 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs an Image Also Worth 16x16=256 Superpixels? A Framework for Attentional Image Classification
May 26, 2026Superpixel-based image classification has traditionally leveraged graph neural networks (GNNs) for processing irregular image representations. Recent advances in computer vision, driven by Vision Transformers (ViTs), have introduced new paradigms in self-attentional models, surpassing convolutional neural networks (CNNs) in various tasks. However, a synergistic connection between GNNs, superpixels, and transformers remains unexplored. In this work, we propose Superpixel Transformers (SPT), a novel framework that unifies superpixel-based image classification and ViTs. SPT generalizes the Superpixel Image Classification with Graph Attention Networks (SICGAT) model and ViT to support arbitrary superpixel-based chunking strategies, connectivity graphs, and positional encodings. We introduce refinements including a multidimensional sine-cosine positional encoding and an enriched patch data structure that fully incorporates superpixel shape and color information. By testing SPT across datasets such as CIFAR10, FashionMNIST, and Imagenette, with various superpixel generation and graph connectivity strategies, we demonstrate that SPT achieves superior performance compared to previous superpixel-based GNN methods and remains competitive with ViTs. Notably, our approach addresses the limitations of SICGAT, such as information loss during pixel aggregation, and shows how constrained graph connectivity can enhance ViT performance. SPT bridges the gap between superpixel-based and transformer models, opening avenues for cross-domain generalization and future innovations in hybrid attentional frameworks, and showing that an image can also be worth $16\times16$ superpixels.
Subset-Contrastive Multi-Omics Network Embedding
Apr 15, 2025



Motivation: Network-based analyses of omics data are widely used, and while many of these methods have been adapted to single-cell scenarios, they often remain memory- and space-intensive. As a result, they are better suited to batch data or smaller datasets. Furthermore, the application of network-based methods in multi-omics often relies on similarity-based networks, which lack structurally-discrete topologies. This limitation may reduce the effectiveness of graph-based methods that were initially designed for topologies with better defined structures. Results: We propose Subset-Contrastive multi-Omics Network Embedding (SCONE), a method that employs contrastive learning techniques on large datasets through a scalable subgraph contrastive approach. By exploiting the pairwise similarity basis of many network-based omics methods, we transformed this characteristic into a strength, developing an approach that aims to achieve scalable and effective analysis. Our method demonstrates synergistic omics integration for cell type clustering in single-cell data. Additionally, we evaluate its performance in a bulk multi-omics integration scenario, where SCONE performs comparable to the state-of-the-art despite utilising limited views of the original data. We anticipate that our findings will motivate further research into the use of subset contrastive methods for omics data.
Incorporating Prior Knowledge in Deep Learning Models via Pathway Activity Autoencoders
Jun 09, 2023



Motivation: Despite advances in the computational analysis of high-throughput molecular profiling assays (e.g. transcriptomics), a dichotomy exists between methods that are simple and interpretable, and ones that are complex but with lower degree of interpretability. Furthermore, very few methods deal with trying to translate interpretability in biologically relevant terms, such as known pathway cascades. Biological pathways reflecting signalling events or metabolic conversions are Small improvements or modifications of existing algorithms will generally not be suitable, unless novel biological results have been predicted and verified. Determining which pathways are implicated in disease and incorporating such pathway data as prior knowledge may enhance predictive modelling and personalised strategies for diagnosis, treatment and prevention of disease. Results: We propose a novel prior-knowledge-based deep auto-encoding framework, PAAE, together with its accompanying generative variant, PAVAE, for RNA-seq data in cancer. Through comprehensive comparisons among various learning models, we show that, despite having access to a smaller set of features, our PAAE and PAVAE models achieve better out-of-set reconstruction results compared to common methodologies. Furthermore, we compare our model with equivalent baselines on a classification task and show that they achieve better results than models which have access to the full input gene set. Another result is that using vanilla variational frameworks might negatively impact both reconstruction outputs as well as classification performance. Finally, our work directly contributes by providing comprehensive interpretability analyses on our models on top of improving prognostication for translational medicine.
Multi-Omic Data Integration and Feature Selection for Survival-based Patient Stratification via Supervised Concrete Autoencoders
Jun 27, 2022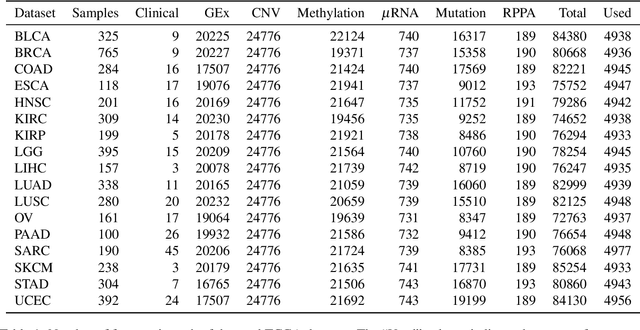



Cancer is a complex disease with significant social and economic impact. Advancements in high-throughput molecular assays and the reduced cost for performing high-quality multi-omics measurements have fuelled insights through machine learning . Previous studies have shown promise on using multiple omic layers to predict survival and stratify cancer patients. In this paper, we developed a Supervised Autoencoder (SAE) model for survival-based multi-omic integration which improves upon previous work, and report a Concrete Supervised Autoencoder model (CSAE), which uses feature selection to jointly reconstruct the input features as well as predict survival. Our experiments show that our models outperform or are on par with some of the most commonly used baselines, while either providing a better survival separation (SAE) or being more interpretable (CSAE). We also perform a feature selection stability analysis on our models and notice that there is a power-law relationship with features which are commonly associated with survival. The code for this project is available at: https://github.com/phcavelar/coxae