 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing the Google Books corpus: Strong limits to inferences of socio-cultural and linguistic evolution
Mar 24, 2017


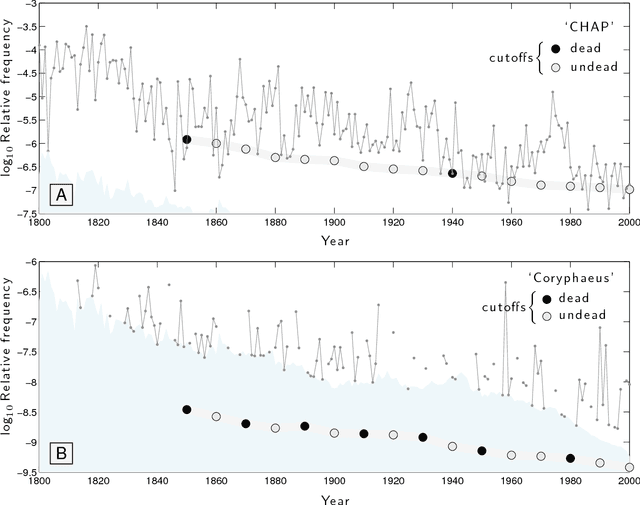
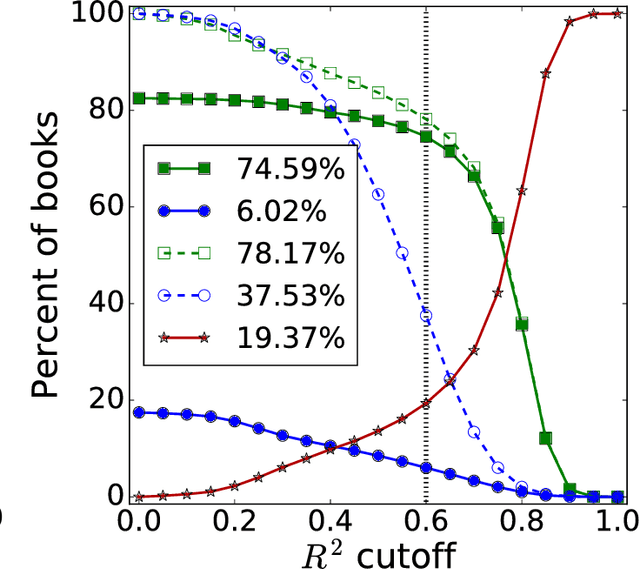
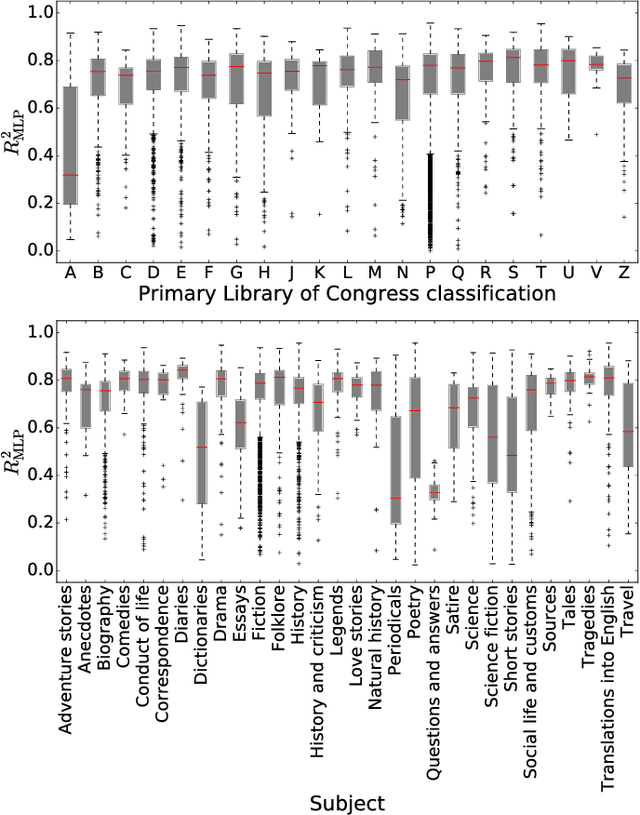
It is tempting to treat frequency trends from the Google Books data sets as indicators of the "true" popularity of various words and phrases. Doing so allows us to draw quantitatively strong conclusions about the evolution of cultural perception of a given topic, such as time or gender. However, the Google Books corpus suffers from a number of limitations which make it an obscure mask of cultural popularity. A primary issue is that the corpus is in effect a library, containing one of each book. A single, prolific author is thereby able to noticeably insert new phrases into the Google Books lexicon, whether the author is widely read or not. With this understood, the Google Books corpus remains an important data set to be considered more lexicon-like than text-like. Here, we show that a distinct problematic feature arises from the inclusion of scientific texts, which have become an increasingly substantive portion of the corpus throughout the 1900s. The result is a surge of phrases typical to academic articles but less common in general, such as references to time in the form of citations. We highlight these dynamics by examining and comparing major contributions to the statistical divergence of English data sets between decades in the period 1800--2000. We find that only the English Fiction data set from the second version of the corpus is not heavily affected by professional texts, in clear contrast to the first version of the fiction data set and both unfiltered English data sets. Our findings emphasize the need to fully characterize the dynamics of the Google Books corpus before using these data sets to draw broad conclusions about cultural and linguistic evolution.
Is language evolution grinding to a halt? The scaling of lexical turbulence in English fiction suggests it is not
Mar 24, 2017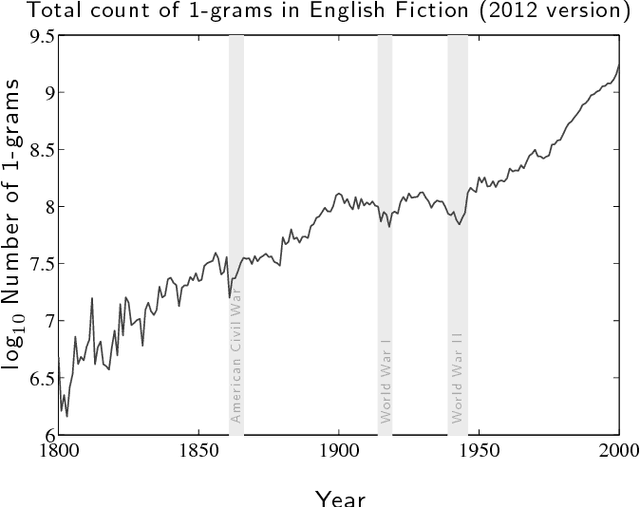
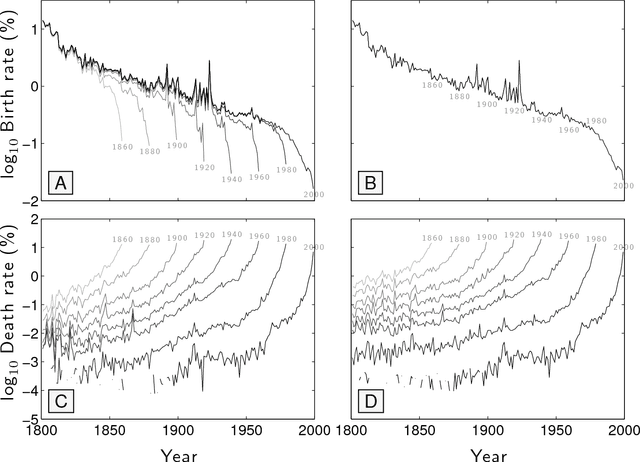
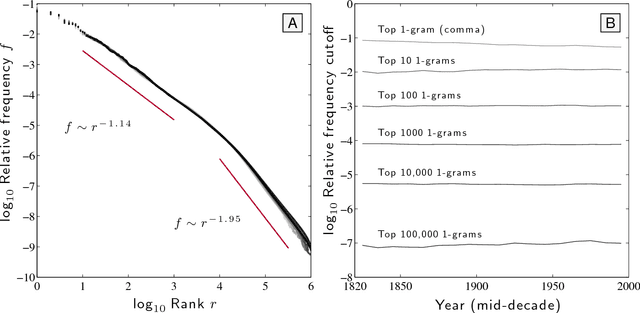
Of basic interest is the quantification of the long term growth of a language's lexicon as it develops to more completely cover both a culture's communication requirements and knowledge space. Here, we explore the usage dynamics of words in the English language as reflected by the Google Books 2012 English Fiction corpus. We critique an earlier method that found decreasing birth and increasing death rates of words over the second half of the 20th Century, showing death rates to be strongly affected by the imposed time cutoff of the arbitrary present and not increasing dramatically. We provide a robust, principled approach to examining lexical evolution by tracking the volume of word flux across various relative frequency thresholds. We show that while the overall statistical structure of the English language remains stable over time in terms of its raw Zipf distribution, we find evidence of an enduring `lexical turbulence': The flux of words across frequency thresholds from decade to decade scales superlinearly with word rank and exhibits a scaling break we connect to that of Zipf's law. To better understand the changing lexicon, we examine the contributions to the Jensen-Shannon divergence of individual words crossing frequency thresholds. We also find indications that scholarly works about fiction are strongly represented in the 2012 English Fiction corpus, and suggest that a future revision of the corpus should attempt to separate critical works from fiction itself.
The emotional arcs of stories are dominated by six basic shapes
Sep 26, 2016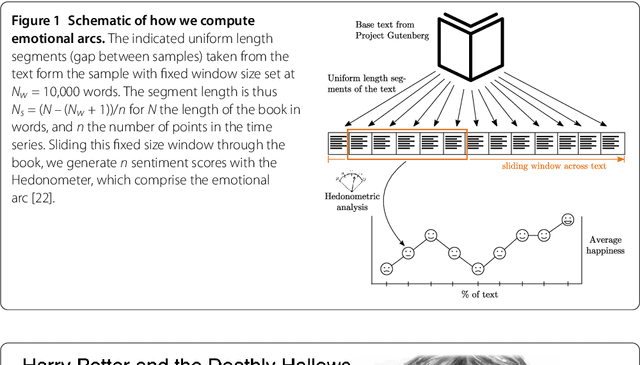
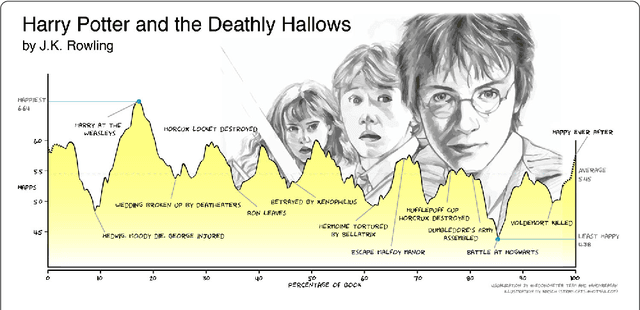
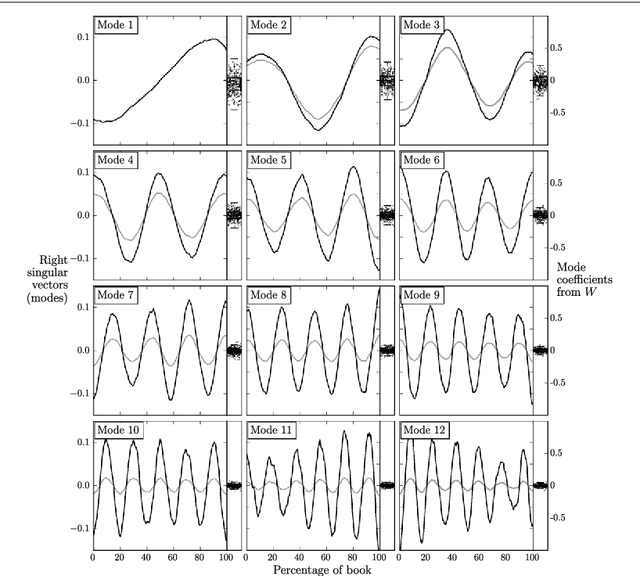
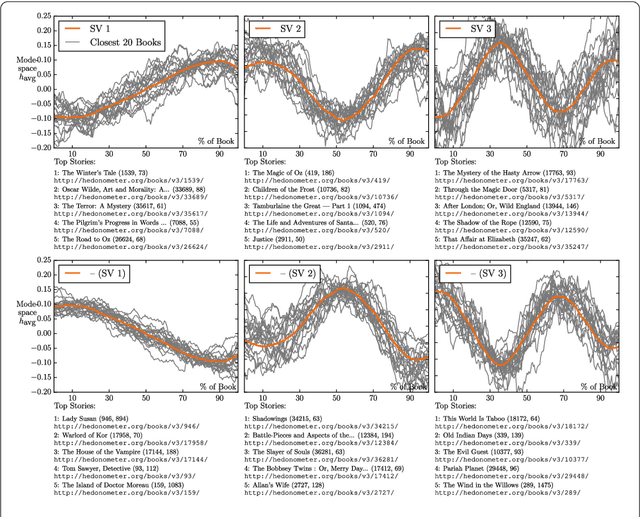
Advances in computing power, natural language processing, and digitization of text now make it possible to study a culture's evolution through its texts using a "big data" lens. Our ability to communicate relies in part upon a shared emotional experience, with stories often following distinct emotional trajectories and forming patterns that are meaningful to us. Here, by classifying the emotional arcs for a filtered subset of 1,327 stories from Project Gutenberg's fiction collection, we find a set of six core emotional arcs which form the essential building blocks of complex emotional trajectories. We strengthen our findings by separately applying Matrix decomposition, supervised learning, and unsupervised learning. For each of these six core emotional arcs, we examine the closest characteristic stories in publication today and find that particular emotional arcs enjoy greater success, as measured by downloads.
Benchmarking sentiment analysis methods for large-scale texts: A case for using continuum-scored words and word shift graphs
Sep 07, 2016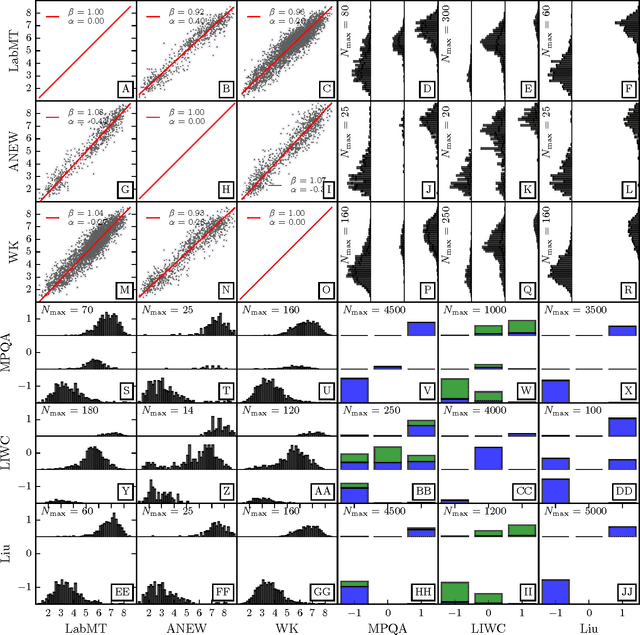
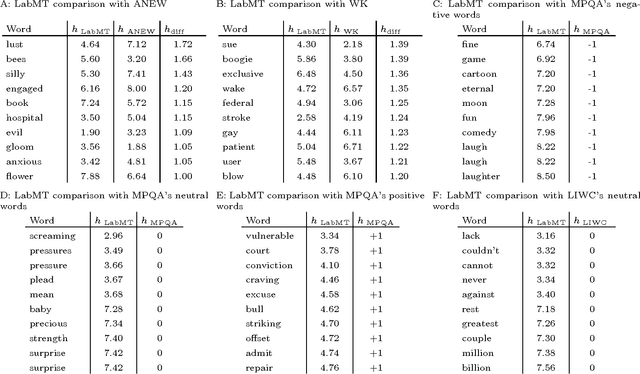
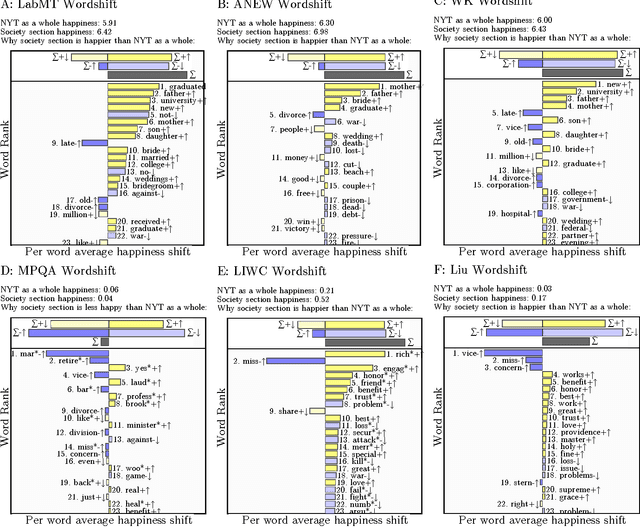
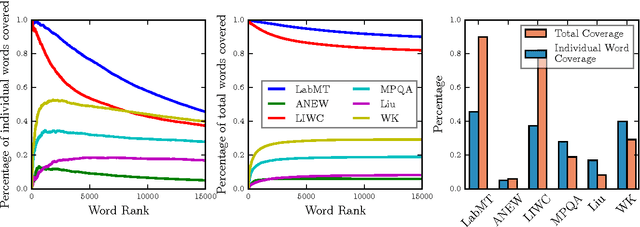
The emergence and global adoption of social media has rendered possible the real-time estimation of population-scale sentiment, bearing profound implications for our understanding of human behavior. Given the growing assortment of sentiment measuring instruments, comparisons between them are evidently required. Here, we perform detailed tests of 6 dictionary-based methods applied to 4 different corpora, and briefly examine a further 20 methods. We show that a dictionary-based method will only perform both reliably and meaningfully if (1) the dictionary covers a sufficiently large enough portion of a given text's lexicon when weighted by word usage frequency; and (2) words are scored on a continuous scale.
Zipf's law is a consequence of coherent language production
Aug 05, 2016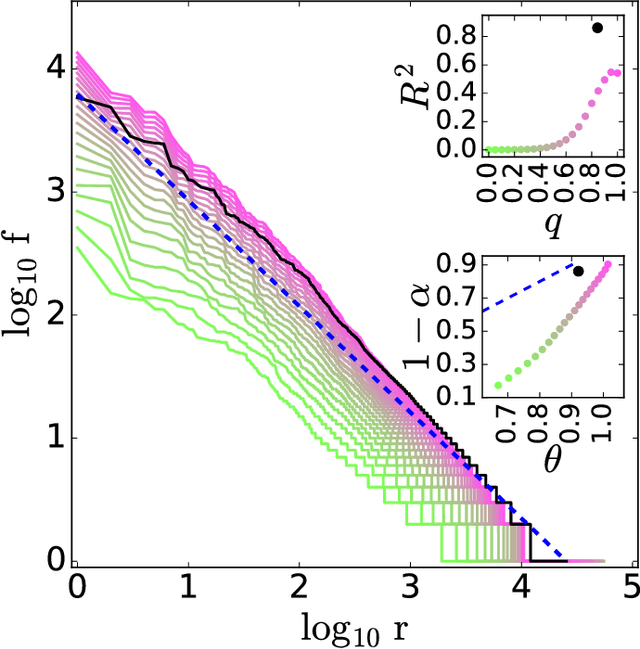
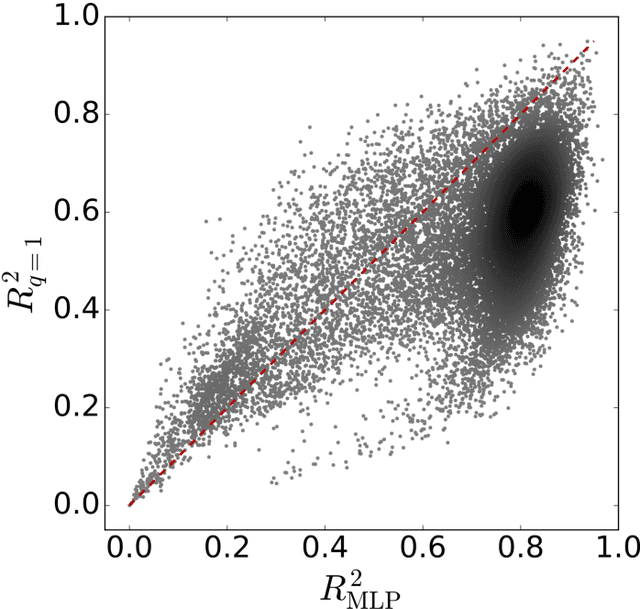
The task of text segmentation may be undertaken at many levels in text analysis---paragraphs, sentences, words, or even letters. Here, we focus on a relatively fine scale of segmentation, hypothesizing it to be in accord with a stochastic model of language generation, as the smallest scale where independent units of meaning are produced. Our goals in this letter include the development of methods for the segmentation of these minimal independent units, which produce feature-representations of texts that align with the independence assumption of the bag-of-terms model, commonly used for prediction and classification in computational text analysis. We also propose the measurement of texts' association (with respect to realized segmentations) to the model of language generation. We find (1) that our segmentations of phrases exhibit much better associations to the generation model than words and (2), that texts which are well fit are generally topically homogeneous. Because our generative model produces Zipf's law, our study further suggests that Zipf's law may be a consequence of homogeneity in language production.
Sifting Robotic from Organic Text: A Natural Language Approach for Detecting Automation on Twitter
Jun 14, 2016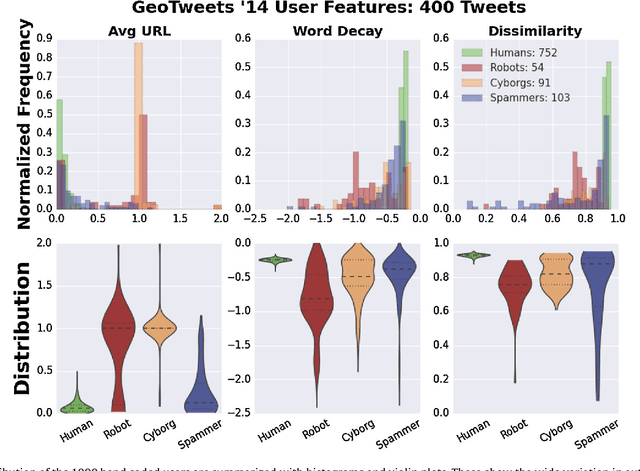
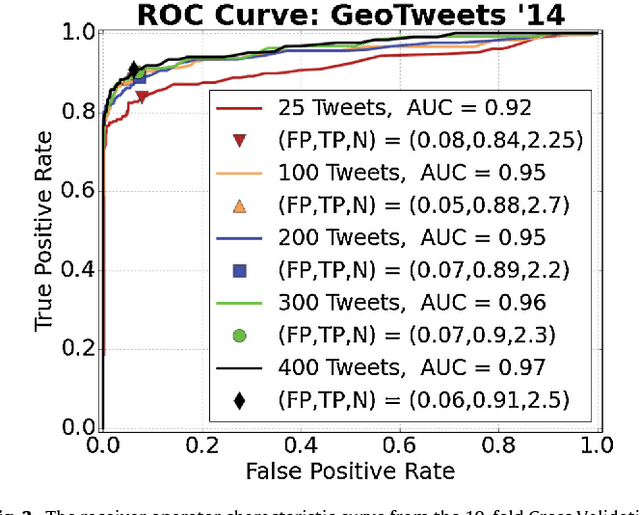
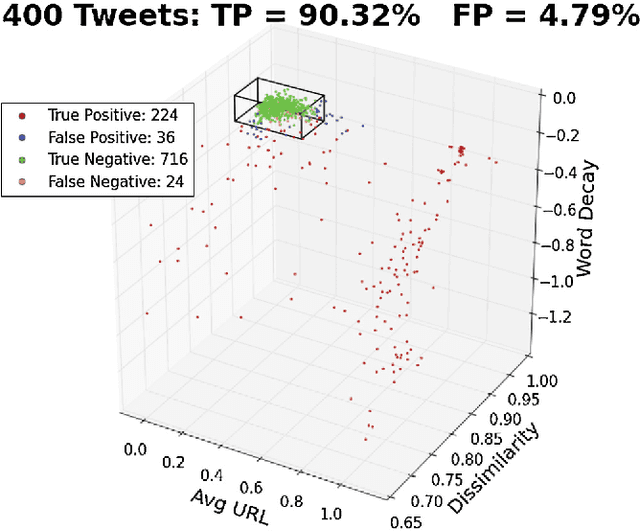
Twitter, a popular social media outlet, has evolved into a vast source of linguistic data, rich with opinion, sentiment, and discussion. Due to the increasing popularity of Twitter, its perceived potential for exerting social influence has led to the rise of a diverse community of automatons, commonly referred to as bots. These inorganic and semi-organic Twitter entities can range from the benevolent (e.g., weather-update bots, help-wanted-alert bots) to the malevolent (e.g., spamming messages, advertisements, or radical opinions). Existing detection algorithms typically leverage meta-data (time between tweets, number of followers, etc.) to identify robotic accounts. Here, we present a powerful classification scheme that exclusively uses the natural language text from organic users to provide a criterion for identifying accounts posting automated messages. Since the classifier operates on text alone, it is flexible and may be applied to any textual data beyond the Twitter-sphere.
Identifying missing dictionary entries with frequency-conserving context models
Jul 29, 2015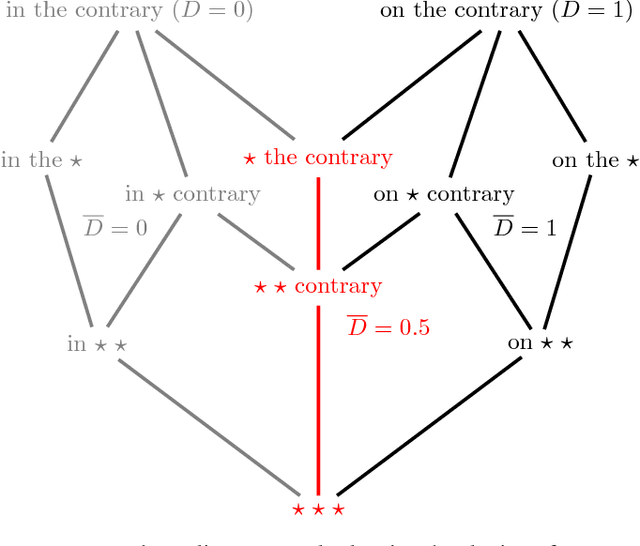
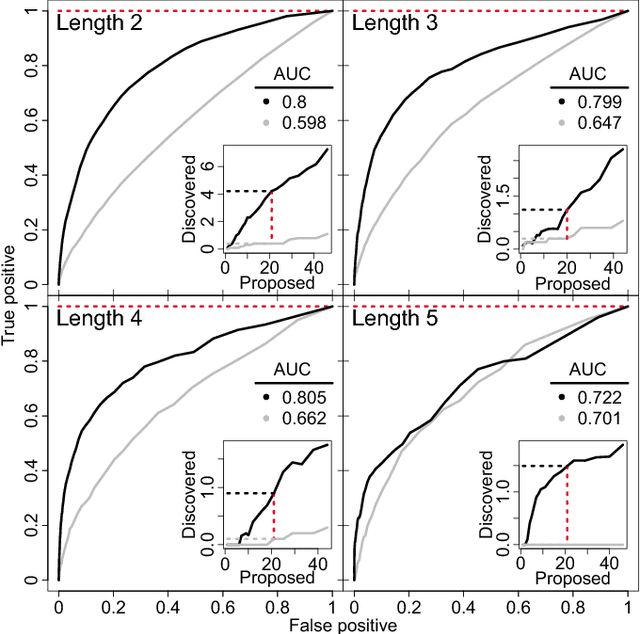
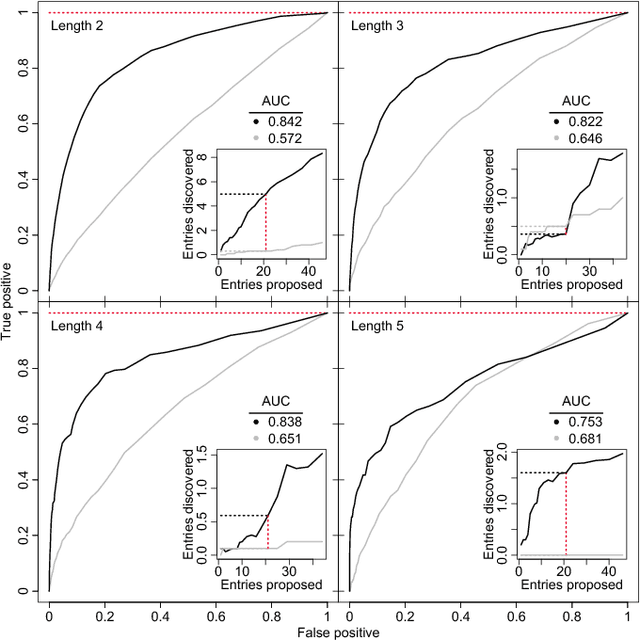
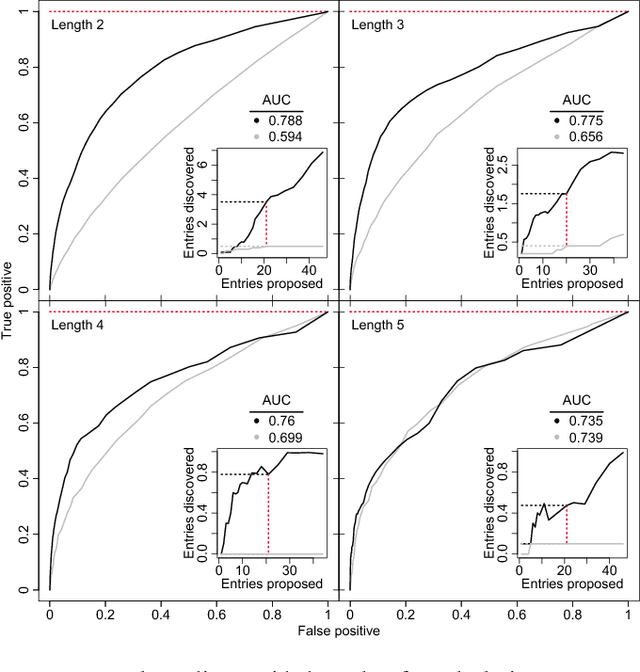
In an effort to better understand meaning from natural language texts, we explore methods aimed at organizing lexical objects into contexts. A number of these methods for organization fall into a family defined by word ordering. Unlike demographic or spatial partitions of data, these collocation models are of special importance for their universal applicability. While we are interested here in text and have framed our treatment appropriately, our work is potentially applicable to other areas of research (e.g., speech, genomics, and mobility patterns) where one has ordered categorical data, (e.g., sounds, genes, and locations). Our approach focuses on the phrase (whether word or larger) as the primary meaning-bearing lexical unit and object of study. To do so, we employ our previously developed framework for generating word-conserving phrase-frequency data. Upon training our model with the Wiktionary---an extensive, online, collaborative, and open-source dictionary that contains over 100,000 phrasal-definitions---we develop highly effective filters for the identification of meaningful, missing phrase-entries. With our predictions we then engage the editorial community of the Wiktionary and propose short lists of potential missing entries for definition, developing a breakthrough, lexical extraction technique, and expanding our knowledge of the defined English lexicon of phrases.
Zipf's law holds for phrases, not words
Mar 04, 2015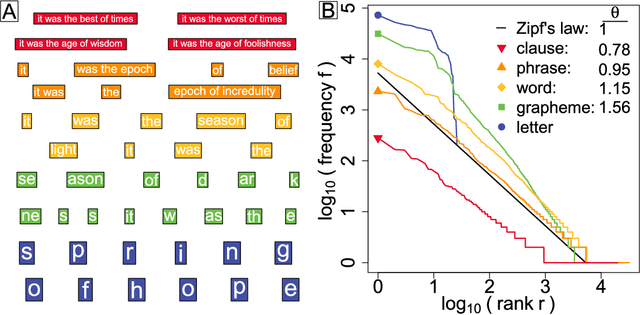
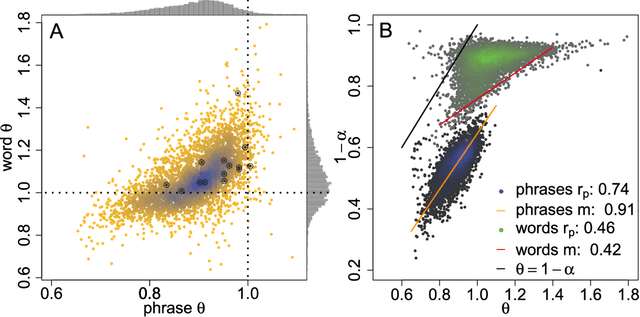
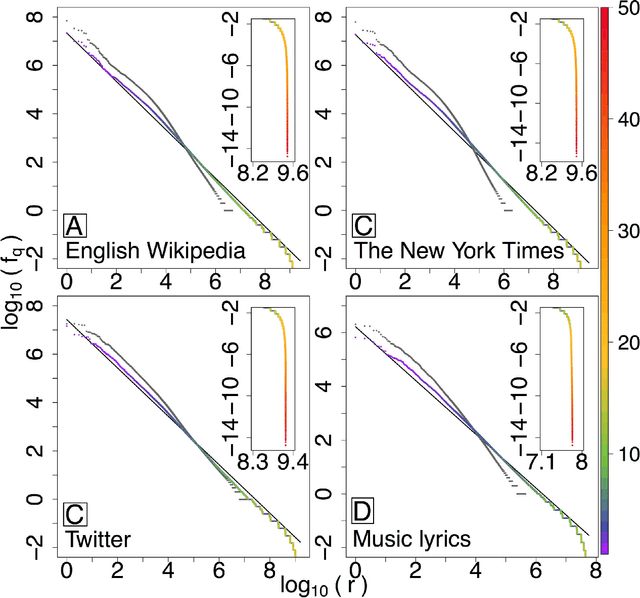
With Zipf's law being originally and most famously observed for word frequency, it is surprisingly limited in its applicability to human language, holding over no more than three to four orders of magnitude before hitting a clear break in scaling. Here, building on the simple observation that phrases of one or more words comprise the most coherent units of meaning in language, we show empirically that Zipf's law for phrases extends over as many as nine orders of rank magnitude. In doing so, we develop a principled and scalable statistical mechanical method of random text partitioning, which opens up a rich frontier of rigorous text analysis via a rank ordering of mixed length phrases.
Text mixing shapes the anatomy of rank-frequency distributions: A modern Zipfian mechanics for natural language
Jan 30, 2015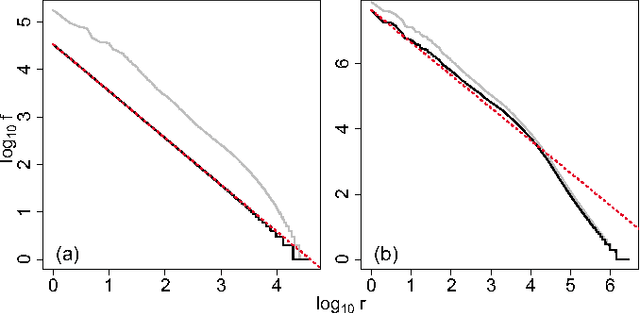
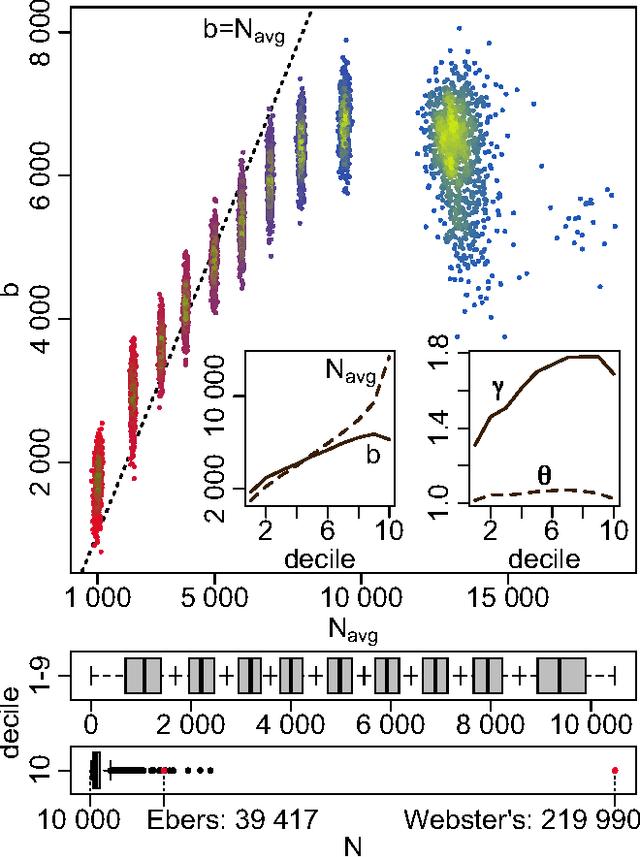
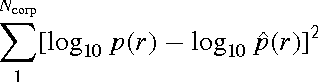
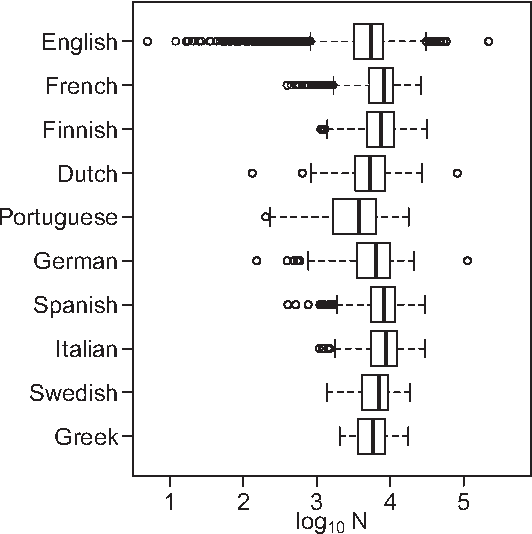
Natural languages are full of rules and exceptions. One of the most famous quantitative rules is Zipf's law which states that the frequency of occurrence of a word is approximately inversely proportional to its rank. Though this `law' of ranks has been found to hold across disparate texts and forms of data, analyses of increasingly large corpora over the last 15 years have revealed the existence of two scaling regimes. These regimes have thus far been explained by a hypothesis suggesting a separability of languages into core and non-core lexica. Here, we present and defend an alternative hypothesis, that the two scaling regimes result from the act of aggregating texts. We observe that text mixing leads to an effective decay of word introduction, which we show provides accurate predictions of the location and severity of breaks in scaling. Upon examining large corpora from 10 languages in the Project Gutenberg eBooks collection (eBooks), we find emphatic empirical support for the universality of our claim.
* 9 pages, 6 figures, and 1 table
Human language reveals a universal positivity bias
Jun 15, 2014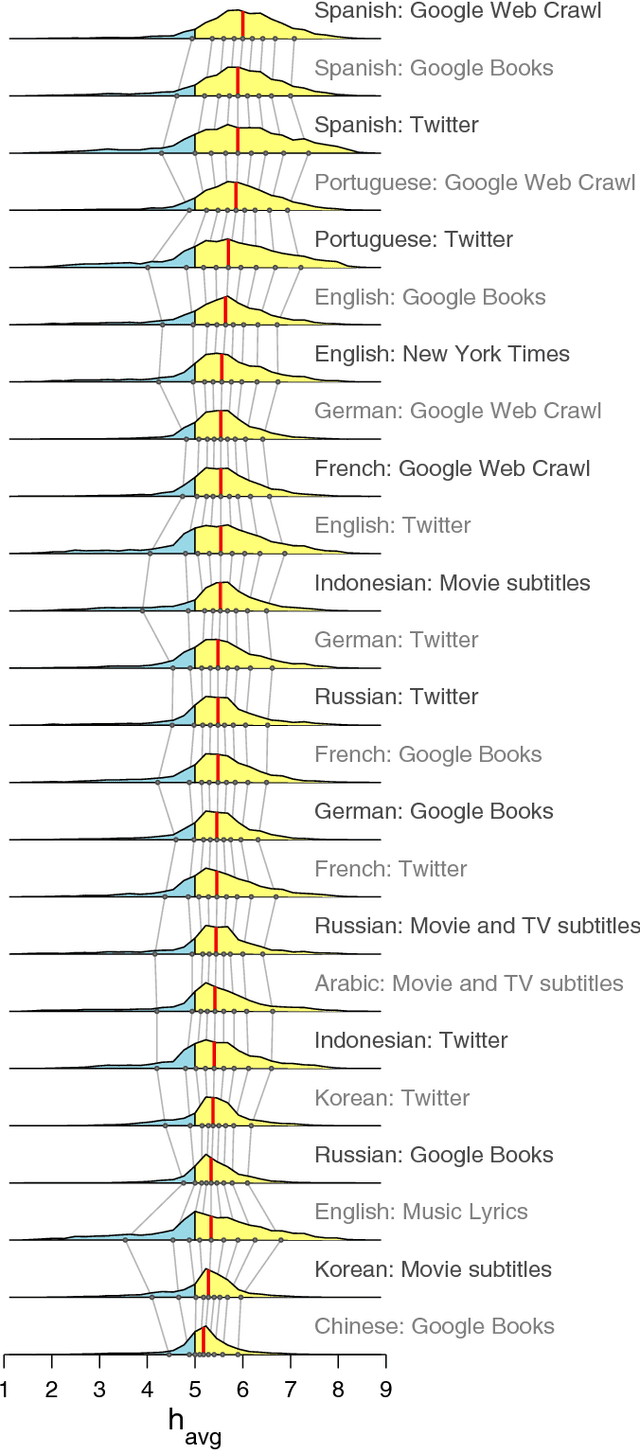
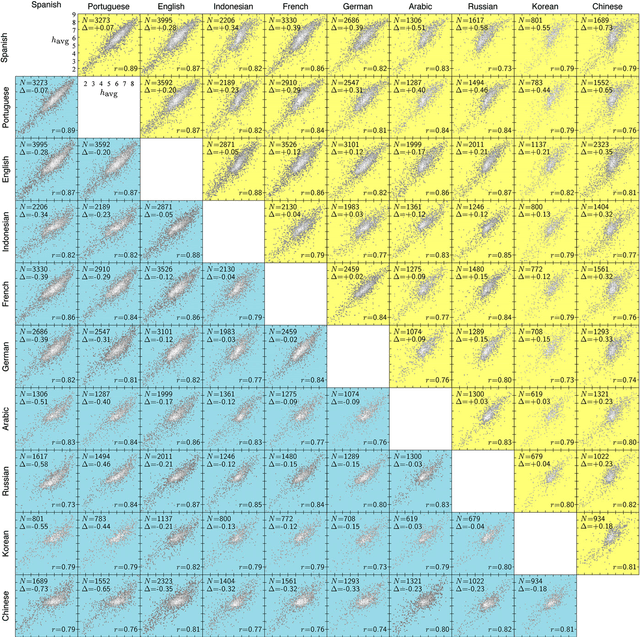
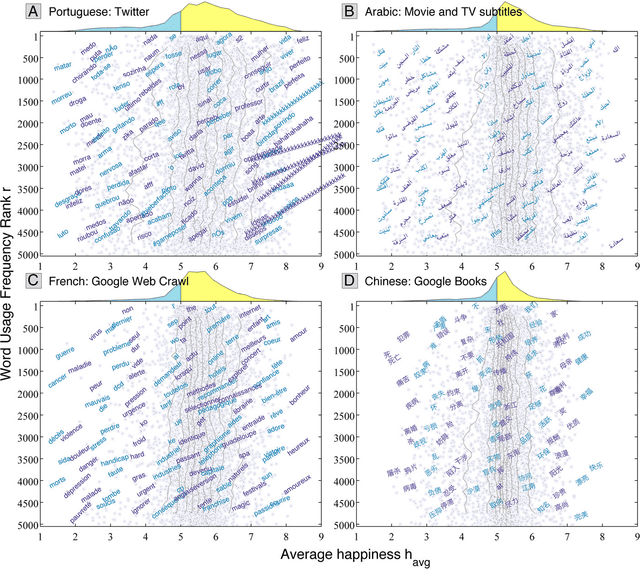
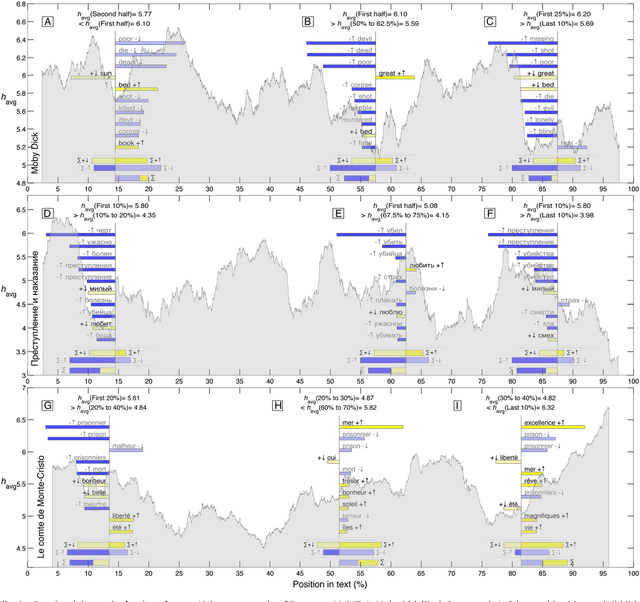
Using human evaluation of 100,000 words spread across 24 corpora in 10 languages diverse in origin and culture, we present evidence of a deep imprint of human sociality in language, observing that (1) the words of natural human language possess a universal positivity bias; (2) the estimated emotional content of words is consistent between languages under translation; and (3) this positivity bias is strongly independent of frequency of word usage. Alongside these general regularities, we describe inter-language variations in the emotional spectrum of languages which allow us to rank corpora. We also show how our word evaluations can be used to construct physical-like instruments for both real-time and offline measurement of the emotional content of large-scale texts.