 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptation Algorithms for Speech Recognition: An Overview
Aug 14, 2020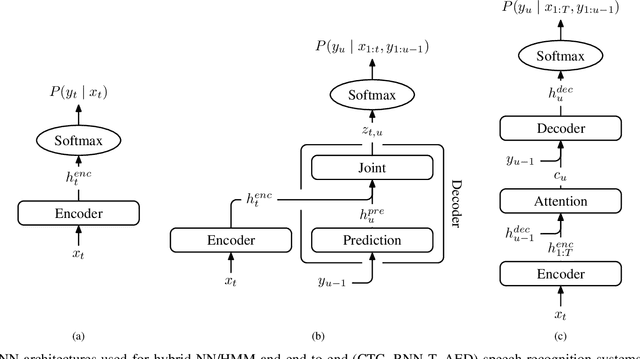
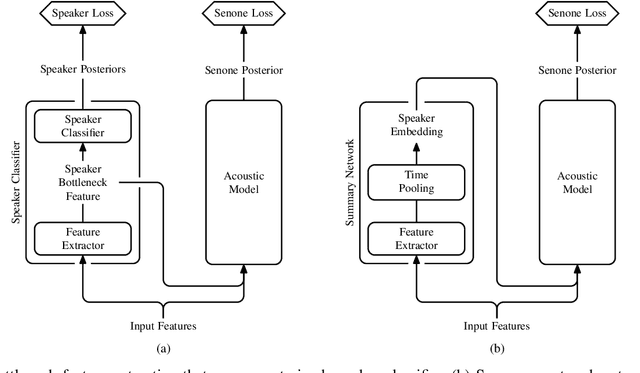
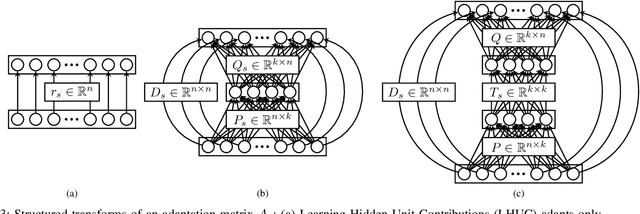
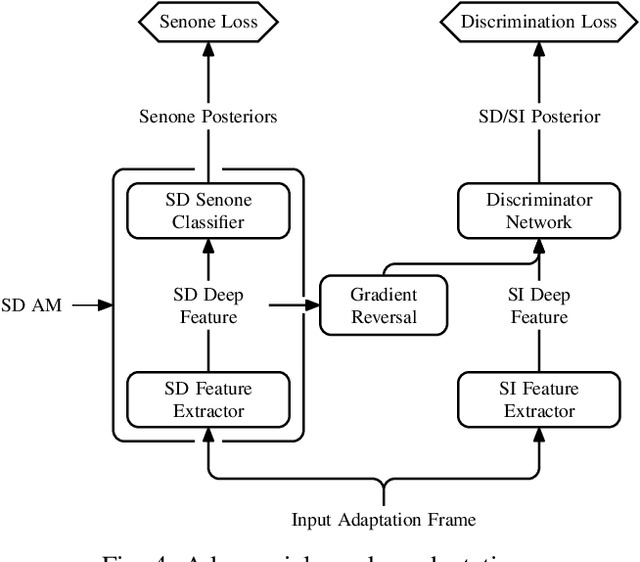
We present a structured overview of adaptation algorithms for neural network-based speech recognition, considering both hybrid hidden Markov model / neural network systems and end-to-end neural network systems, with a focus on speaker adaptation, domain adaptation, and accent adaptation. The overview characterizes adaptation algorithms as based on embeddings, model parameter adaptation, or data augmentation. We present a meta-analysis of the performance of speech recognition adaptation algorithms, based on relative error rate reductions as reported in the literature.
When Can Self-Attention Be Replaced by Feed Forward Layers?
May 28, 2020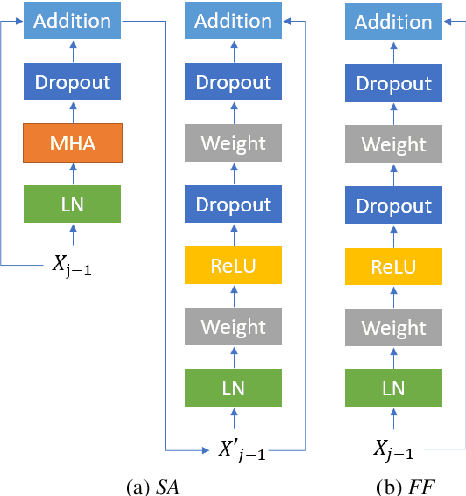
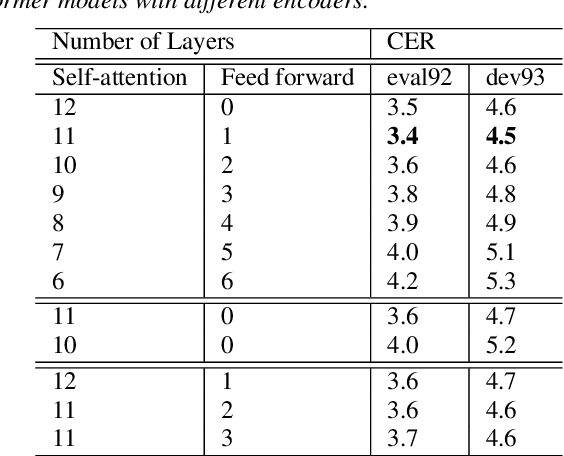

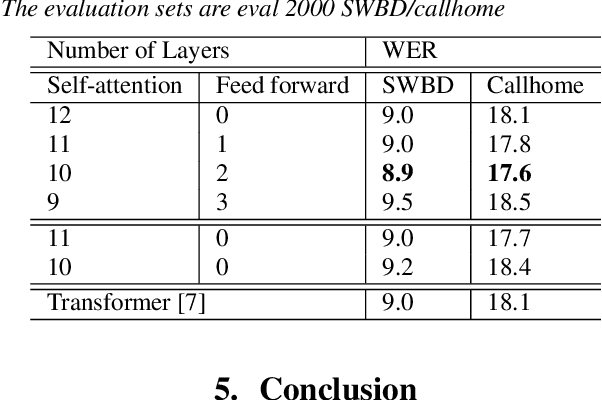
Recently, self-attention models such as Transformers have given competitive results compared to recurrent neural network systems in speech recognition. The key factor for the outstanding performance of self-attention models is their ability to capture temporal relationships without being limited by the distance between two related events. However, we note that the range of the learned context progressively increases from the lower to upper self-attention layers, whilst acoustic events often happen within short time spans in a left-to-right order. This leads to a question: for speech recognition, is a global view of the entire sequence still important for the upper self-attention layers in the encoder of Transformers? To investigate this, we replace these self-attention layers with feed forward layers. In our speech recognition experiments (Wall Street Journal and Switchboard), we indeed observe an interesting result: replacing the upper self-attention layers in the encoder with feed forward layers leads to no performance drop, and even minor gains. Our experiments offer insights to how self-attention layers process the speech signal, leading to the conclusion that the lower self-attention layers of the encoder encode a sufficiently wide range of inputs, hence learning further contextual information in the upper layers is unnecessary.
Recognizing Characters in Art History Using Deep Learning
Apr 01, 2020


In the field of Art History, images of artworks and their contexts are core to understanding the underlying semantic information. However, the highly complex and sophisticated representation of these artworks makes it difficult, even for the experts, to analyze the scene. From the computer vision perspective, the task of analyzing such artworks can be divided into sub-problems by taking a bottom-up approach. In this paper, we focus on the problem of recognizing the characters in Art History. From the iconography of $Annunciation$ $of$ $the$ $Lord$ (Figure 1), we consider the representation of the main protagonists, $Mary$ and $Gabriel$, across different artworks and styles. We investigate and present the findings of training a character classifier on features extracted from their face images. The limitations of this method, and the inherent ambiguity in the representation of $Gabriel$, motivated us to consider their bodies (a bigger context) to analyze in order to recognize the characters. Convolutional Neural Networks (CNN) trained on the bodies of $Mary$ and $Gabriel$ are able to learn person related features and ultimately improve the performance of character recognition. We introduce a new technique that generates more data with similar styles, effectively creating data in the similar domain. We present experiments and analysis on three different models and show that the model trained on domain related data gives the best performance for recognizing character. Additionally, we analyze the localized image regions for the network predictions. Code is open-sourced and available at https://github.com/prathmeshrmadhu/recognize_characters_art_history and the link to the published peer-reviewed article is https://dl.acm.org/citation.cfm?id=3357242.
DropClass and DropAdapt: Dropping classes for deep speaker representation learning
Feb 02, 2020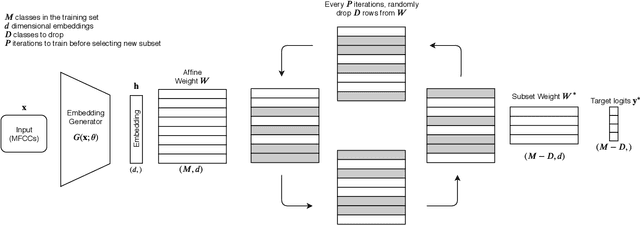
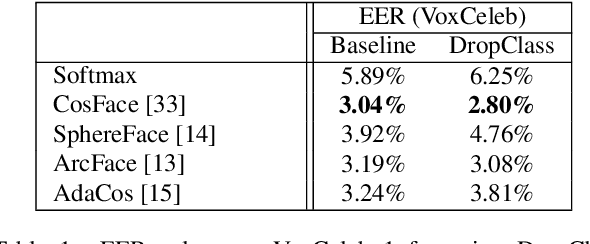
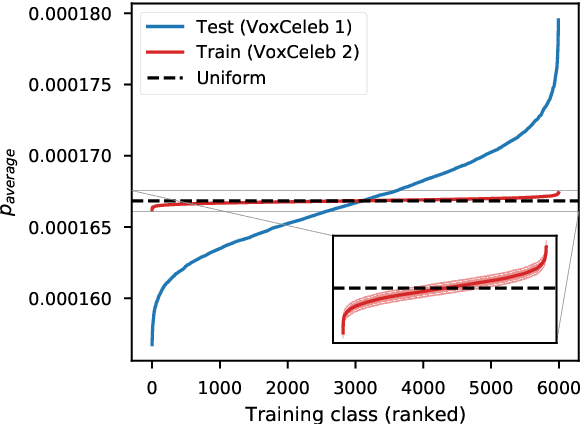
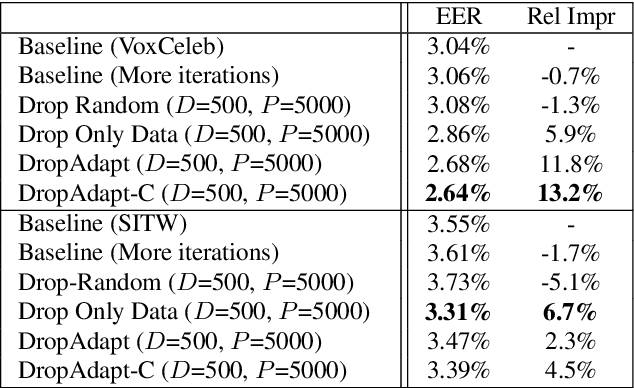
Many recent works on deep speaker embeddings train their feature extraction networks on large classification tasks, distinguishing between all speakers in a training set. Empirically, this has been shown to produce speaker-discriminative embeddings, even for unseen speakers. However, it is not clear that this is the optimal means of training embeddings that generalize well. This work proposes two approaches to learning embeddings, based on the notion of dropping classes during training. We demonstrate that both approaches can yield performance gains in speaker verification tasks. The first proposed method, DropClass, works via periodically dropping a random subset of classes from the training data and the output layer throughout training, resulting in a feature extractor trained on many different classification tasks. Combined with an additive angular margin loss, this method can yield a 7.9% relative improvement in equal error rate (EER) over a strong baseline on VoxCeleb. The second proposed method, DropAdapt, is a means of adapting a trained model to a set of enrolment speakers in an unsupervised manner. This is performed by fine-tuning a model on only those classes which produce high probability predictions when the enrolment speakers are used as input, again also dropping the relevant rows from the output layer. This method yields a large 13.2% relative improvement in EER on VoxCeleb. The code for this paper has been made publicly available.
Multi-scale Octave Convolutions for Robust Speech Recognition
Oct 31, 2019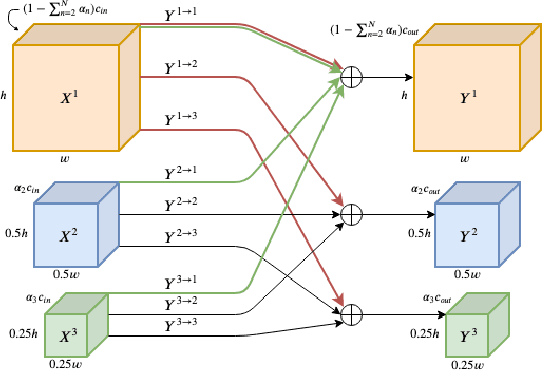
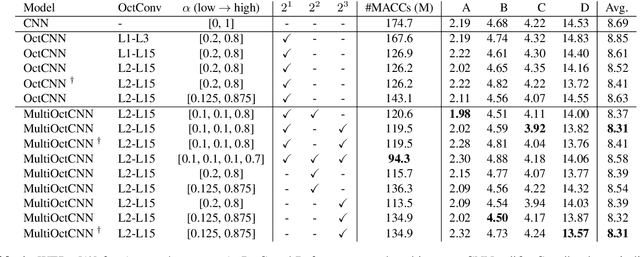
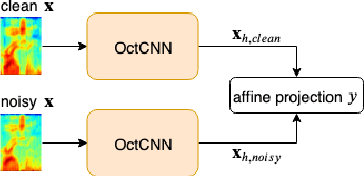
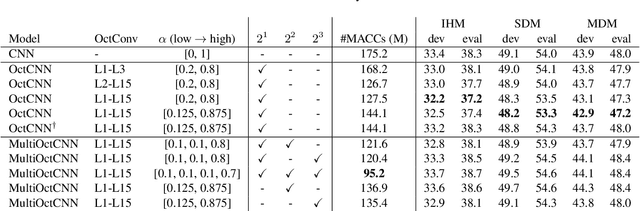
We propose a multi-scale octave convolution layer to learn robust speech representations efficiently. Octave convolutions were introduced by Chen et al [1] in the computer vision field to reduce the spatial redundancy of the feature maps by decomposing the output of a convolutional layer into feature maps at two different spatial resolutions, one octave apart. This approach improved the efficiency as well as the accuracy of the CNN models. The accuracy gain was attributed to the enlargement of the receptive field in the original input space. We argue that octave convolutions likewise improve the robustness of learned representations due to the use of average pooling in the lower resolution group, acting as a low-pass filter. We test this hypothesis by evaluating on two noisy speech corpora - Aurora-4 and AMI. We extend the octave convolution concept to multiple resolution groups and multiple octaves. To evaluate the robustness of the inferred representations, we report the similarity between clean and noisy encodings using an affine projection loss as a proxy robustness measure. The results show that proposed method reduces the WER by up to 6.6% relative for Aurora-4 and 3.6% for AMI, while improving the computational efficiency of the CNN acoustic models.
Channel adversarial training for speaker verification and diarization
Oct 25, 2019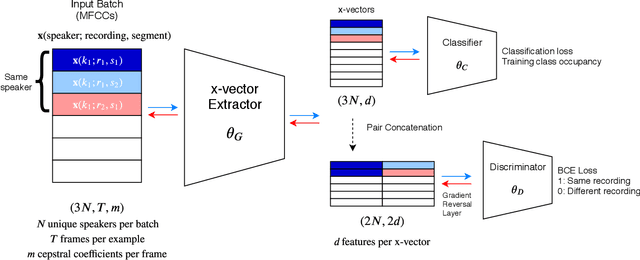
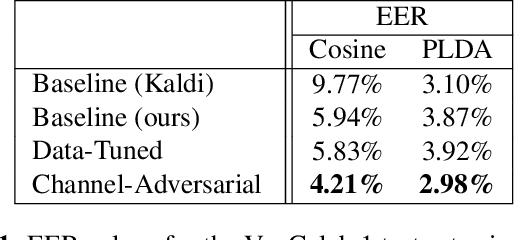
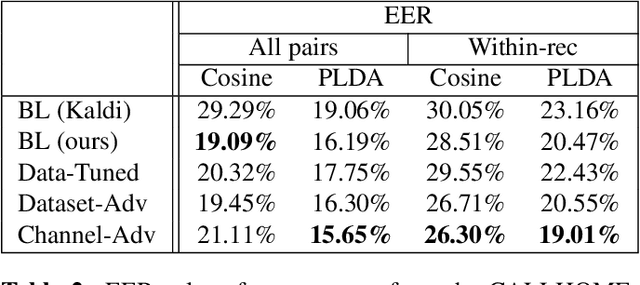
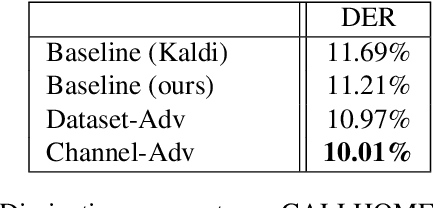
Previous work has encouraged domain-invariance in deep speaker embedding by adversarially classifying the dataset or labelled environment to which the generated features belong. We propose a training strategy which aims to produce features that are invariant at the granularity of the recording or channel, a finer grained objective than dataset- or environment-invariance. By training an adversary to predict whether pairs of same-speaker embeddings belong to the same recording in a Siamese fashion, learned features are discouraged from utilizing channel information that may be speaker discriminative during training. Experiments for verification on VoxCeleb and diarization and verification on CALLHOME show promising improvements over a strong baseline in addition to outperforming a dataset-adversarial model. The VoxCeleb model in particular performs well, achieving a $4\%$ relative improvement in EER over a Kaldi baseline, while using a similar architecture and less training data.
Speaker Adaptive Training using Model Agnostic Meta-Learning
Oct 23, 2019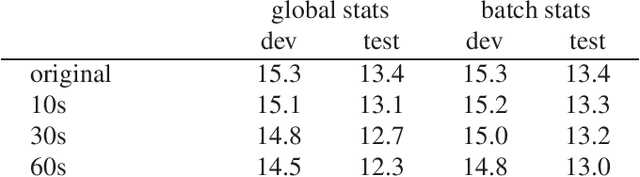


Speaker adaptive training (SAT) of neural network acoustic models learns models in a way that makes them more suitable for adaptation to test conditions. Conventionally, model-based speaker adaptive training is performed by having a set of speaker dependent parameters that are jointly optimised with speaker independent parameters in order to remove speaker variation. However, this does not scale well if all neural network weights are to be adapted to the speaker. In this paper we formulate speaker adaptive training as a meta-learning task, in which an adaptation process using gradient descent is encoded directly into the training of the model. We compare our approach with test-only adaptation of a standard baseline model and a SAT-LHUC model with a learned speaker adaptation schedule and demonstrate that the meta-learning approach achieves comparable results.
Acoustic Model Adaptation from Raw Waveforms with SincNet
Sep 30, 2019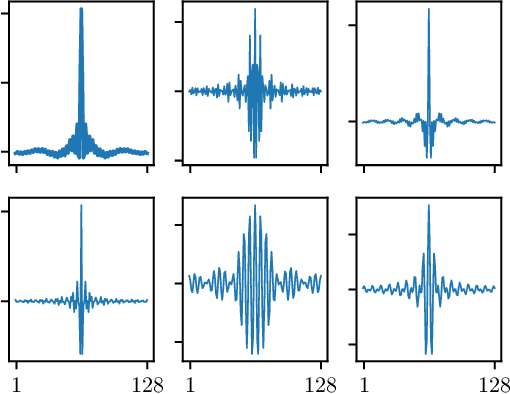
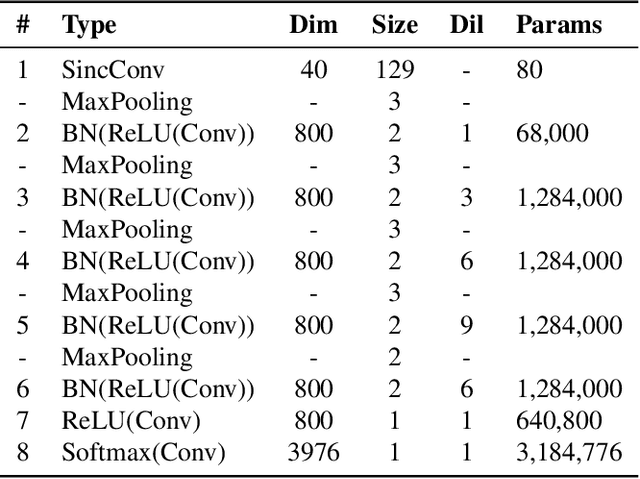
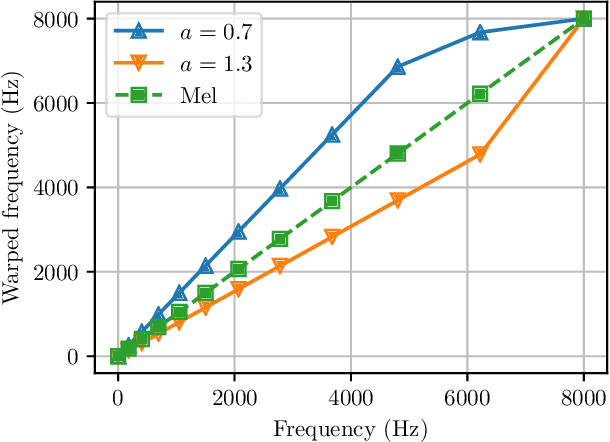
Raw waveform acoustic modelling has recently gained interest due to neural networks' ability to learn feature extraction, and the potential for finding better representations for a given scenario than hand-crafted features. SincNet has been proposed to reduce the number of parameters required in raw-waveform modelling, by restricting the filter functions, rather than having to learn every tap of each filter. We study the adaptation of the SincNet filter parameters from adults' to children's speech, and show that the parameterisation of the SincNet layer is well suited for adaptation in practice: we can efficiently adapt with a very small number of parameters, producing error rates comparable to techniques using orders of magnitude more parameters.
Embeddings for DNN speaker adaptive training
Sep 30, 2019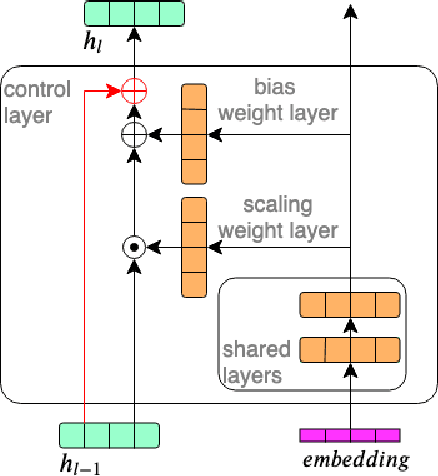
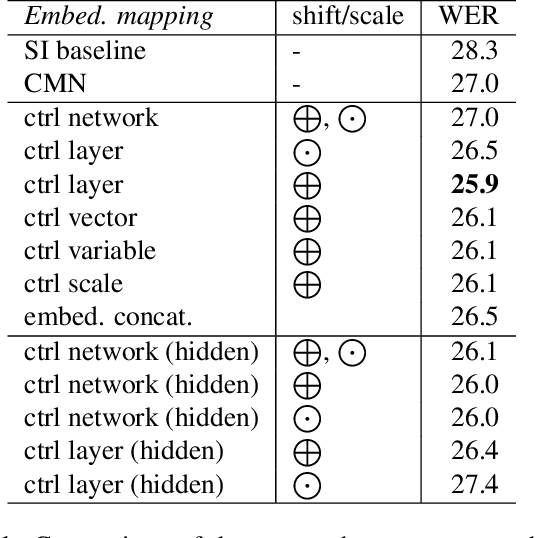
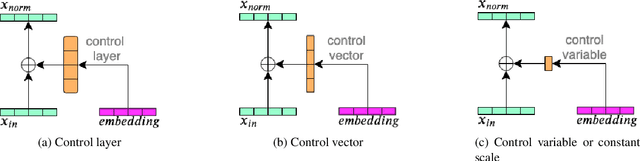
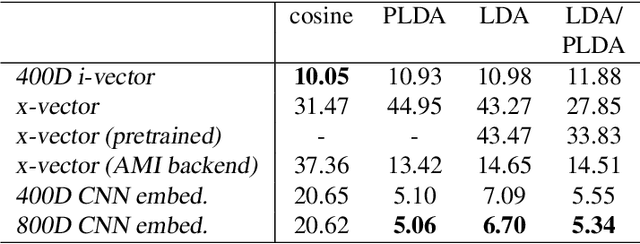
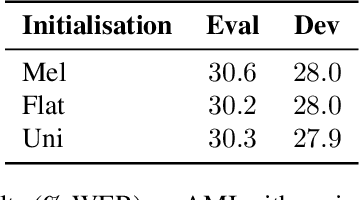
In this work, we investigate the use of embeddings for speaker-adaptive training of DNNs (DNN-SAT) focusing on a small amount of adaptation data per speaker. DNN-SAT can be viewed as learning a mapping from each embedding to transformation parameters that are applied to the shared parameters of the DNN. We investigate different approaches to applying these transformations, and find that with a good training strategy, a multi-layer adaptation network applied to all hidden layers is no more effective than a single linear layer acting on the embeddings to transform the input features. In the second part of our work, we evaluate different embeddings (i-vectors, x-vectors and deep CNN embeddings) in an additional speaker recognition task in order to gain insight into what should characterize an embedding for DNN-SAT. We find the performance for speaker recognition of a given representation is not correlated with its ASR performance; in fact, ability to capture more speech attributes than just speaker identity was the most important characteristic of the embeddings for efficient DNN-SAT ASR. Our best models achieved relative WER gains of 4% and 9% over DNN baselines using speaker-level cepstral mean normalisation (CMN), and a fully speaker-independent model, respectively.
Lattice-Based Unsupervised Test-Time Adaptation of Neural Network Acoustic Models
Jun 27, 2019



Acoustic model adaptation to unseen test recordings aims to reduce the mismatch between training and testing conditions. Most adaptation schemes for neural network models require the use of an initial one-best transcription for the test data, generated by an unadapted model, in order to estimate the adaptation transform. It has been found that adaptation methods using discriminative objective functions - such as cross-entropy loss - often require careful regularisation to avoid over-fitting to errors in the one-best transcriptions. In this paper we solve this problem by performing discriminative adaptation using lattices obtained from a first pass decoding, an approach that can be readily integrated into the lattice-free maximum mutual information (LF-MMI) framework. We investigate this approach on three transcription tasks of varying difficulty: TED talks, multi-genre broadcast (MGB) and a low-resource language (Somali). We find that our proposed approach enables many more parameters to be adapted without over-fitting being observed, and is successful even when the initial transcription has a WER in excess of 50%.