 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnriching Video Captions With Contextual Text
Jul 29, 2020
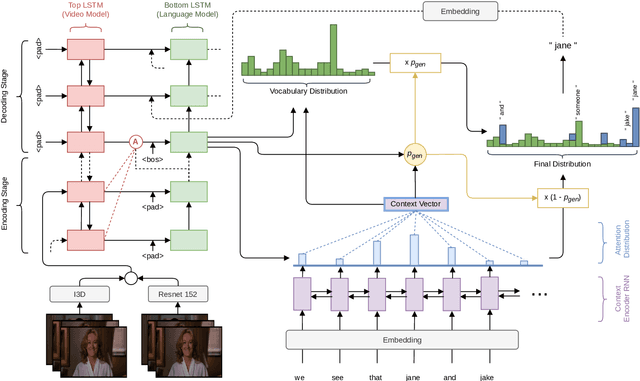
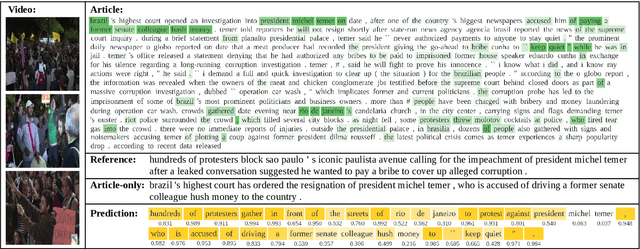
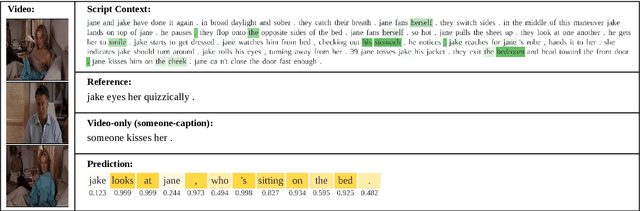
Understanding video content and generating caption with context is an important and challenging task. Unlike prior methods that typically attempt to generate generic video captions without context, our architecture contextualizes captioning by infusing extracted information from relevant text data. We propose an end-to-end sequence-to-sequence model which generates video captions based on visual input, and mines relevant knowledge such as names and locations from contextual text. In contrast to previous approaches, we do not preprocess the text further, and let the model directly learn to attend over it. Guided by the visual input, the model is able to copy words from the contextual text via a pointer-generator network, allowing to produce more specific video captions. We show competitive performance on the News Video Dataset and, through ablation studies, validate the efficacy of contextual video captioning as well as individual design choices in our model architecture.
Neural Sequential Phrase Grounding (SeqGROUND)
Mar 18, 2019
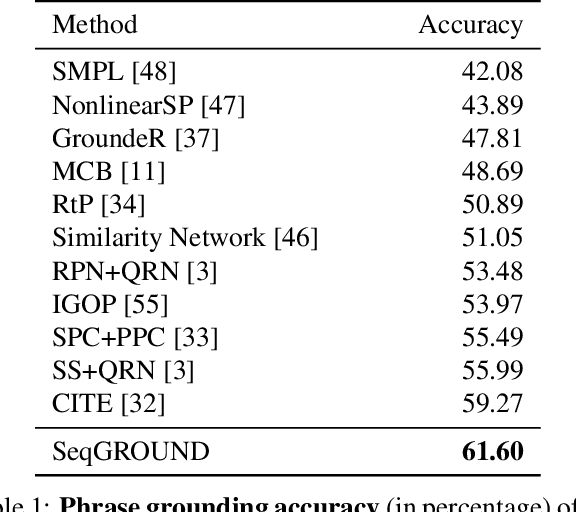
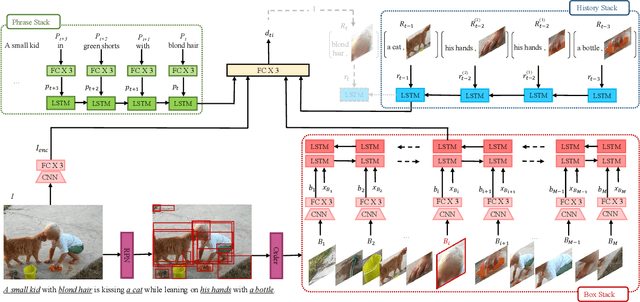
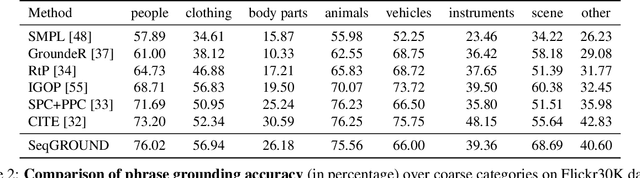
We propose an end-to-end approach for phrase grounding in images. Unlike prior methods that typically attempt to ground each phrase independently by building an image-text embedding, our architecture formulates grounding of multiple phrases as a sequential and contextual process. Specifically, we encode region proposals and all phrases into two stacks of LSTM cells, along with so-far grounded phrase-region pairs. These LSTM stacks collectively capture context for grounding of the next phrase. The resulting architecture, which we call SeqGROUND, supports many-to-many matching by allowing an image region to be matched to multiple phrases and vice versa. We show competitive performance on the Flickr30K benchmark dataset and, through ablation studies, validate the efficacy of sequential grounding as well as individual design choices in our model architecture.
A Neural Multi-sequence Alignment TeCHnique (NeuMATCH)
Apr 09, 2018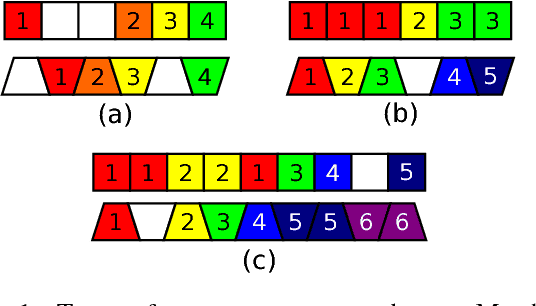


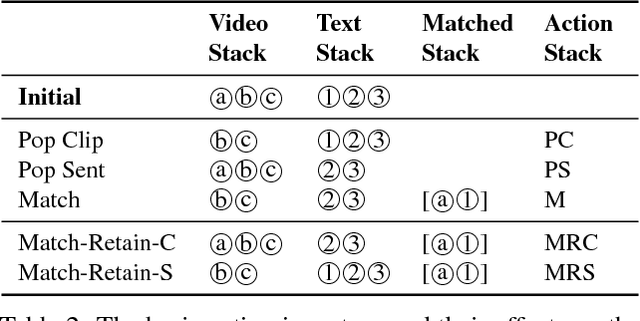
The alignment of heterogeneous sequential data (video to text) is an important and challenging problem. Standard techniques for this task, including Dynamic Time Warping (DTW) and Conditional Random Fields (CRFs), suffer from inherent drawbacks. Mainly, the Markov assumption implies that, given the immediate past, future alignment decisions are independent of further history. The separation between similarity computation and alignment decision also prevents end-to-end training. In this paper, we propose an end-to-end neural architecture where alignment actions are implemented as moving data between stacks of Long Short-term Memory (LSTM) blocks. This flexible architecture supports a large variety of alignment tasks, including one-to-one, one-to-many, skipping unmatched elements, and (with extensions) non-monotonic alignment. Extensive experiments on semi-synthetic and real datasets show that our algorithm outperforms state-of-the-art baselines.