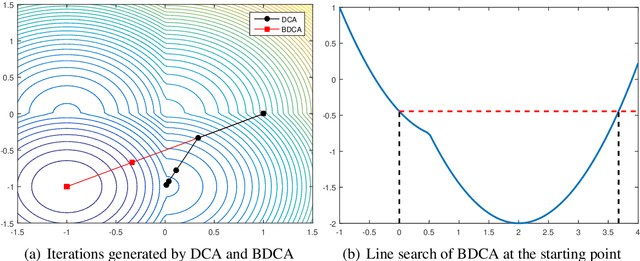
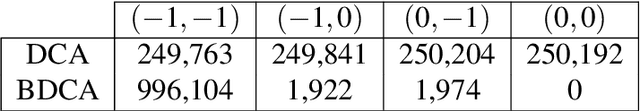
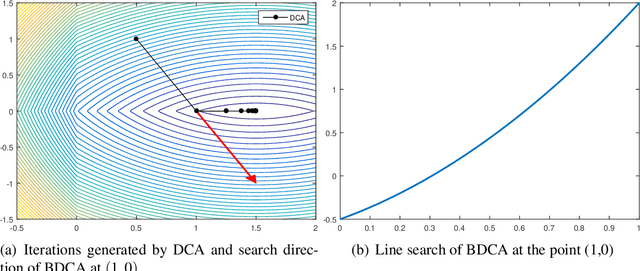
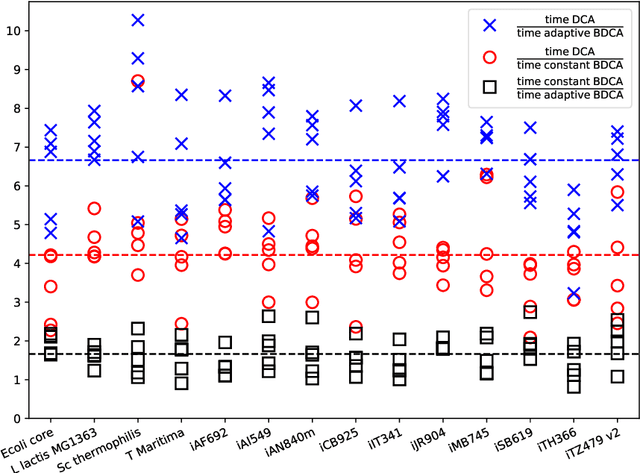
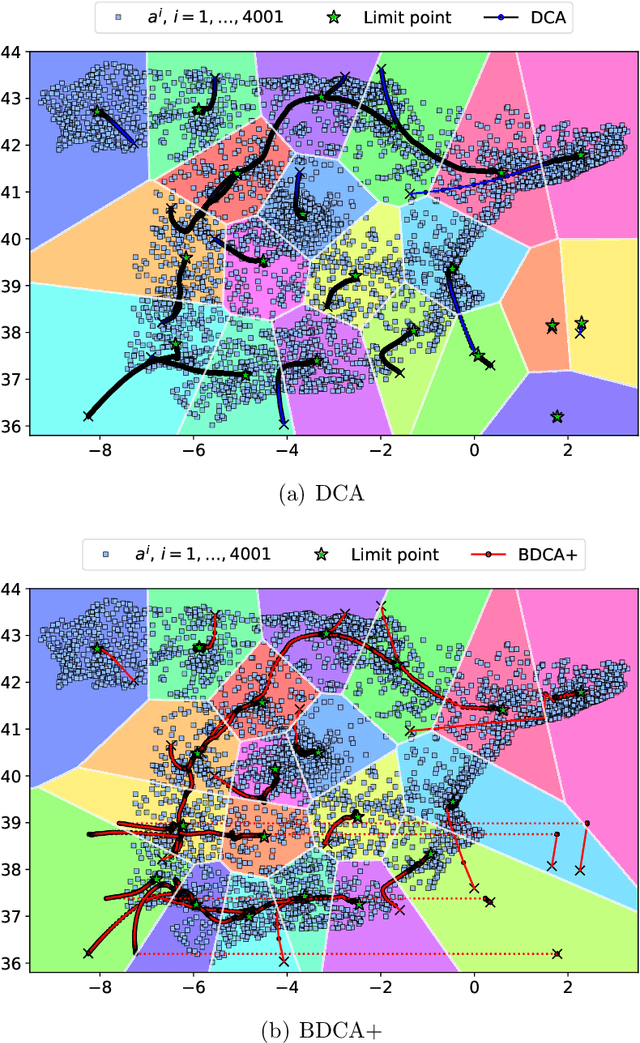
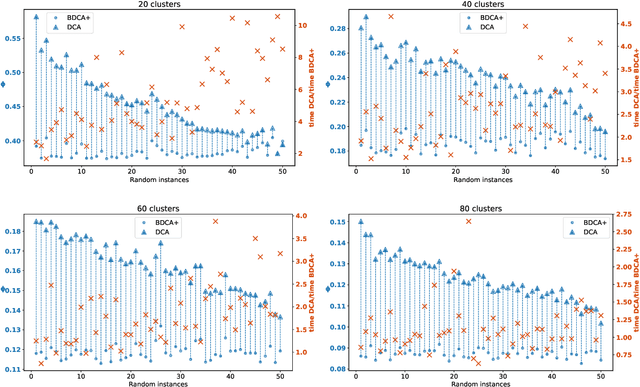
The Boosted Difference of Convex functions Algorithm (BDCA) was recently proposed for minimizing smooth difference of convex (DC) functions. BDCA accelerates the convergence of the classical Difference of Convex functions Algorithm (DCA) thanks to an additional line search step. The purpose of this paper is twofold. Firstly, to show that this scheme can be generalized and successfully applied to certain types of nonsmooth DC functions, namely, those that can be expressed as the difference of a smooth function and a possibly nonsmooth one. Secondly, to show that there is complete freedom in the choice of the trial step size for the line search, which is something that can further improve its performance. We prove that any limit point of the BDCA iterative sequence is a critical point of the problem under consideration, and that the corresponding objective value is monotonically decreasing and convergent. The global convergence and convergent rate of the iterations are obtained under the Kurdyka-Lojasiewicz property. Applications and numerical experiments for two problems in data science are presented, demonstrating that BDCA outperforms DCA. Specifically, for the Minimum Sum-of-Squares Clustering problem, BDCA was on average sixteen times faster than DCA, and for the Multidimensional Scaling problem, BDCA was three times faster than DCA.